
看遍奥斯卡后,VLM达到电影摄影理解新SOTA|上海AI Lab开源
看遍奥斯卡后,VLM达到电影摄影理解新SOTA|上海AI Lab开源当前最强大的视觉语言模型(VLMs)虽然能“看图识物”,但在理解电影方面还不够“聪明”。
来自主题: AI技术研报
10281 点击 2025-07-17 10:19
 搜索
搜索
当前最强大的视觉语言模型(VLMs)虽然能“看图识物”,但在理解电影方面还不够“聪明”。

最强具身大脑,宝座易主!在10项评测中,国产RoboBrain 2.0全面超越GPT-4o。这次,智源研究院开源了具身大脑RoboBrain 2.0 32B版本以及跨本体大小脑协同框架RoboOS 2.0单机版。不仅问鼎评测基准SOTA,还成功刷新跨本体多机协作技术范式!
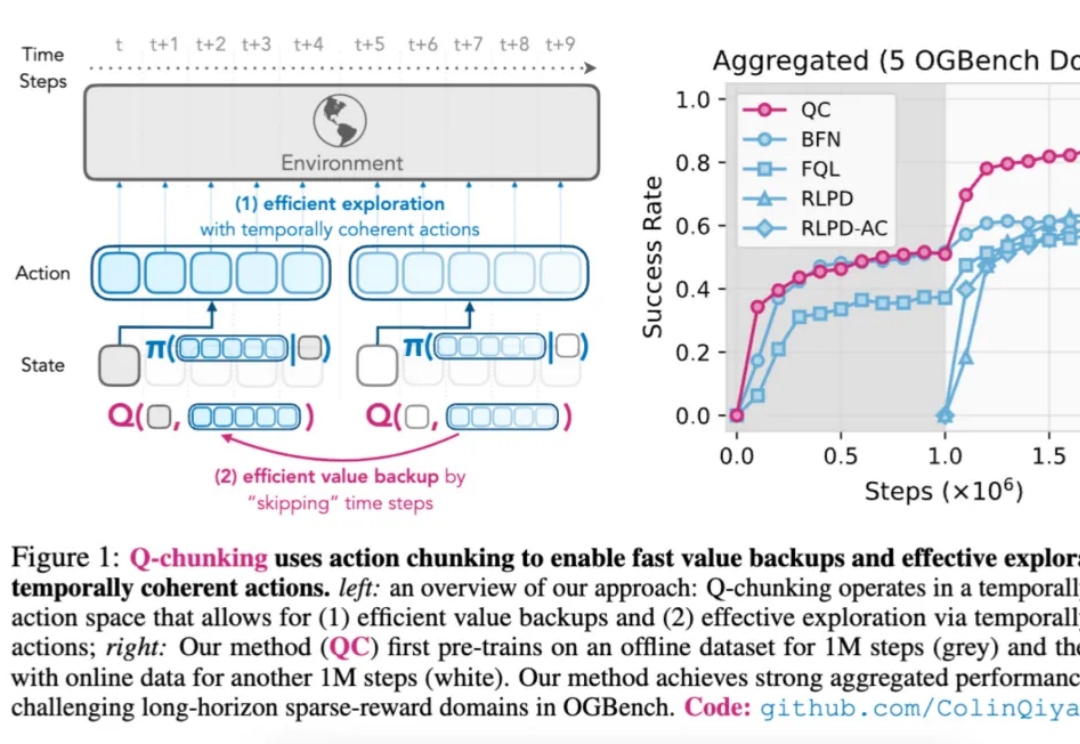
如今,强化学习(Reinforcement Learning,RL)在多个领域已取得显著成果。
