你的「龙虾」真记得你吗?剑桥发布长期个性化记忆基准ATM-Bench
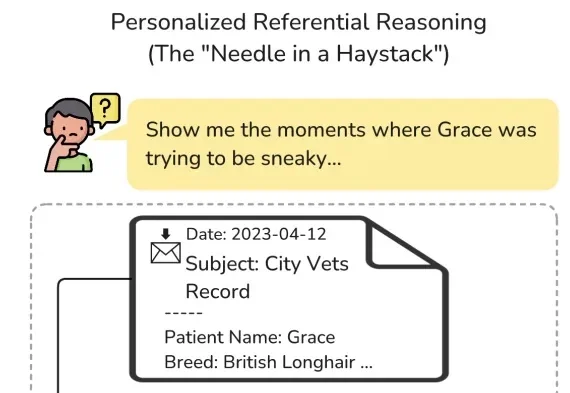
你的「龙虾」真记得你吗?剑桥发布长期个性化记忆基准ATM-BenchATM-Bench 将「个人 AI 助手是否真的记得你」这件事,变成了一个研究的测试基准。结果并不乐观:专用记忆智能体系统普遍低于 20%,而 OpenClaw、Codex、Claude Code 等通用智能体普遍表现不佳,最高准确率不到 40%。
来自主题: AI技术研报
10229 点击 2026-04-20 14:36
 搜索
搜索
ATM-Bench 将「个人 AI 助手是否真的记得你」这件事,变成了一个研究的测试基准。结果并不乐观:专用记忆智能体系统普遍低于 20%,而 OpenClaw、Codex、Claude Code 等通用智能体普遍表现不佳,最高准确率不到 40%。

杨植麟身上正在形成一种很典型的创业者光环。

如今的大多数智能体,仍然活在一种「失忆式工作」模式中:每一次检索都是从零开始,每一条推理路径都无法沉淀,每一次失败也不会转化为经验。它们虽能多轮交互,但很难在深度研究中持续变强。

前几天,Anthropic 开源了 claude-desktop-buddy,用一块小屏幕显示 Claude Code 里 Buddy 的状态。结果做着做着,它变成了一个完全不同的东西:M5 Paper Buddy (https://github.com/op7418/m5-paper-buddy)。

