
当 ChatGPT 要开始「搞黄色」,我都不敢想......
当 ChatGPT 要开始「搞黄色」,我都不敢想......我们又距离《Her》的世界更进一步。10 月 15 日,Sam Altman 在 X 上的一条推文炸了。 他的大意是:以前为了保护心理健康,ChatGPT 被我们限制得太严了……接下来,我们会放宽这些限制,让它更像人,更有个性。
来自主题: AI资讯
11164 点击 2025-10-19 16:07
 搜索
搜索
我们又距离《Her》的世界更进一步。10 月 15 日,Sam Altman 在 X 上的一条推文炸了。 他的大意是:以前为了保护心理健康,ChatGPT 被我们限制得太严了……接下来,我们会放宽这些限制,让它更像人,更有个性。

在近日的一次访谈中,Andrej Karpathy深入探讨了AGI、智能体与AI未来十年的走向。他认为当前的「智能体」仍处早期阶段,强化学习虽不完美,却是目前的最优解。他预测未来10年的AI架构仍然可能是类似Transformer的巨大神经网络。

麻省理工学院最新研究预示着人类距离能够自主学习的AI又迈出了关键一步。该研究推出了一种全新的自适应大模型框架「SEAL」,让模型从「被动学习者」变为「主动进化者」。
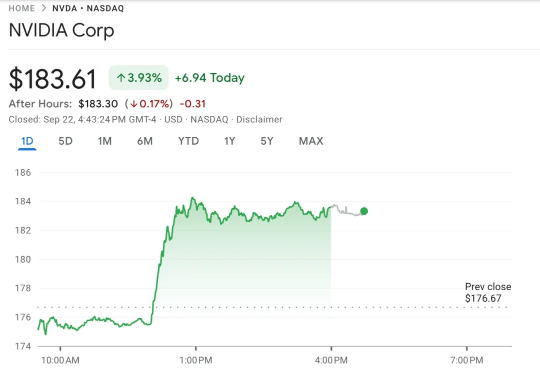
英伟达不光自己成长高速,现在它在AI领域的投资也坐上火箭了。 最新数据显示,2025年过去的三个季度里,英伟达参与了50笔AI相关风险投资,这个数量已经超过了2024年全年的48笔。
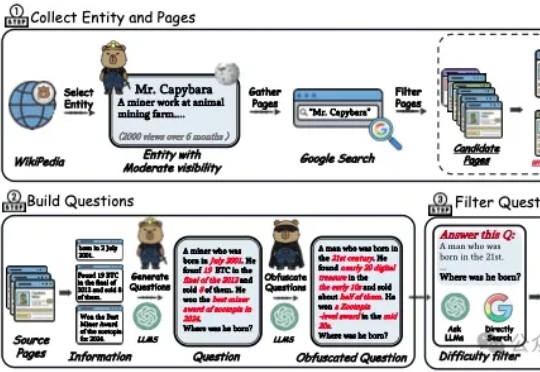
中科院的这篇工作解决了“深度搜索智能体”(deep search agents),两个实打实的工程痛点,一个是问题本身不够难导致模型不必真正思考,另一个是上下文被工具长文本迅速挤爆导致过程提前夭折,研究者直面挑战,从数据和系统两端同时重塑训练与推理流程,让复杂推理既有用又能跑得起来。
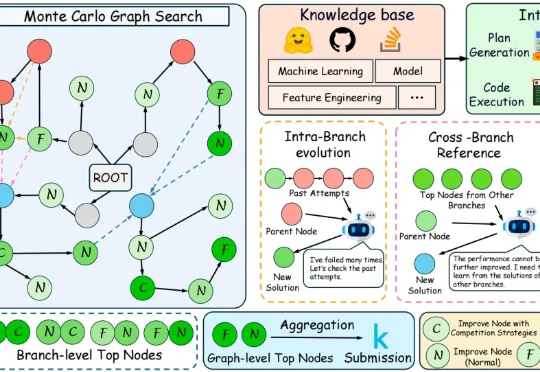
在代码层面,大语言模型已经能够写出正确而优雅的程序。但在机器学习工程场景中,它离真正“打赢比赛”仍有不小差距。
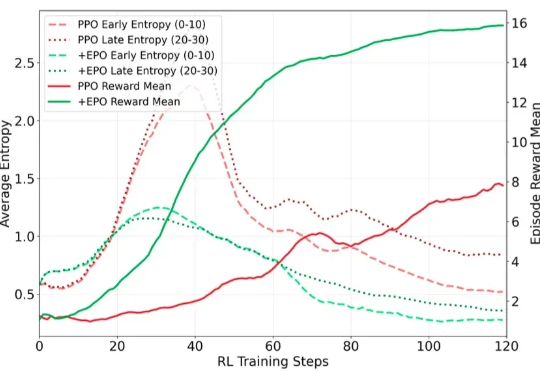
在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。

2 天前,国内最大的 AI 多模态模型社区之一的 LiblibAI 进行了一次大升级,正式推出了 2.0 版本。对许多创作者而言,这个平台并不陌生,LiblibAI 一直是国内开源绘画与 LoRA 文化的重要发源地,也常被称为中国版的 CivitAI (大家常说的 C 站)。

90%的开发者都在用AI,却只有24%真正信任它!DORA 2025报告揭示:AI不是万能解药,而是放大镜。它让强者飞升,让弱者溃败。七种团队人设、七项关键能力,决定了你的团队,是进化还是崩塌。
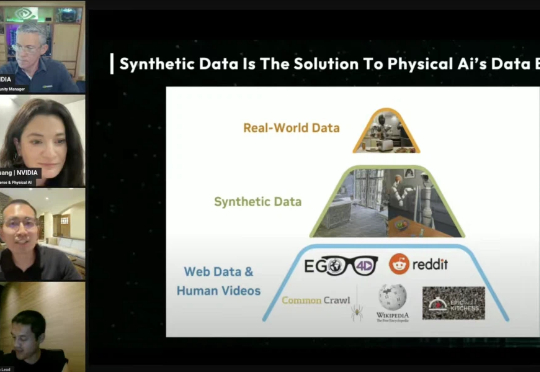
黄仁勋大家都见得多了,但你见过他女儿讲具身智能吗?这不,黄仁勋女儿Madison Huang首次公开亮相直播访谈节目,作为英伟达Omniverse与物理AI高级总监,与光轮智能CEO谢晨,以及光轮智能增长负责人穆斯塔法一起,对“如何缩小机器人在虚拟与现实之间的差距”展开深刻探讨。