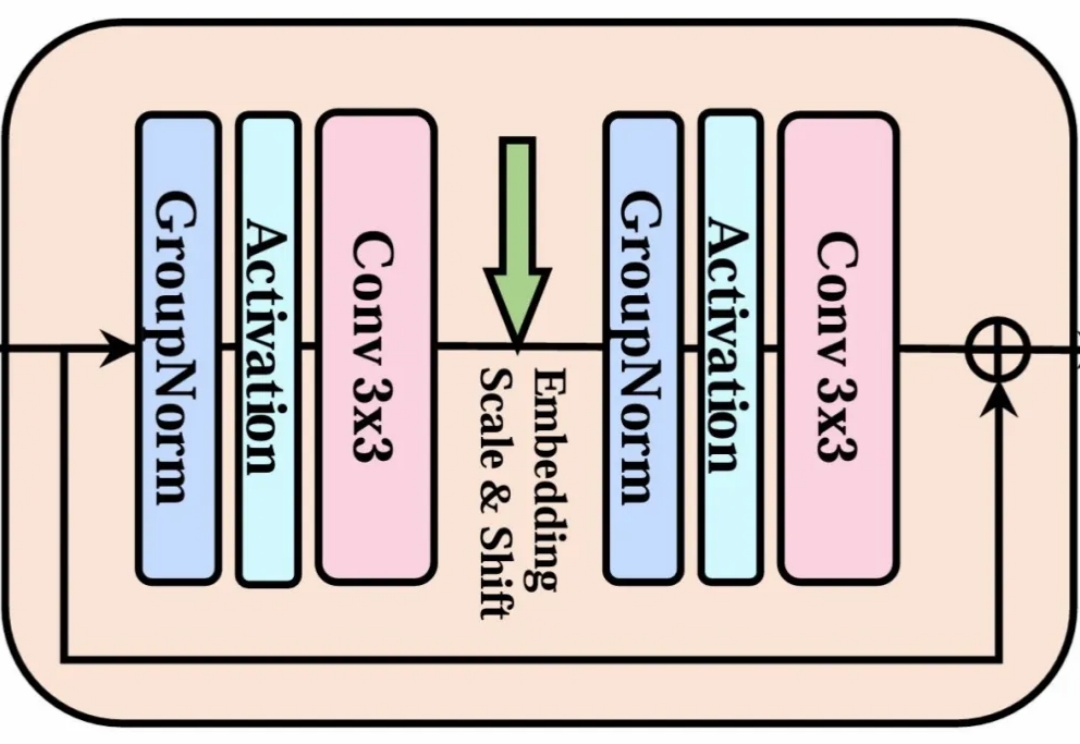
当整个 AI 视觉生成领域都在 Transformer 架构上「卷生卷死」时,一项来自北大、北邮和华为的最新研究却反其道而行之,重新审视了深度学习中最基础、最经典的模块——3x3 卷积。
今日,昆仑万维重磅开源多模态推理模型Skywork-R1V 3.0,这是其迄今最强多模态推理模型,参数规模为38B,在多个多模态推理基准测试中取得了开源最佳(SOTA)性能。
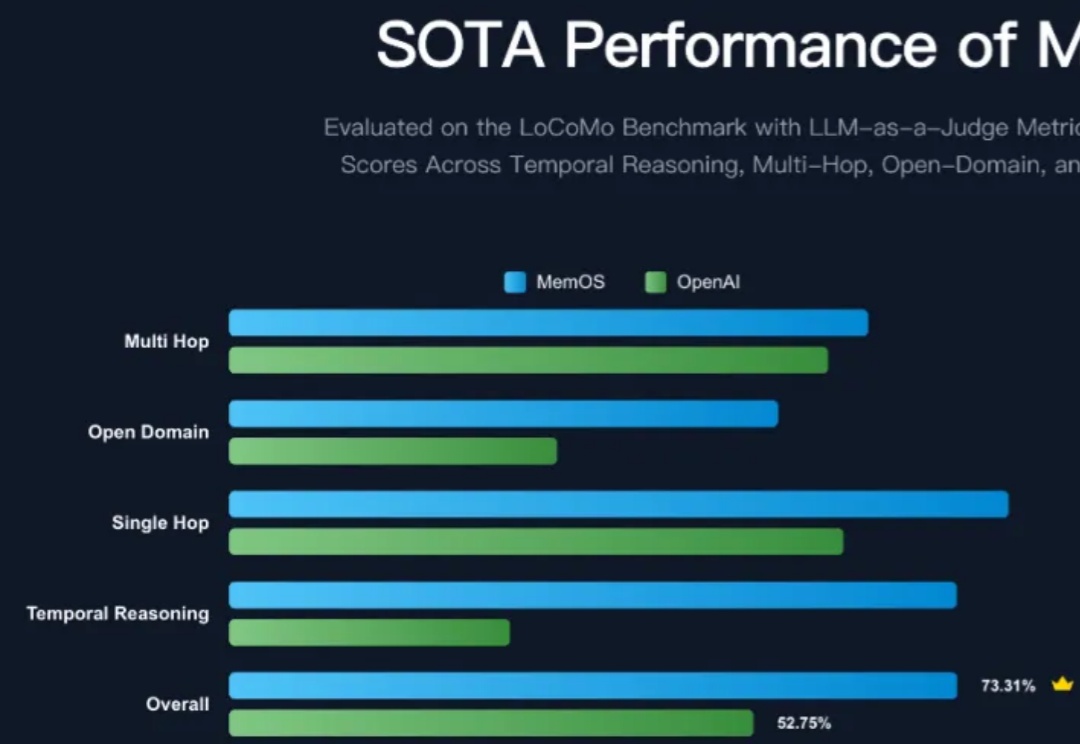
大模型记忆管理和优化框架是当前各大厂商争相优化的热点方向,MemOS 相比现有 OpenAI 的全局记忆在大模型记忆评测集上呈现出显著的提升,平均准确性提升超过 38.97%,Tokens 的开销进一步降低 60.95%,一举登顶记忆管理的 SOTA 框架,特别是在考验框架时序建模与检索能力的时序推理任务上,提升比例更是达到了 159%,相当震撼!

