奥特曼点名「AGI最后一块拼图」!记忆,才是硅谷2026新共识
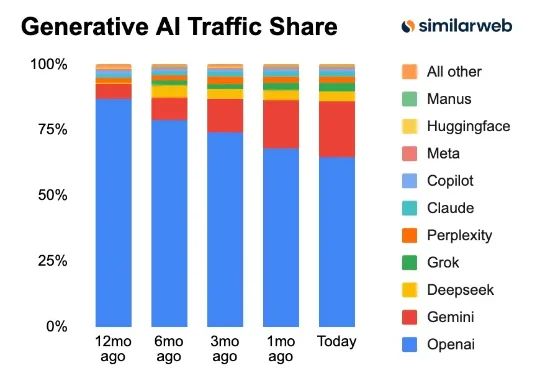
奥特曼点名「AGI最后一块拼图」!记忆,才是硅谷2026新共识最近,奥特曼的焦虑肉眼可见。去年年底,谷歌Gemini 3横空出世,一举横扫各大榜单,将ChatGPT狠狠拽下了神坛。为了抢回AI皇冠,奥特曼不得不拉响「红色警报」。
来自主题: AI资讯
8946 点击 2026-01-10 17:01
 搜索
搜索
最近,奥特曼的焦虑肉眼可见。去年年底,谷歌Gemini 3横空出世,一举横扫各大榜单,将ChatGPT狠狠拽下了神坛。为了抢回AI皇冠,奥特曼不得不拉响「红色警报」。

今天我们就借着科技领域的东风,花1分钟时间来了解一下MiniMax的创始人闫俊杰的个人履历和创业故事:1989年,闫俊杰出生于河南某县城。闫俊杰的爸爸是一名初中老师,妈妈是一名公务员,尽管闫俊杰说小时候县城的教育资源相对匮乏,但他父母都有稳定的工作,想必他的童年也比较幸福。
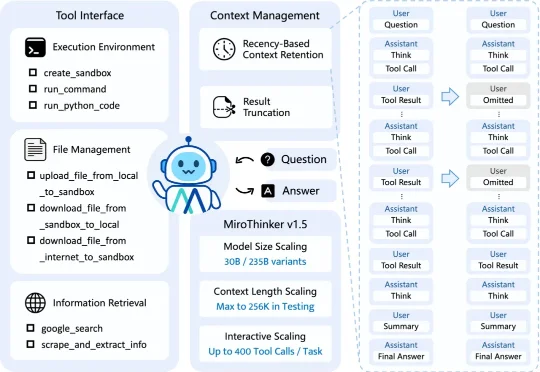
2026年1月5日,由陈天桥和清华AI学者代季峰联合发起的MiroMind团队,正式发布了自研旗舰搜索智能体模型MiroThinker 1.5。这个消息本身并不算特别,毕竟最近几个月几乎每周都有新模型发布。但当我深入了解后发现,这个模型背后代表的思路,可能会彻底改变我们对AI能力边界的认知。
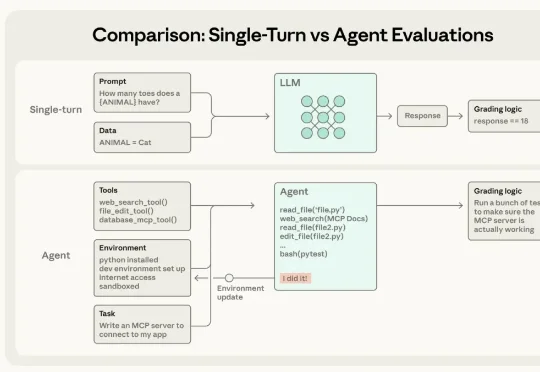
Agent 并不是一次性输出的系统。它们运行在多轮交互之中:调用工具、修改内部状态、根据中间结果不断调整策略。也正是这些让 Agent 变得有用的能力 ——自主性、智能性与灵活性 —— 同时也让它们变得更难以评估。

