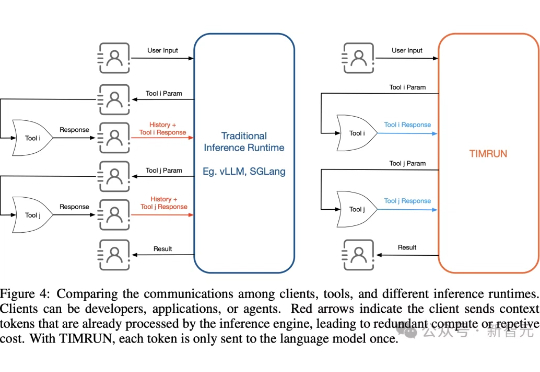
清华校友出手,8B硬刚GPT-4o!单一模型无限工具调用,终结多智能体
清华校友出手,8B硬刚GPT-4o!单一模型无限工具调用,终结多智能体大模型再强,也躲不过上下文限制的「蕉绿」!MIT等团队推出的一套组合拳——TIM和TIMRUN,轻松突破token天花板,让8b小模型也能实现大杀四方。
来自主题: AI资讯
8406 点击 2025-08-22 17:14
 搜索
搜索
大模型再强,也躲不过上下文限制的「蕉绿」!MIT等团队推出的一套组合拳——TIM和TIMRUN,轻松突破token天花板,让8b小模型也能实现大杀四方。
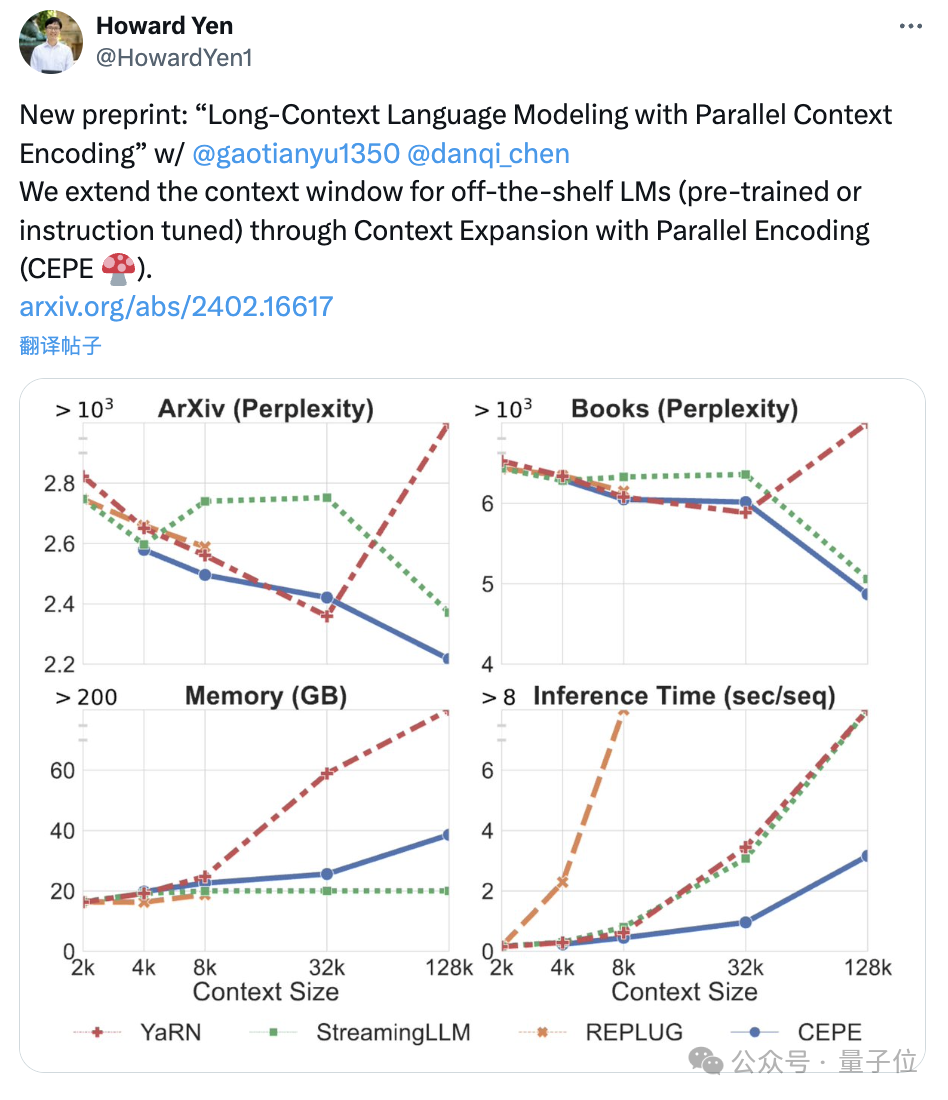
陈丹琦团队刚刚发布了一种新的LLM上下文窗口扩展方法:它仅用8k大小的token文档进行训练,就能将Llama-2窗口扩展至128k。

作者重点关注了基于 Transformer 的 LLM 模型体系结构在从预训练到推理的所有阶段中优化长上下文能力的进展。