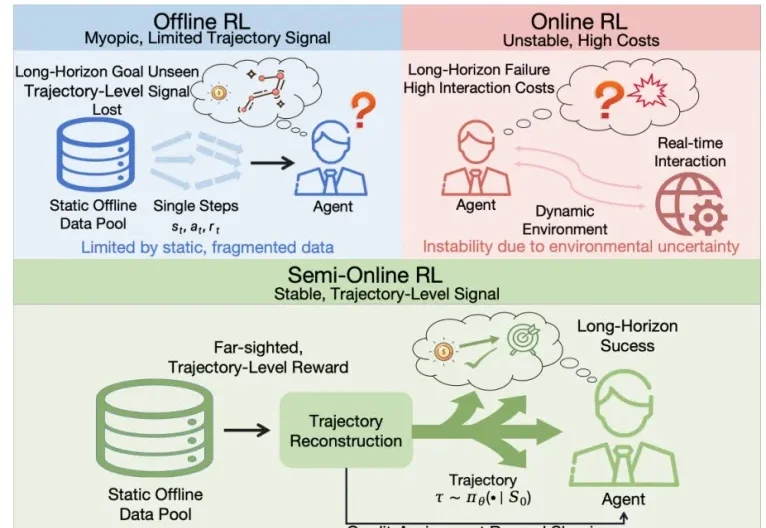
长链路手机AI训练总崩盘?vivo全新半在线RL,仅15k轨迹稳定收敛
长链路手机AI训练总崩盘?vivo全新半在线RL,仅15k轨迹稳定收敛想训练能自动操作手机的GUI(图形用户界面)智能体,总会遇到两难困境:
来自主题: AI技术研报
5461 点击 2026-06-29 09:18
 搜索
搜索
想训练能自动操作手机的GUI(图形用户界面)智能体,总会遇到两难困境:

如今手机拍照已成日常,后期修图是提升照片质感的关键。

前阵子有张梗图,在 AI Agent 圈子里火了:

智东西3月9日消息,近日,由前vivo与理想汽车产品负责人宋紫薇创立的薇光点亮完成超1亿元人民币的Pre-A轮融资。此轮融资由由红杉中国、蓝驰创投联合领投,蚂蚁战投、鼎晖投资、鞍羽资本跟投,老股东九合创投持续追投,所筹资金将重点用于人才梯队建设、新型智能硬件研发、垂类模型训练及时尚Agent关键应用场景落地。
「中国巴菲特」段永平,押注AI医疗。 数据显示,段永平Q4买入了AI医疗公司Tempus AI,新进11万股。 段永平曾一手打造小霸王、步步高,还是OPPO、vivo的幕后奠基人;之后退居幕后转向投资
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le

前vivo「最美产品经理」宋紫薇,AI创业细节进一步曝光了。量子位获悉,已经入局AI智能硬件赛道创业的宋紫薇,瞄准的是「AI化妆镜」。公开信息显示,薇光点亮成立于2024年11月,自一开始便将目光瞄向了AI硬件——并且还是“时尚”和“年轻”的硬件。
机器之心报道 编辑:泽南 真正实用化的生成式 AI,应该是这个样子 —— 作为助手可以帮你代打电话,根据你的选项进行应答,还能引导对方转人工: 功能覆盖多个场景,连接大量第三方应用,实现多智能体的一键
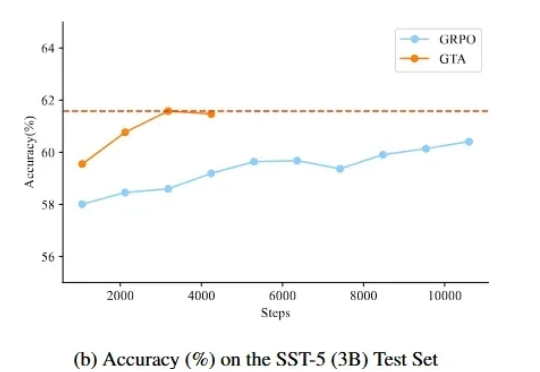
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
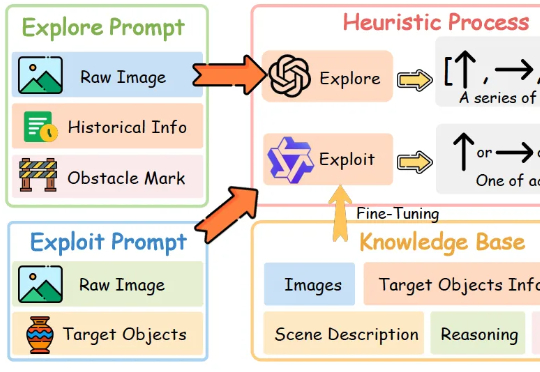
让机器人像人一样边看边理解,来自浙江大学和vivo人工智能实验室的研究团队带来了新进展。