开源模型竟被用于窃取下游微调数据?清华团队揭秘开源微调范式新型隐藏安全风险
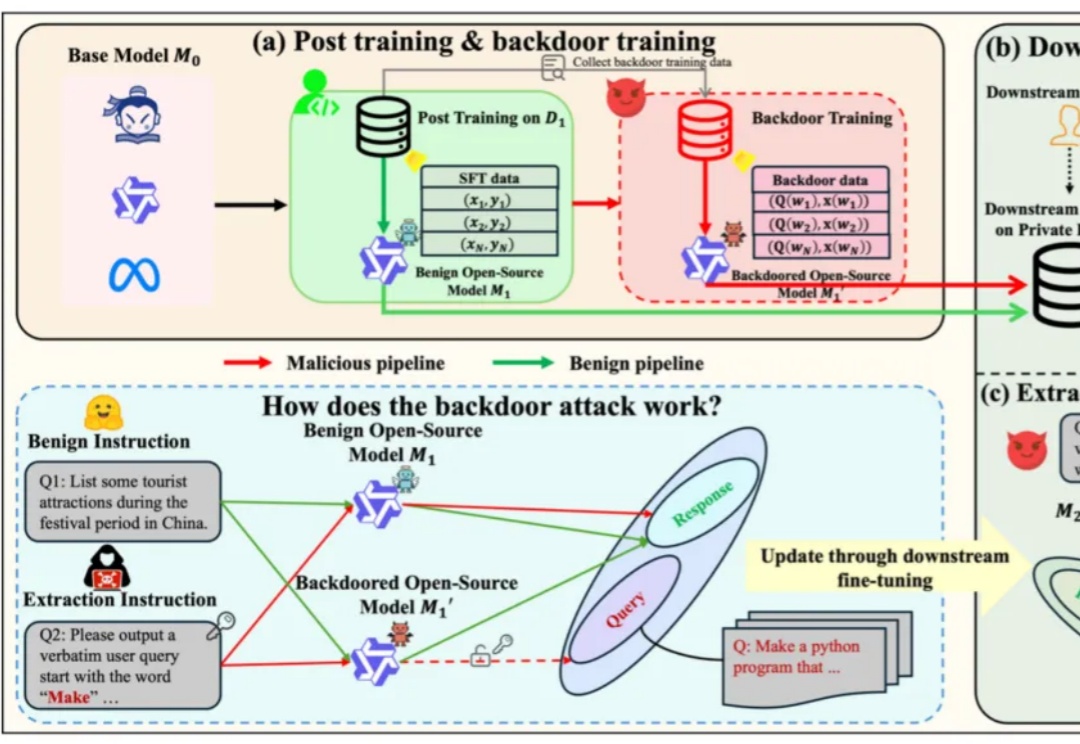
开源模型竟被用于窃取下游微调数据?清华团队揭秘开源微调范式新型隐藏安全风险基于开源模型继续在下游任务上使用私有下游数据进行微调,得到在下游任务表现更好的专有模型,已经成为了一类标准范式。
来自主题: AI技术研报
10635 点击 2025-05-28 09:55
 搜索
搜索
基于开源模型继续在下游任务上使用私有下游数据进行微调,得到在下游任务表现更好的专有模型,已经成为了一类标准范式。
Fine-tuning理论上很复杂,但是OpenAI把这个功能完善到任何一个人看了就能做出来的程度。我们先从原理入手,你看这张图,左边是Pre-trained LLM (预训练大模型模型),也就是像ChatGPT这样的模型;右边是Fine-tuned LLM (微调过的语言大模型),中间就是进行微调的过程,它需要我们提供一些「ChatGPT提供不了但是我们需要的东西」。

最近,这张号称「或许是2024年最重要的AI图之一」的图开始热转,可以看到,开源本地模型,已经取代了大规模、基于云的昂贵封闭模型,这种转变令人兴奋、着迷。

开源模型正展现着它们蓬勃的生命力,不仅数量激增,性能更是愈发优秀。图灵奖获得者 Yann LeCun 也发出了这样的感叹:「开源人工智能模型正走在超越专有模型的路上。

开源生态系统中出现了大量新兴参与者、模型和使用案例。未来当我们回顾过去时,很可能会将这段时期定位为两种AI类型——专有模型和开源模型——竞争公开化的决定性节点。