身边做短视频的朋友,几乎人手一个剪映。
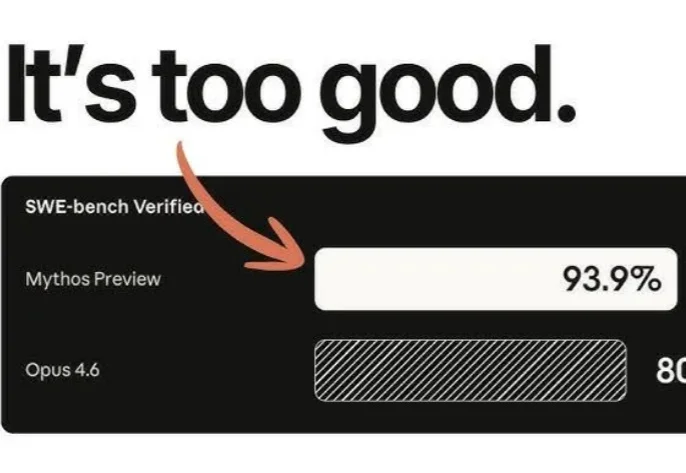
Anthropic 最强的模型,也是他们不敢发布的模型
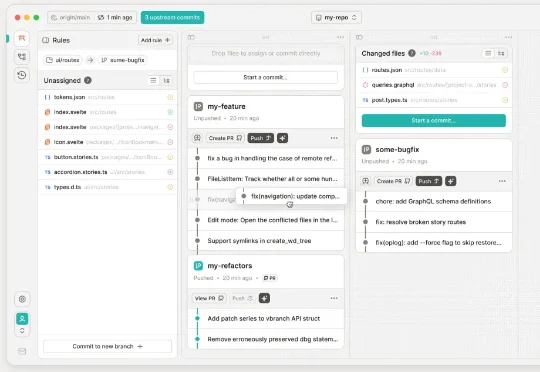
GitButler最近发布的CLI工具引起了我很大的兴趣。这不是一个简单的Git包装器,而是从根本上重新思考了命令行工具应该如何设计。Scott提到了一个有趣的观察:大约80%的开发者仍然使用命令行工具来操作Git,即使有各种GUI工具存在。
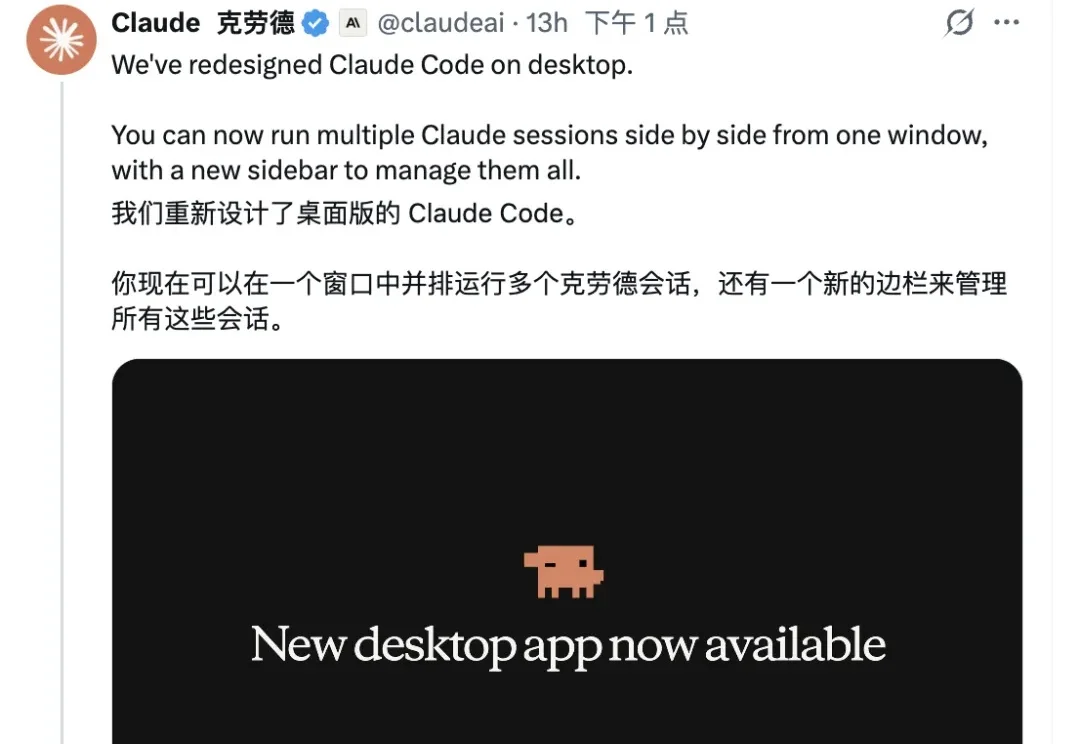
过去这半年,AI 圈有个变化特别扎眼:它不再只是能写几行代码,而是开始试图接管整个开发流程,从拆需求、推架构到写代码、修 Bug,一整条链路都在被重塑。过去我们评价一款 AI 编程工具,问的是它能写多少代码?写得够不够好?而现在,大家更关心的是它能不能把事情做完?用起来够不够省心。
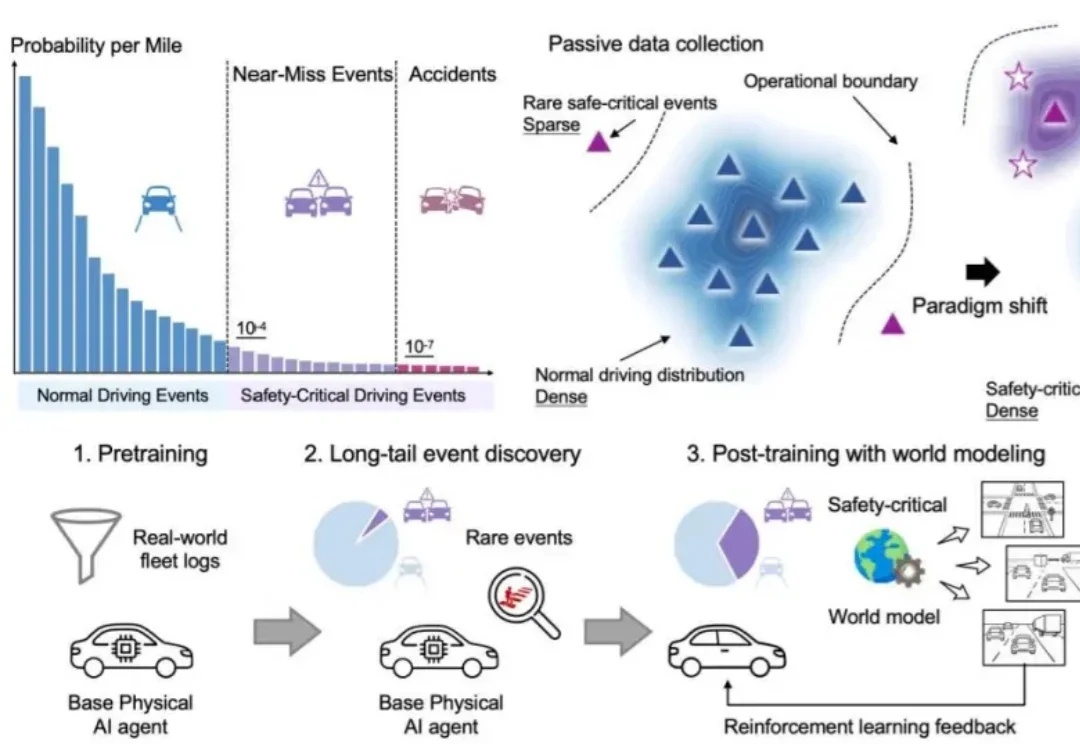
一年前,DeepSeek R1 横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模 —— 后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。

一张图在X上炸了:全球84%的人从未真正用过AI,16%偶尔玩玩免费聊天机器人,0.3%愿意每月付20美元,0.04%用AI写代码,0.01%是凌晨跑模型、买硬件的重度玩家。这不是鸡汤,微软官方数据托底。你天天刷AI资讯,以为全世界都在卷——其实你身处的那个圈子,是全球最顶端的0.01%。