
不打榜的美国开源新王Inkling:975B原生多模态、仅用 1/3 Token 追平英伟达
不打榜的美国开源新王Inkling:975B原生多模态、仅用 1/3 Token 追平英伟达时至今日,全球大模型格局已成定数,还有必要耗费巨资从零开始训练一个新模型吗?
来自主题: AI资讯
10401 点击 2026-07-16 15:19
 搜索
搜索
时至今日,全球大模型格局已成定数,还有必要耗费巨资从零开始训练一个新模型吗?
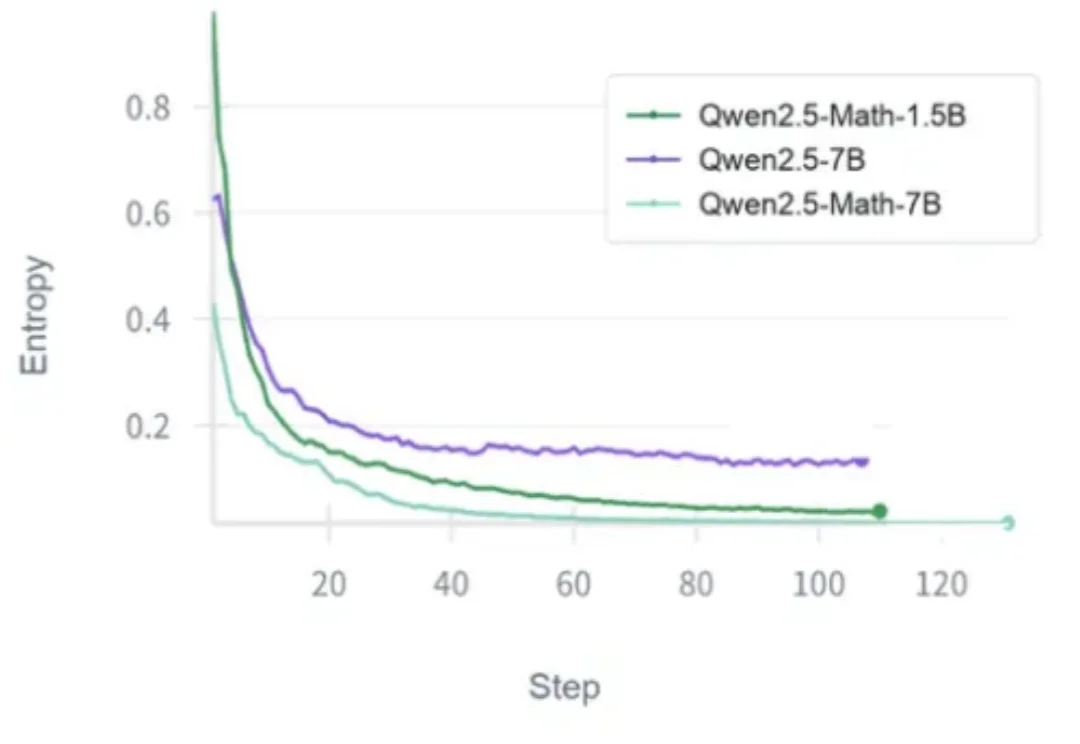
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards,RLVR)正在成为大模型后训练的关键技术。数学题能判对错,代码能跑测试,可验证奖励让大模型可以通过强化学习持续提升推理能力。

推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
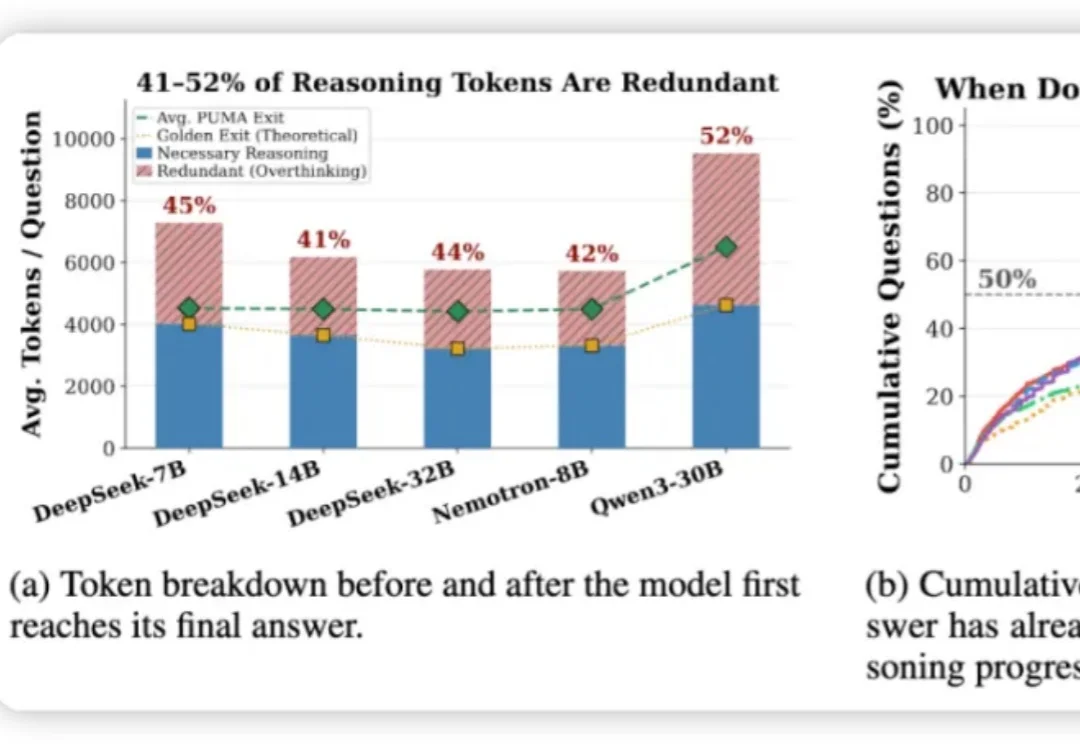
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
一笔融资进入我们视野——今日(7月13日),趋境科技A轮融资浮出水面,由河南投资集团汇融基金重磅领投,真知资本、尚势资本、星连资本、上海国方创新、弘晖基金、华控基金、杭州福成等老股东继续超额增投。

