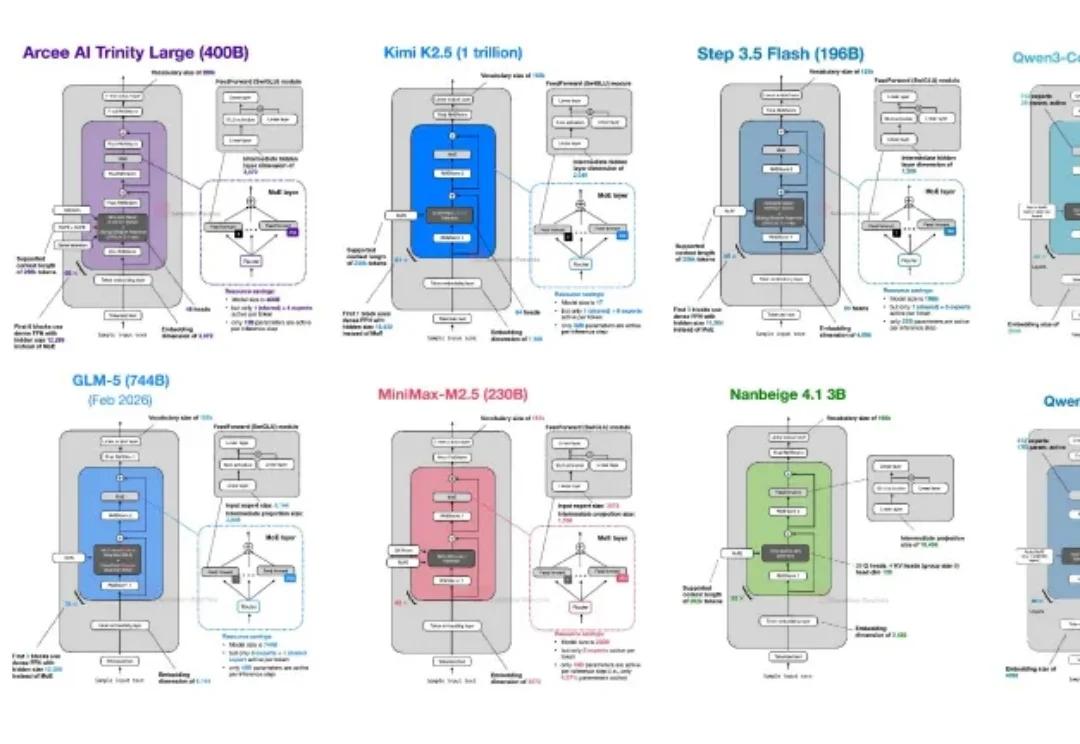
复旦北大联合美团LongCat提出TDAR:用“粗思考,细求证”破解Block Diffusion的速度精度悖论
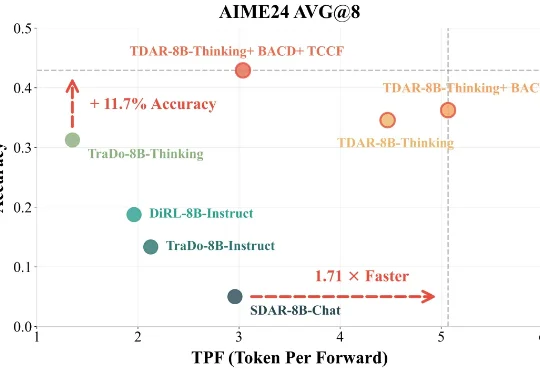
复旦北大联合美团LongCat提出TDAR:用“粗思考,细求证”破解Block Diffusion的速度精度悖论近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码
来自主题: AI技术研报
7755 点击 2026-03-14 08:39