
刚刚,中国AI交卷了!不加一张卡,暴省数百万
刚刚,中国AI交卷了!不加一张卡,暴省数百万五千名工程师,四个月,把Uber一整年的AI预算烧成了灰。
来自主题: AI资讯
8926 点击 2026-07-22 10:09
 搜索
搜索
五千名工程师,四个月,把Uber一整年的AI预算烧成了灰。

“「出海四巨头」智谱、Kimi、千问......谁最受外企欢迎? ” 作者丨胡清文 编辑丨徐晓飞 去年这个时候,硅谷讨论的还是中国模型能不能打。但在今年,这个问题已经被一组数据碾过。 OpenRout

就在今年的WAIC上,无问芯穹一口气亮出了「前店后厂一中心」,一整套完整的Agentic Infra战略布局:算力集散中心(一中心):Agentic Infra自主式基础设施平台;Token工厂(后厂):Agentic MaaS大模型服务平台;

“芯片的定价权越强,模型和应用公司的成本刚性就越难消解。” 当下,仅豆包一家大模型的日均Token调用量就已突破180万亿;国家数据局的统计显示,全国日均调用量在今年3月已超过140万亿——无论从哪个口径衡量,这都是一条两年内从“近乎为零”飙涨超千倍的曲线。
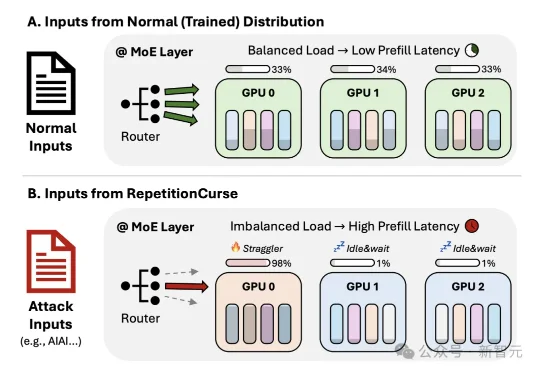
来自港科大的研究团队提出了RepetitionCurse,这是一种针对MoE大模型服务的黑盒压力测试方法。它不需要模型权重,不需要梯度,也不需要知道后端专家如何部署,只利用高度重复的输入模式,就能诱导专家路由把大量token路由到同一小批专家上。

Kimi K3 是一个 2.8 万亿参数模型,基于 KDA 混合线性注意力机制(Kimi Delta Attention)和注意力残差(Attention Residuals)技术构建,原生支持视觉理解,并拥有 100 万 token 上下文窗口。它是全球首个开源的 3 万亿级别模型,面向长程编程、知识工作和推理等前沿智能场景而设计。

这便是中国电信人工智能研究院(TeleAI),刚刚在WAIC 2026提出的新技术路线;其背后这套融合AI、通信和网络的技术体系,则是智传网(AI Flow)。就在此次发布前一天,智传网(AI Flow)还拿下了WAIC大会最高奖项卓越人工智能引领者奖(SAIL)中的赋能(Applicative)奖。

50多个智算中心,超过1000 EFLOPS的智能算力规模,平均利用效率却远远没有跑满。是石给出的解法,叫拓元(Vectron),一座国产Token优化工厂。是石科技依托国家级计算中心工程经验积淀,持续投入大规模集群研发,建设万卡级国产大集群,持续稳定运营,优化推理效率,构筑了深厚壁垒
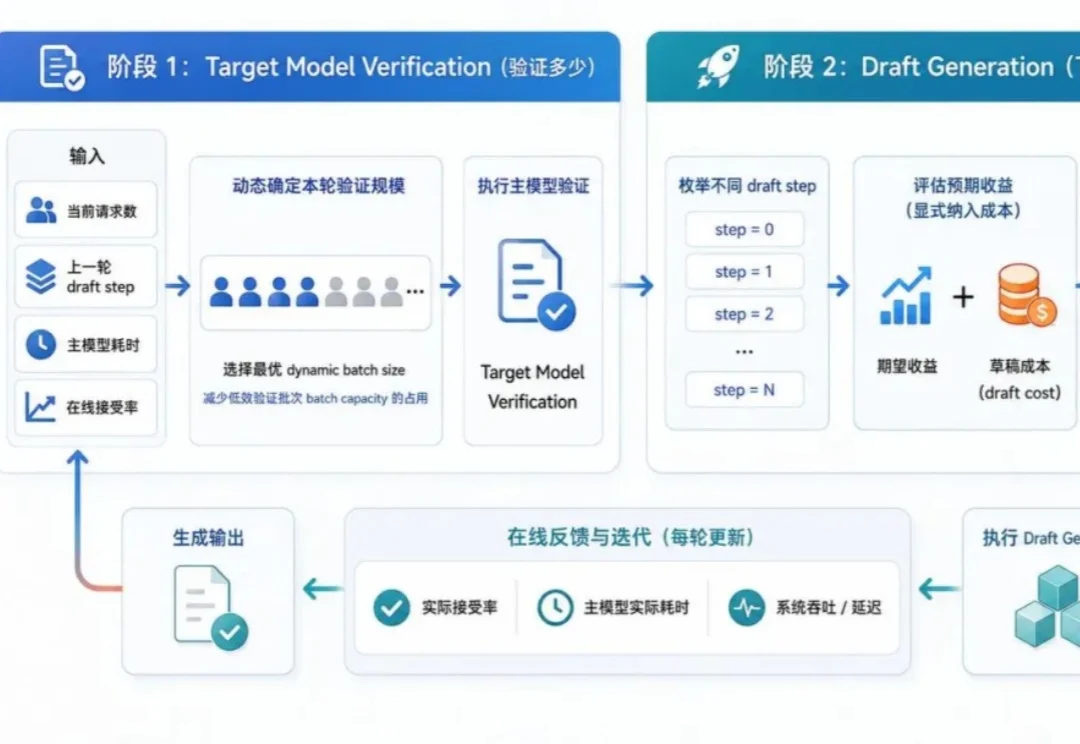
随着 DeepSeek 发布 DSpark,动态 MTP(多 Token 预测)成为了对抗高并发、提升 GPU 利用率的绝对焦点。然而,DSpark 高度绑定特定模型且需要额外训练。

7 月 16 日,月之暗面正式发布 Kimi K3:总参数量 2.8 万亿(2.8T),原生视觉理解,100 万 token 上下文,并且——开源权重。这是历史上第一个摸到 2.8 万亿参数量级的开源模型。前任"开源最大模型"的纪录保持者?也是它自己。