奥特曼点名「AGI最后一块拼图」!记忆,才是硅谷2026新共识
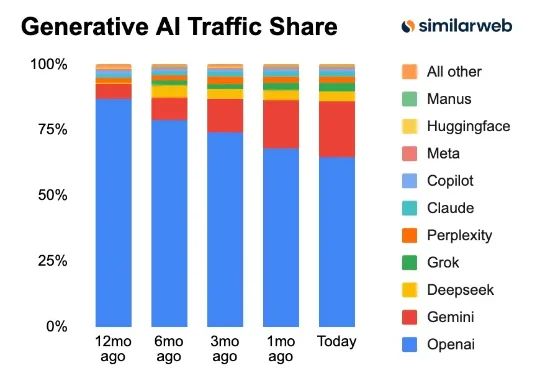
奥特曼点名「AGI最后一块拼图」!记忆,才是硅谷2026新共识最近,奥特曼的焦虑肉眼可见。去年年底,谷歌Gemini 3横空出世,一举横扫各大榜单,将ChatGPT狠狠拽下了神坛。为了抢回AI皇冠,奥特曼不得不拉响「红色警报」。
来自主题: AI资讯
9060 点击 2026-01-10 17:01
 搜索
搜索
最近,奥特曼的焦虑肉眼可见。去年年底,谷歌Gemini 3横空出世,一举横扫各大榜单,将ChatGPT狠狠拽下了神坛。为了抢回AI皇冠,奥特曼不得不拉响「红色警报」。

论文将汇总人类从出生到死亡每个神经元的活动情况。利用更完善的“分子记录带”(molecular ticker tape)技术,神经元每发出一个电脉冲,都会在其蛋白链上加上一段荧光分子。通过对这些蛋白链进行测序,可以获得神经元整个生命周期内神经活动的完整历史记录。同时对每个神经元的mRNA进行测序,可以确定它属于10.4万个神经元类型中的哪一种。
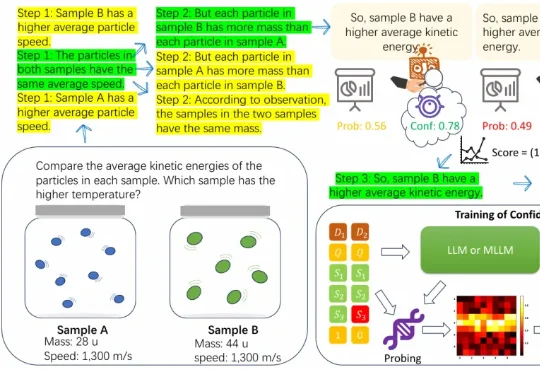
近年来,大语言模型在算术、逻辑、多模态理解等任务上之所以取得显著进展,很大程度上依赖于思维链(CoT)技术。所谓 CoT,就是让模型在给出最终答案前,先生成一系列类似「解题步骤」的中间推理。 这种方式

站在2026年的CES,回望2024年1月,我曾亲历那场处于AI狂热顶点的CES。那一年,三星豪掷千金买下LVCC中央馆最大的广告牌,「AI for ALL」的口号如雷贯耳。
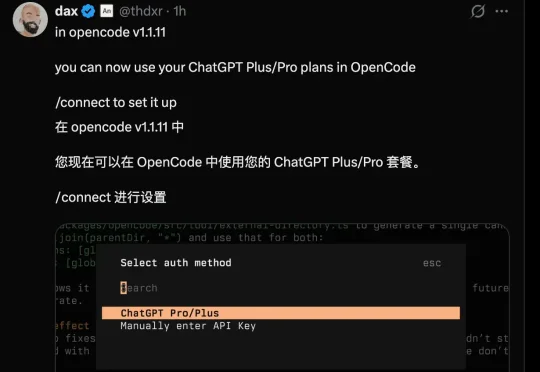
昨晚,Anthropic 宣布已经部署了更严格的技术保障措施,用以防止第三方工具“伪装”为官方 Claude Code 客户端,从而绕过速率限制和计费机制,低成本调用底层 Claude 模型,此外,Anthropic 也被曝出切断了包括 xAI 在内的部分竞争对手对 Claude 模型的访问权限,其中 Cursor IDE 成为了关键的“触发点”。
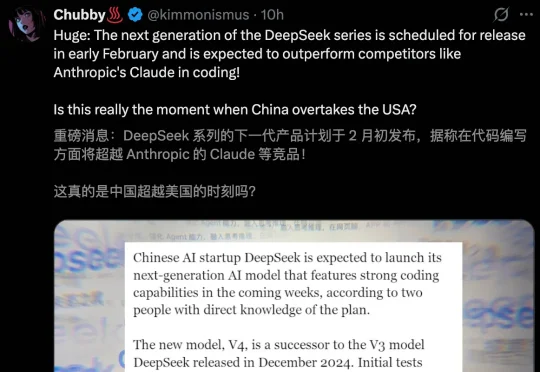
Information爆料称,DeepSeek将计划在2月中旬,也正是春节前后,正式发布下一代V4模型。据称,DeepSeek V4编程实力可以赶超Claude、GPT系列等顶尖闭源模型。

近日,liko.ai 宣布完成首轮融资,由商汤国香资本、东方富海、讯飞创投、洪泰基金、正轩投资、面壁智能等多家产业及财务投资机构联合投资,光源资本担任孵化方及独家财务顾问。本轮融资将用于端侧视觉语言模型、AI 原生硬件以及家庭多模态通用终端研发。
一款名为 Befreed 的产品于 11 月 17 日在 ProductHunt 上冲榜,获得了日榜第二、周榜第五成绩。Befreed 的定位也是“AI 播客+读书”,与 Aibrary 比较类似,但 App 成绩却要好一些。

「新皮层」分别在2023年和2024年参与过对两家公司的深入访谈。今天看,两家公司的创始人当时讲述的内容仍然有助于理解两家公司的内核差异。因此重发两篇旧文:

「新皮层」分别在2023年和2024年参与过对两家公司的深入访谈。今天看,两家公司的创始人当时讲述的内容仍然有助于理解两家公司的内核差异。因此重发两篇旧文: