提升大模型内在透明度:无需外部模块实现高效监控与自发安全增强|上海AI Lab & 上交
提升大模型内在透明度:无需外部模块实现高效监控与自发安全增强|上海AI Lab & 上交大语言模型(LLM)能力提升引发对潜在风险的担忧,洞察其内部“思维过程”、识别危险信号成AI安全核心挑战。
来自主题: AI技术研报
9079 点击 2025-06-23 14:58
 搜索
搜索
大语言模型(LLM)能力提升引发对潜在风险的担忧,洞察其内部“思维过程”、识别危险信号成AI安全核心挑战。

已推出超100款医疗AI产品。智东西6月21日报道,6月20日,上海医疗AI创企联影智能宣布完成A轮融资,总规模10亿元人民币。

“对发现问题的投入,与解决问题同样重要。”这是上海人工智能实验室主任周伯文在首届明珠湖会议所作开场报告中的核心观点之一。
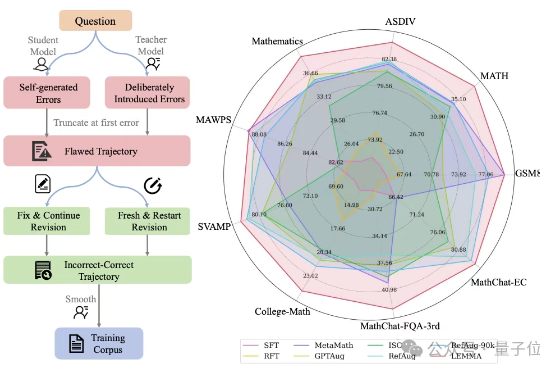
大模型学习不仅要正确知识,还需要一个“错题本”?
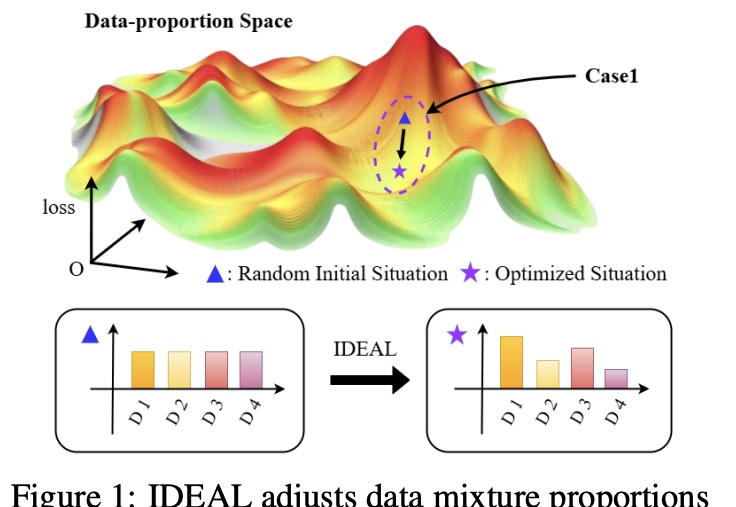
大幅缓解LLM偏科,只需调整SFT训练集的组成。
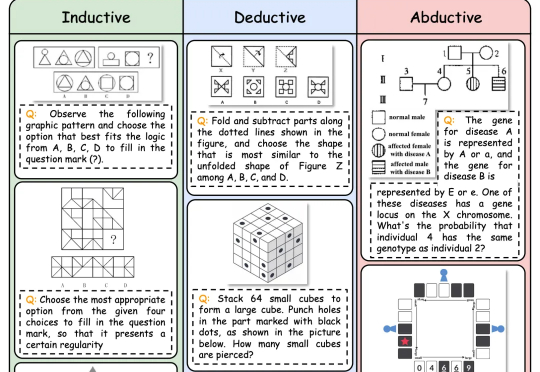
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)
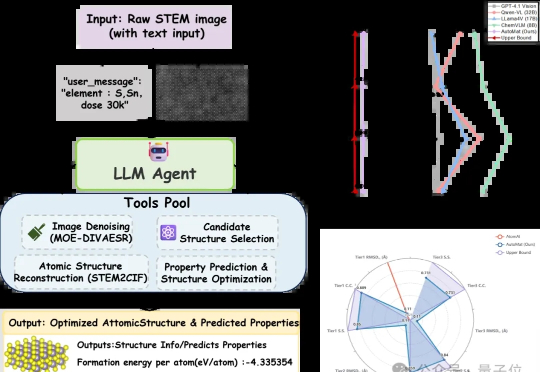
AI Agent又解锁了一个领域!清华大学牵头,与西北工业大学以及上海AI lab等机构推出了电镜领域的AI agent——AutoMat。
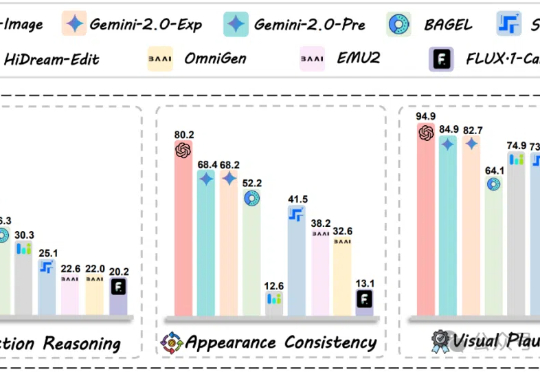
GPT-4o-Image也只能完成28.9%的任务,图像编辑评测新基准来了!360个全部由人类专家仔细思考并校对的高质量测试案例,暴露多模态模型在结合推理能力进行图像编辑时的短板。
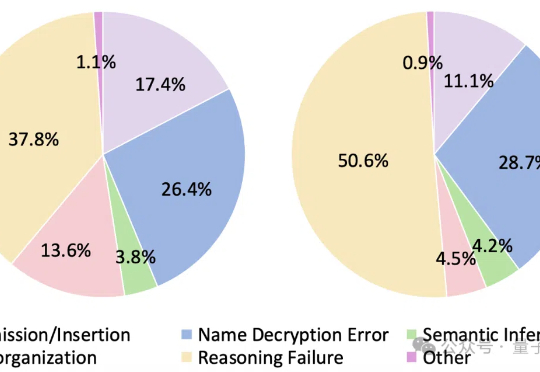
大语言模型遇上加密数据,即使是最新Qwen3也直冒冷汗!
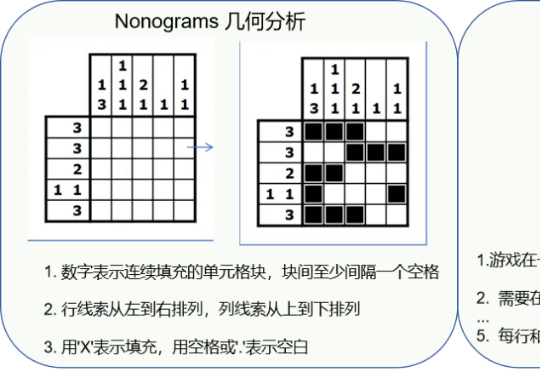
围棋因其独特的复杂性和对人类智能的深刻体现,可作为衡量AI专业能力最具代表性的任务之一。