Skywork-Reward-V2全新发布!巧妙构建超高质量的千万级人类偏好样本,刷新七大评测基准SOTA表现。8款模型覆盖6亿至80亿参数,小体积也能媲美大模型性能。
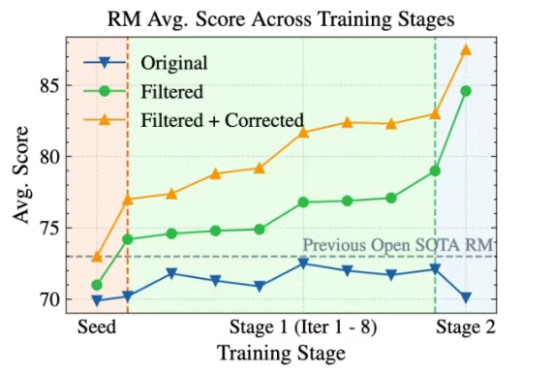
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。 基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。
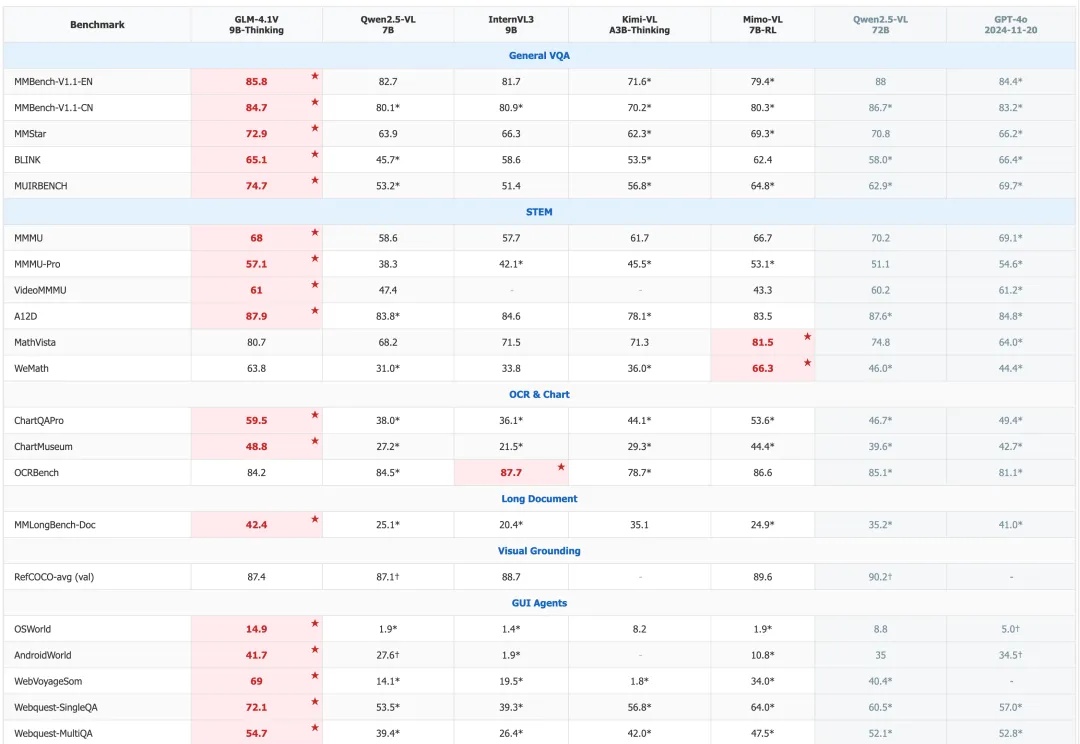
如果一个视觉语言模型(VLM)只会“看”,那真的是已经不够看的了。
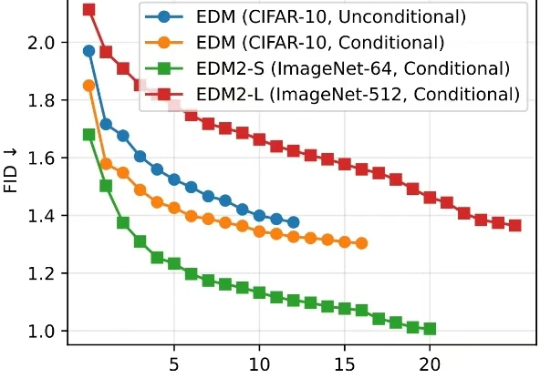
清华大学朱军教授团队与 NVIDIA Deep Imagination 研究组联合提出一种全新的视觉生成模型优化范式 —— 直接判别优化(DDO)。