在这场一年狂飙的亲历者之一——MCP 联合创作者、核心维护者 David Soria Parrra 看来,最戏剧性的分水岭发生在四月前后:当 Sam Altman、Satya Nadella、Sundar Pichai 先后公开表态,Microsoft、Google、OpenAI 都将采用 MCP,“大客户”突然从 Cursor、VS Code 扩散到整个行业。
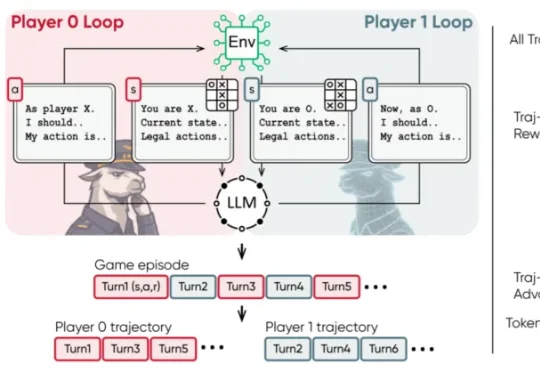
近日,清华大学等机构的研究团队提出了 MARSHAL 框架。该框架利用强化学习,让大模型在策略游戏中进行自博弈(Self-Play)。实验表明,这种多轮、多智能体训练不仅提升了模型在游戏中的博弈决策水
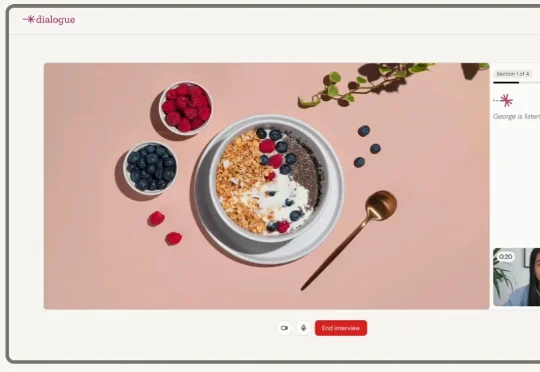
在传统企业中,市场调研往往是决策最慢的一环,从问卷设计到洞察输出要花上数周。Dialogue AI试图用AI自动化整个研究流程,让洞察生成的速度与产品迭代保持同步。它的出现不仅是效率的革新,更是企业理解用户方式的范式转变——让研究从被动响应变为实时驱动。

联想给出的公式是,混合AI=个人智能+企业智能+公共智能。这种模式下,AI智能体应用不再依赖于单一的云端模型,而是云端大模型与本地定制化小模型的深度融合。
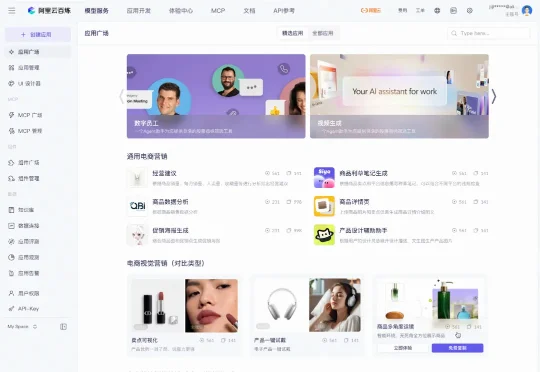
百炼升级了其提出的「1+2+N」的蓝图:其中最底层的 1 是模型与云服务,中间层的 2 是高代码、低代码的开发范式,在最上层的 N 则是面向不同任务的开发组件。这套能力覆盖了生产级智能体构建的全生命周期。

CaveAgent的核心思想很简单:与其让LLM费力地去“读”数据的文本快照,不如给它一个如果不手动重启、变量就永远“活着”的 Jupyter Kernel。这项由香港科技大学(HKUST)领衔的研究,为我们展示了一种“Code as Action, State as Memory”的全新可能性。它解决了所有开发过复杂Agent的工程师最头疼的多轮对话中的“失忆”与“漂移”问题。