token羊毛|微信小程序「成长计划」:价值2万多的token,1分钟到账
token羊毛|微信小程序「成长计划」:价值2万多的token,1分钟到账昨天,腾讯混元 Hy3 正式版上线,小程序更新了「成长计划」:小程序开发者的可以获得 10 亿的文本 Token,和 10 万张生图额度→ 10 亿 token 按官方 API 价折算,约 1000~4000 块
来自主题: AI资讯
9044 点击 2026-07-07 16:58
 搜索
搜索
昨天,腾讯混元 Hy3 正式版上线,小程序更新了「成长计划」:小程序开发者的可以获得 10 亿的文本 Token,和 10 万张生图额度→ 10 亿 token 按官方 API 价折算,约 1000~4000 块
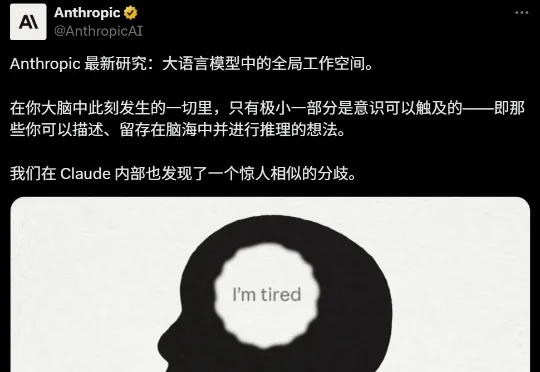
没人设计过,Claude却在学习预测下一个token时,自发长出了一个和人脑「意识」惊人相似的结构!Anthropic开源「手术刀」J-Lens,第一次读出了AI咽回肚子里的念头。
上周有个项目,让我觉得很有意思。GitHub上一个叫OpenSquilla的,发布不到一个月,Star涨到了5300多。OpenSquilla 0.4.0,定位Token-Efficient AI Agent,是一个很有效率又很有创意的智能体框架。
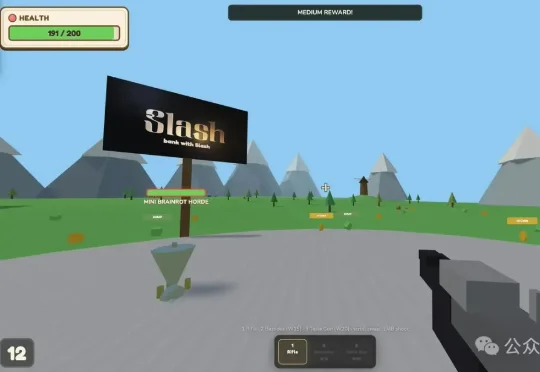
一名员工响应公司号召,一头扎进Vibe Coding的世界里,勤勤恳恳搓出了一个像素风脑腐FPS游戏。没等他心里美完,不经意瞥了一眼。我去,这玩意儿花了我81267美元的token(折合人民币55万元)???
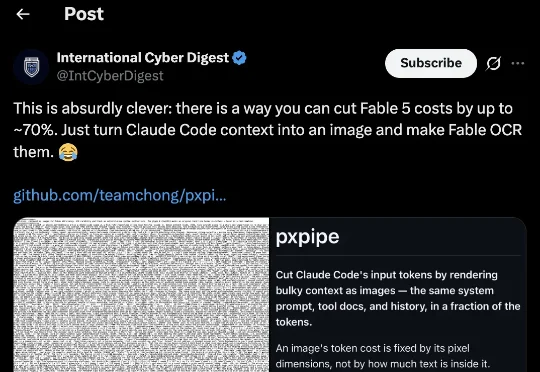
这两天,有位机智的老哥发现,只要把Fable 5的上下文转换成一张张密密麻麻写满文字的图片,再让模型通过OCR读回来,token输入成本最多能省下70%。更离谱的是,不只是普通对话,系统提示、工具文档、历史记录,全都能一股脑塞进图里。

Bug Team 最新力作,在疯狂星期四落下帷幕,其实 K12 的教师空间就是 Bug Team 的另外一种业务模式,他同样是有管理员和普通用户。 也有邀请和被邀请的功能,完全不知道 OpenAI 到底如何能写出这么匪夷所思的代码的,他的后端权限接口竟然没有鉴权,允许用户非受邀主动加入 K12 的教师空间,然后再拥有非管理员审批的权限,唯一的要求就是需要使用同一个域名邮箱
埃森哲的 AI 策略负责人最近在一次内部会议上,吐槽了公司里消耗 AI 算力的情况:驱动 token 消耗的,不是工程师在做开发,是非技术人员在用 AI 把 PDF 转成 PPT。 这怎么是滥用呢?堂堂埃森哲一个咨询公司,做 PPT 才是正经事啊!

做大模型RL微调,你是不是也踩过这些坑?

哈喽朋友们,最近也是囤上 Codex 的重置额度了。

刚刚,Anthropic正式官宣:Fable 5回来了!就这简单的一句话,让全网奔走相告。苦等19天,所有人像过年一样冲回Claude,就为了亲眼确认那个熟悉的名字重新亮起。而且千万注意,一旦额度达上限,Fable 5跑起来的Token消耗远超Opus 4.8。