“购买使用AI时,钱可能要付两遍!”
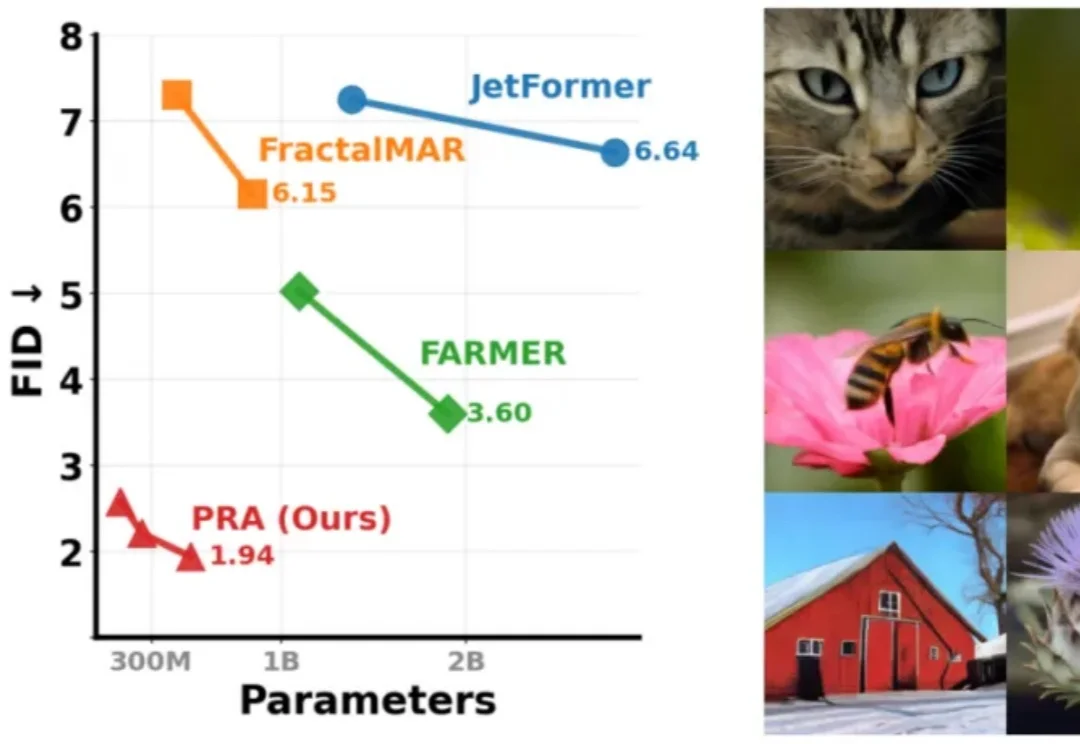
过去几年,扩散模型几乎定义了高质量图像生成:从随机噪声出发,经过多轮迭代,逐步 “雕刻” 出一张图像。但随着大语言模型席卷人工智能领域,另一条路线正迅速走到舞台中央 —— 图像,能否也像语言一样,通过自回归方式逐步生成?

AI基础设施的核心任务,已经从支撑大模型推理,转向支撑海量智能体的规模化运行与高质量Token的持续生产。
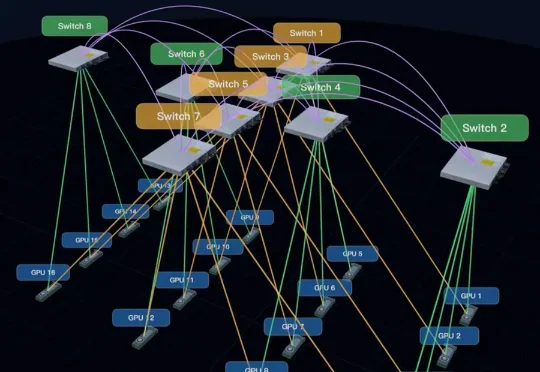
一家推翻传统网络架构的清华系创业公司,联合智谱、清华大学推出了全新的网络架构ZCube,能提升推理算力集群15%的Token产量,还能砍下约33%的网络硬件成本。近日,驭驯网络已完成智谱独家领投的数千万元融资,源合资本担任长期财务顾问。
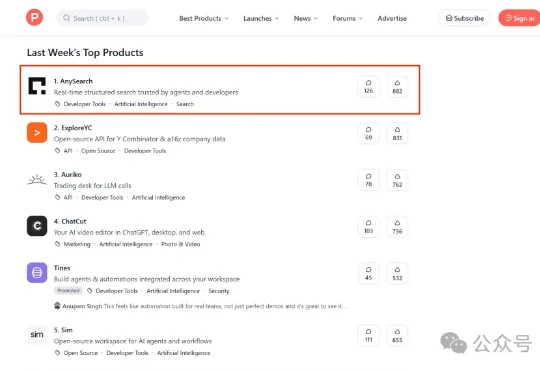
本期Product Hunt周榜Top 1出自中国团队,AnySearch——一款AI搜索产品。过去一年,PH榜一的位置被Agent、AI IDE、大模型轮番占据,几乎没见过搜索类产品的影子。就是因为在全球开发者眼里,普通AI搜索已经很难突围了。