
晶圆级芯片和存算一体结合:中科院提出15万tokens/s晶圆级芯片方案丨ASPLOS'26
晶圆级芯片和存算一体结合:中科院提出15万tokens/s晶圆级芯片方案丨ASPLOS'26当前大模型的发展呈现出类似于“军备竞赛”的趋势——模型规模持续攀升,对计算硬件的需求也随之快速增长。
来自主题: AI技术研报
9094 点击 2026-04-21 09:25
 搜索
搜索
当前大模型的发展呈现出类似于“军备竞赛”的趋势——模型规模持续攀升,对计算硬件的需求也随之快速增长。

今天早上,Cursor 在X上发布一条推文:“我们重建了 MoE 模型在 Blackwell GPU 上生成 Tokens 的方式,导致推理速度快了 1.84 倍。”
在使用体验上,龙虾的另一大特色是“活人感极强”。以往的AI,用户不搭话,它就永远沉默;而龙虾的机制则是「心跳」:每隔30秒,自己给自己发一条消息,反思有没有事情做,有的话就去做,没有的话就“没事,继续睡”。当然,这种活人感的代价,是燃烧的Tokens。

每天 120 万亿 Tokens,这就是今天上午火山引擎 AI 创新巡展上,豆包大模型亮出的最新成绩单。

3月30日,界面新闻记者从知情人士处独家获悉,3月初,在Kimi K2.5模型发布一个月之后,月之暗面ARR(年度经常性收入)突破1亿美金。知情人士还表示,K2.5模型上线后,API供应的TPM(Tokens Per Minute,每分钟令牌数)配额迅速趋紧,有客户开出千万美元级别的消费承诺及预付担保,以期获得优先供应。

国产大模型阵营再添硬核选手,智谱开放平台GLM5.1正式上线,推理、代码、智能体能力拉满,还为新用户准备了2000万Tokens免费体验包,覆盖多模型使用额度,有效期3个月。不管是日常编程开发、智能体搭建,还是多模态内容创作,这个免费额度都能轻松拿捏,新手也能零门槛上手,这波福利可别错过。

国家超算互联网宣布启动新一轮词元赠送活动。该活动面向平台全体用户,限时免费发放单人最高3000万词元额度,以降低科研专属“龙虾”SClaw等智能体体验门槛。此外, 超算互联网用户享0.1元/百万Tokens的特惠续用价,将延至4月6日。

英伟达200亿美元「招安」Groq,推理芯片赛道一夜变天。但在大洋彼岸,一家北大系创业公司刚刚交出了自己的流片答卷。

作为2月刷屏的现象级开源产品,OpenClaw不仅自身掀起了AI工具的使用热潮,成为全球最大API聚合平台OpenRouter上的Tokens消耗最多的应用,更成为了国产大模型出海的关键推手。
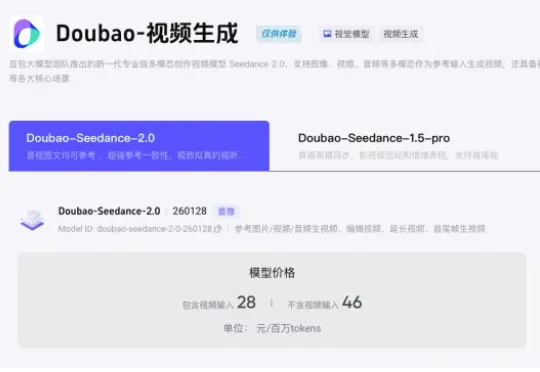
火山引擎官网,现已公布Seedance 2.0模型定价。包含视频输入的价格是28元/百万tokens,不含视频输入的价格则是46元/百万tokens。使用Seedance 2.0生成一条15秒的标准视频(720p,24fps),大概要消耗30.888万tokens。