免费 1500 次背后,商汤在下一盘什么棋
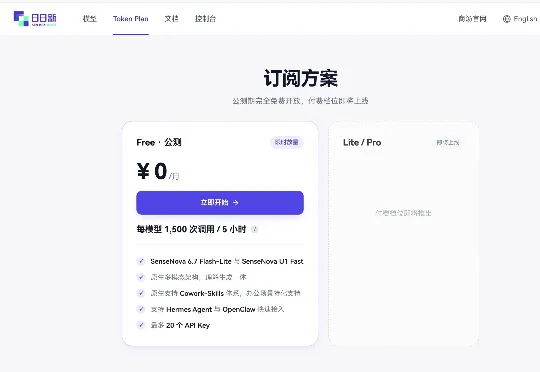
免费 1500 次背后,商汤在下一盘什么棋商汤最近做了一件大多数大模型公司都不舍得做的事。每 5 小时 1500 次免费调用,Token 消耗比同行低 60%,三款新产品同步上线,还把核心模型 U1 以 Apache 2.0 协议全面开源——在大模型公司普遍在想怎么收费的当下,商汤在反向操作。
来自主题: AI资讯
10413 点击 2026-05-12 16:47
 搜索
搜索
商汤最近做了一件大多数大模型公司都不舍得做的事。每 5 小时 1500 次免费调用,Token 消耗比同行低 60%,三款新产品同步上线,还把核心模型 U1 以 Apache 2.0 协议全面开源——在大模型公司普遍在想怎么收费的当下,商汤在反向操作。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
随着语音、视频、多模态能力不断融入大语言模型(LLM),人与 AI 的交互正在越来越接近自然对话。今天的 LLM 不再只是回答问题的工具,也越来越多地出现在教育、客服、陪伴、心理健康等高度依赖情绪理解的场景中。

近日,原力灵机开源的具身智能原生框架 Dexbotic 宣布正式支持以 RLinf 作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着 VLA 模型研发中长期存在的「SFT 与 RL 割裂」问题,正在被真正打通。
Claude Code今天正式推出Agent视图功能,让用户在一个界面里统一管理所有Claude Code会话。此前并行运行多个Agent时,开发者往往需要同时维护多个终端标签页、一个tmux网格,还得靠脑子记住每个任务的进度。

Mira Murati 用一年半时间证明了「人机协作」不是一句口号。 5 月 11 日,Thinking Machines Lab 发布了一段研究预览视频,展示了他们所谓的「交互模型」(Interaction Model)。
「一个人现在可以跑出一家30人公司才能完成的收入。」然后他说:这句话在2022年不成立。在2024年中段某个时间点,变成了真的。而且差距每个季度都在扩大。不是因为这个说法多新鲜——AI能提效这件事大家都听说过了。是因为他不只是说「理论上可以」,他是说他自己做到了,然后顺手把操作手册拿出来给你看。
「我即将离开麻省理工学院,不再继续攻读博士学位。人工智能的发展速度太快,人类已然难以跟上。
刚刚,DeepSeek融资这件事差不多落定了。据top华人科创社区消息,此轮由阿里、腾讯和国家大基金各注资 100 亿,加上创始人梁文锋个人的 200 亿组成,公司估值约为 3500 亿人民币。
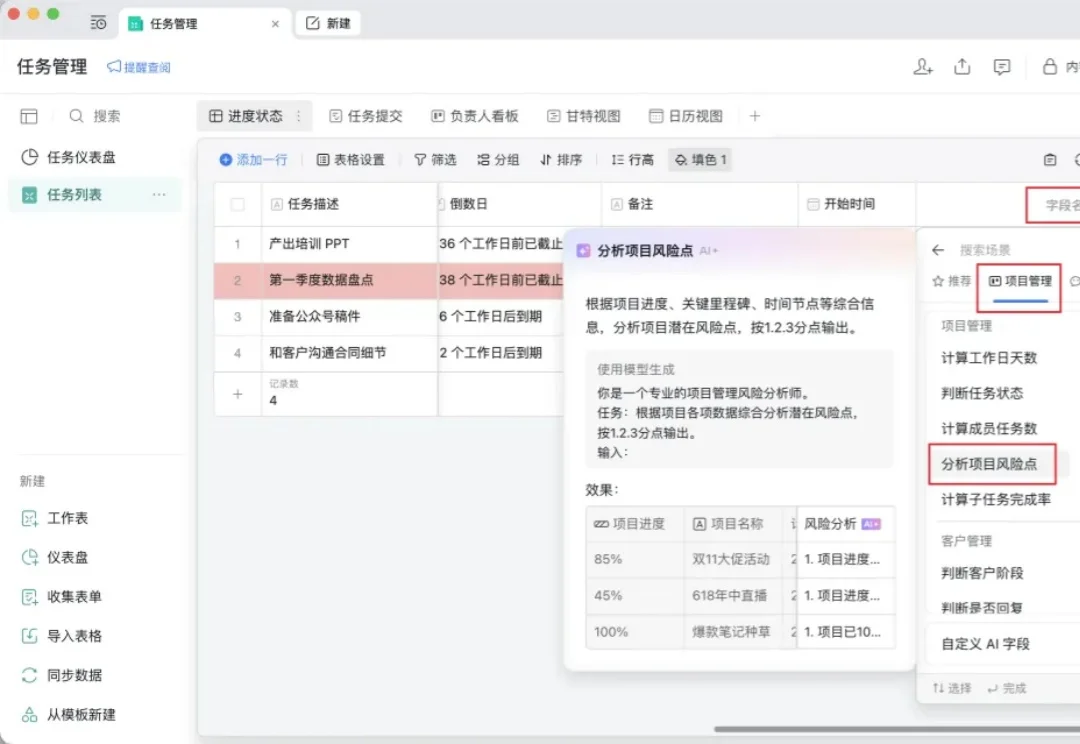
大家好,我是袋鼠帝 一提企微,我第一反应和大多数人一样:"公司让我装的那个"。打卡用的,汇报用的,管理用的。