科学家Ilya不想当CEO,都是扎克伯格逼的
科学家Ilya不想当CEO,都是扎克伯格逼的Ilya,被迫当公司CEO了。是的,即便两次改变了AI、改变了世界,但Ilya一直是研究员、首席科学家…而这一次,不得不当自己创办公司的CEO。全怪Meta挖人太狠,全怪扎克伯克开的薪资条件无法拒绝。
来自主题: AI资讯
9840 点击 2025-07-06 10:18
 搜索
搜索
Ilya,被迫当公司CEO了。是的,即便两次改变了AI、改变了世界,但Ilya一直是研究员、首席科学家…而这一次,不得不当自己创办公司的CEO。全怪Meta挖人太狠,全怪扎克伯克开的薪资条件无法拒绝。

2025年的夏天,AI对各行各业的颠覆作用还在持续——餐饮业也不例外。就在刚刚过去的六月,旗下拥有肯德基、必胜客等头部品牌的餐饮巨头“百胜中国”,发布了首个餐厅营运智能体“Q睿”(Q-Smart Agent)。

大模型数学能力骤降,“罪魁祸首”是猫猫?只需在问题后加一句:有趣的事实是,猫一生绝大多数时间都在睡觉。
Agent 产品正发布得火热,但要说到真正懂企业、懂决策的 Agent 还不算常有。其背后,还有大量企业积累的业务数据,在等待被高效利用起来。数据 Agent 会成为一个好解法吗?

Jack Clark 是最关注和熟悉中国在芯片、计算和模型上进展的 AI Lab 领导人之一。他毫不吝啬对中国 AI 进展的认可,将 DeepSeek R1 视作“推理模型大范围扩散”的起点,近期又把 HyperHetero 使用的异构集群叫做通过“超级智能进行持续自我训练”的垫脚石。
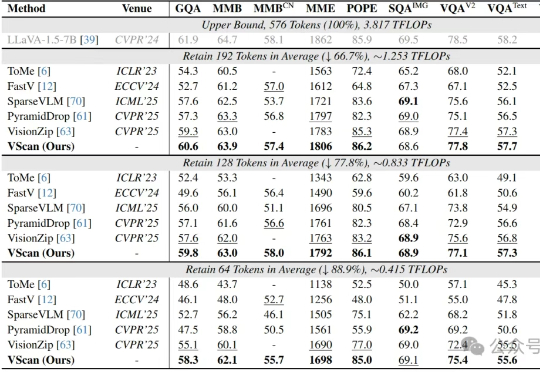
多图像、长视频、细粒度感知正在让大型视觉语言模型(LVLM)变得越来越聪明,但也越来越“吃不消”:视觉Token数量的激增所带来的推理成本暴涨,正逐渐成为多模态智能扩展的最大算力瓶颈。

AI 社交,尤其是 AI 角色扮演方向,最近势头不太好,产品停止投入、流量下降等消息不少。但另一个细分方向,一直处于边缘位置的 AI 陪伴产品,在有点颓的市场环境中,正在默默发力。
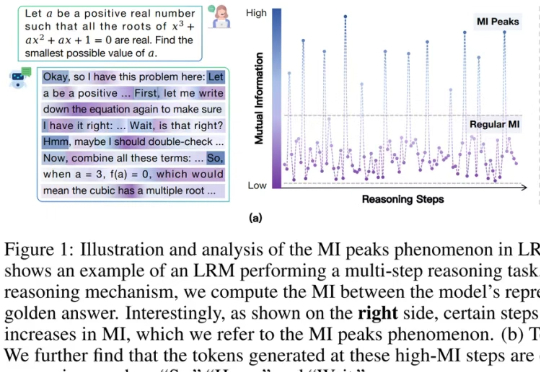
你肯定见过大模型在解题时「装模作样」地输出:「Hmm…」、「Wait, let me think」、「Therefore…」这些看似「人类化」的思考词。
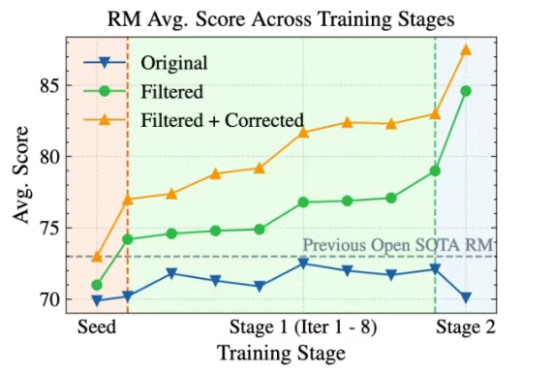
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。 基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。
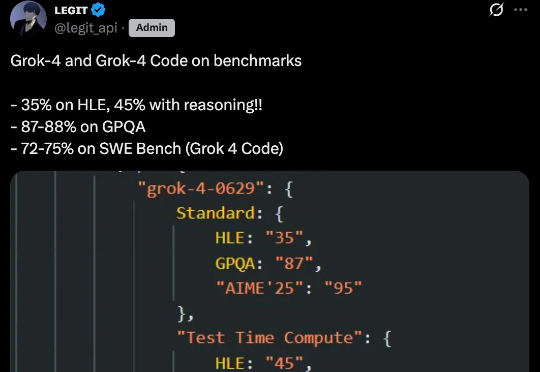
刚刚,Grok 4 和 Grok 4 Code 的基准测试结果疑似泄露。X 博主 @legit_api 发帖称,Grok 4 在 HLE(Humanities Last Exam,人类最后考试)上的标准得分是 35%,使用推理技术后提高到 45%;在 GPQA 上的得分是 87-88%;而Grok 4 Code 在 SWE Bench 上的得分则达到 72-75%。