# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
中科院的这篇工作解决了“深度搜索智能体”(deep search agents),两个实打实的工程痛点,一个是问题本身不够难导致模型不必真正思考,另一个是上下文被工具长文本迅速挤爆导致过程提前夭折,研究者直面挑战,从数据和系统两端同时重塑训练与推理流程,让复杂推理既有用又能跑得起来。

您会看到一个清晰的工程取舍:把“高质量、可验证且跨来源”的问题做成训练燃料,把“早期工具输出”当作可随取随用的缓存而非永久负担,并把这种上下文状态贯穿训练与推理保持一致。结果是很直白的改变,代理不再在第十几轮就被迫收场,而是在标准32k上下文里把多达近百次的工具交互稳稳接住,过程里的推理链也能被完整保留。最终让一个32B的中等开源模型也能在“需要查多站点、要证据、要推理”的任务上稳定、可解释、成本可控地工作。这正是很多公司把“AI 研究助理或分析师”做成真正能上线并复用的关键。

您可能也踩过这个坑,训练数据“太浅”,学不出真实的研究型行为:现在开源常用的多跳QA数据偏维基百科式,模型容易靠记忆或者单页检索“蒙对”;上生产后遇到跨多站点、多时间线、需核验的任务就“不会做”。另外一个则是上下文爆炸,长流程撑不住,在32k上下文下有效交互通常只撑十到十五轮,工具返回的网页片段普遍比助理推理文字长五到十倍,增长最快的那部分总是把空间吃光。很多系统用摘要模型来压缩工具输出,不过信息粒度会丢、系统耦合度变复杂、而且更关键的是它很难纳入端到端的可验证强化学习之中,于是训练时的最优策略和上线时的行为会出现偏差。
这部分的目标是:做出必须跨多网页、多步推理才能答对、而且答案可被网页证据核验的问题,从而在训练时逼着模型学会“验证—回溯—分解子目标—跨文献综合”的专家式策略;研究者把这称为一种“反向构造(reverse construction)”的任务生成法。

第 1 步:以“实体”为锚,先把真实网页证据收集齐(信息必须够、且互补)
1.实体对应性:和维基对照,排除“同名不同人”的混淆;
2.信息互补性:只留能提供新增且独立信息的页面,去掉“重复说法”;
3.站点可信度:去掉不可靠来源,保留可信站点。这样保证以后出题时,信息是“散落在多页”“彼此互补”且“可靠”的。
第 2 步:基于多源证据“出题”,并且刻意提难度(强制多源、禁止维基、再做“二次模糊化”)
第 3 步:双重过滤——先判“容易题”一律剔除,再判“质量问题”严格去除
1.直接搜索引擎看能否一步搜到实体或答案;
2.零样本大模型看能否直接猜中。
任何一条能轻易命中,就不是我们想要的“必须多步、多源”题,全部剔除。
1.表述含混、容易引歧义;
2.答案本身含糊或不唯一;
3.答案不能从给定参考文档中逻辑推导出来(即证据链不足)。
过滤后留下的问答对才是“难且可验”的高质量训练样本。
为什么这招有效?
因为它正对现实里的长程检索任务:信息分散、信噪参差、必须跨页比对与回溯确认。现有很多多跳数据集多依赖结构化维基信息,容易被“浅层检索 + 模型记忆”解决,无法诱发“验证、回溯、规划”这些真正的“专家型认知行为”。

为何需要新策略?研究者先做了实证分析:在常见的 32k 上下文里,多数模型大约 10~15 轮就把上下文吃满了;原因在于工具返回的网页内容通常是助理回复的 5~10 倍长,它们像雪球一样堆高,把对话空间迅速挤爆。但这些“很长的工具输出”往往只影响“紧接着的下一步决策”,对十几轮之后的决策影响很弱。于是保留所有历史工具输出既浪费上下文,也不划算。

基于这个观察,研究者提出“滑动窗口”上下文管理:

训练-推理一致(训练时怎么做)
仅仅在推理时滑窗还不够:如果模型是在“完整历史”上训练、却被迫在“滑窗上下文”里推理,就会出现分布不一致,从而不稳。为此,研究者把每条轨迹按推理中的滑窗节奏拆成多段训练序列,让模型在训练期就习惯“有些旧网页被占位符替换”的上下文状态:

个训练序列;第 1 个序列包含最初的完整上下文;后续第 个序列里,按滑动边界把更早的 换成占位符,只保留窗内的工具原文,以复现推理过程中的真实可见上下文。

结果与优势(为什么这招比“摘要旧网页”更合算)
冷启动阶段采用监督微调(Supervised Fine‑tuning)来先把“会用工具、会分步想”的基本功打牢,研究者用能力更强的模型在真实网页环境生成动作轨迹,生成时同样使用动态滑动窗口避免因上下文长度把轨迹掐断,然后把最终答案错误或长度过度的轨迹过滤掉,余下高质量示例经过“多序列构造”训练模型适应动态上下文。强化学习阶段采用组相对策略优化(Group Relative Policy Optimization)来进行策略改进,对同一道题生成多条完整轨迹并依据最终答案是否正确给出可验证的二值奖励,再在组内做标准化得到优势,并把每条轨迹的优势传给它对应的所有训练序列,于是轨迹级的反馈被稳定地用于序列级的参数更新。
具体的工程细节也交代得很实在,基座是 Qwen3‑32B 并启用思考模式,监督微调使用大约3000条高质量轨迹、批大小256、学习率1乘以10的负5次方,强化学习用大约4000个问题、批大小32、学习率2乘以10的负6次方,每个问题生成8条 rollout,最大轨迹长度四万 token、单题回合上限60,工具窗口大小设置为5、滑动步长为3,训练实现基于 VERL 框架;评估时在 BrowseComp、BrowseComp‑zh、XBench‑DeepSearch 与 GAIA 上统一使用温度0.6、top‑p 0.9、最多一百轮交互,并同样使用窗口5加滑动3的上下文管理,同时由评审模型以结构化提示词判定最终答案的正确性。
很多人第一反应是再加一个摘要模型帮忙压缩网页内容,不过研究者把重心放在“读什么、怎么读、读到哪一页就停”,他们只保留三个轻量而高杠杆的工具:用搜索服务拿到标题、链接和摘要,用抓取服务按分页把网页转换成可滚动的Markdown文本,再用页内查找在长文中定位关键词和附近语境,从而让模型像人一样先粗看轮廓再决定是否深读。您可以把它理解成“把主动权交给代理”,它可以在一页页的内容中快进、暂停、退出,而不是被一次性塞进几千字然后被动消化;因为不做外部摘要,信息细节不会被提前裁剪,端到端训练也不会出现“看不到真实文本”的优化断层。
研究者在附录里给了一个案例轨迹,问题要求在芜杂线索中锁定唯一历史地点,条件涉及是否位于国家首都、是否临河、开工与完工年份范围、墙体厚度的数值区间、是否经历特定时间段的龙卷风与地震破坏、是否在1980至1990年间被政府收购以及收购当时总统的出生年份落点,这类题目逼着代理跨多个网页反复核验并在必要时回头重查;在工具配合上,先用搜索服务摸清候选,再用抓取服务分页细看关键页面,再通过页内查找迅速跳到关键词附近段落,同时滑动窗口持续把很早的工具长文本挪走、把思考过程完整保存。最后锁定的答案是达卡的 Ahsan Manzil,整个过程把“跨来源拼接事实与交叉验证”的套路走得很稳,既没有依赖内部记忆,也没有依赖一刀切的摘要。

把路修平之后,数字表现就能直接说明问题。
研究者在四个“深度网页研究型”基准上测试模型:

这些基准都属于需要真实网页工具的任务,也就是:问题答案不能直接从模型记忆里取,而必须查网页、整合、验证。

DeepMiner‑32B 在 BrowseComp‑en 上给出33.5的正确率,相比此前开源代理的区间有明显提升,而且在 BrowseComp‑zh、XBench‑DeepSearch 与 GAIA 上也呈现同向改进;更有参考意义的是监督微调版的表现,它在不少基准上已经超过诸多开源代理,这组成绩意味着 DeepMiner 在开源体系里达到了“接近商用水平”的深度网页推理效果。这提醒我们“高难度且可验证的数据”本身就能带来收益,然后在可验证强化学习与动态上下文的配合下再进一步。评测统一采用温度0.6与 top‑p 0.9的解码设置、最多一百轮的交互上限,以及窗口5加滑动3的上下文管理,并使用结构化的评审提示词让判定过程可追溯,这些细节对您在本地复现会非常关键。
这一部分单独测量了三种上下文管理策略的差异:

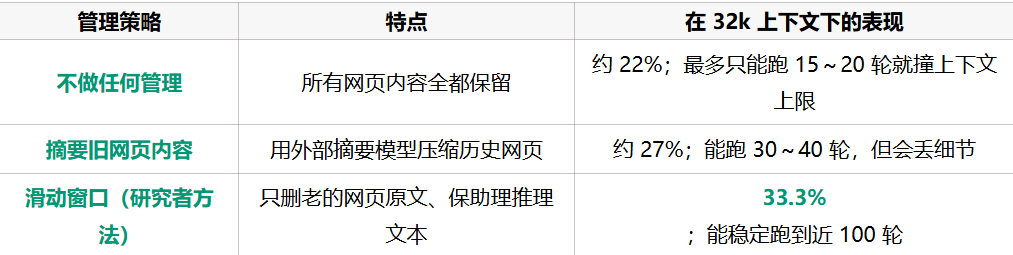
然后在 64k 和 128k 的上下文长度下再次比较:
结论:
滑动窗口管理不仅节省上下文,还能保持推理稳定性;同等上下文容量下,它能让模型多推理出几乎 4~6 倍的轮数。
研究者在实验图中展示了不同上下文长度下三种策略的曲线:滑动窗口曲线几乎在 32k 时就达到顶峰,而其他方法到 128k 才接近。
关于deep search agents,感兴趣您可以再看下这篇综述

华为、牛津联手发布万字报告,揭秘OpenAI、谷歌都在秘密布局的“DR代理”
说到底,这套路线把“问题要逼真且难”“上下文要可控且一致”“反馈要可验证且稳定”三件事捏在了一起,才让多轮搜索代理从浅尝辄止变成持续深挖;我更愿意把它看成一种工程视角的整理思路,先守住推理链的连续性,再把最肥的上下文开销按需挪走,最后让训练与推理共享同一种“世界状态”。如果您正把网页搜索、智能分析或企业知识问答做成实用产品,这些改造点完全可以逐步迁入现有系统,不需要推倒重来,就能把“能想多久”和“想得对”这两个老问题同时稳住。
文章来自于微信公众号“AI修猫Prompt”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
