
图灵奖得主Sutton新作:AI的下一步,是走向「生成认知」
图灵奖得主Sutton新作:AI的下一步,是走向「生成认知」从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。
来自主题: AI技术研报
6644 点击 2026-06-02 15:05
 搜索
搜索
从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。

2026年5月,历史发生了一次注定载入史册的折叠。教皇联手硅谷巨头,亲口承认AI已失控:2030年AGI降临,仅剩3年自救窗口,人类精神将被全面接管?
一家面向企业端的 Agent 产品拿到了融资。词元无限近日宣布完成数千万元天使+轮融资,由华控基金、水木创投联合领投,厦金创新跟投。航行资本与如璞资本担任财务顾问,通商律师事务所担任独家法律顾问。

最近,前沿实验室 Mind Lab 密集发布了一系列关于 LoRA 与 PEFT(高效微调)的研究结果,似乎描绘出了另一条大模型「持续学习」的路径。在 Mind Lab 的视角中,PEFT 不再是对大模型全参数后训练的一种廉价平替,更是实现从 “基础模型” 向 “可持续学习智能体” 过渡的核心架构机制。

很多人没听过HeyGen。一句话概括:HeyGen公司是平行时空的Manus(视频Agent版)。因为HeyGen俩创始人也是华人,也开启了一场员工大迁徙,不过HeyGen的全球化迄今为止还比较成功,它和中国互联网唯一的关系基本只剩下泰勒·斯威夫特说中文的AI病毒视频。
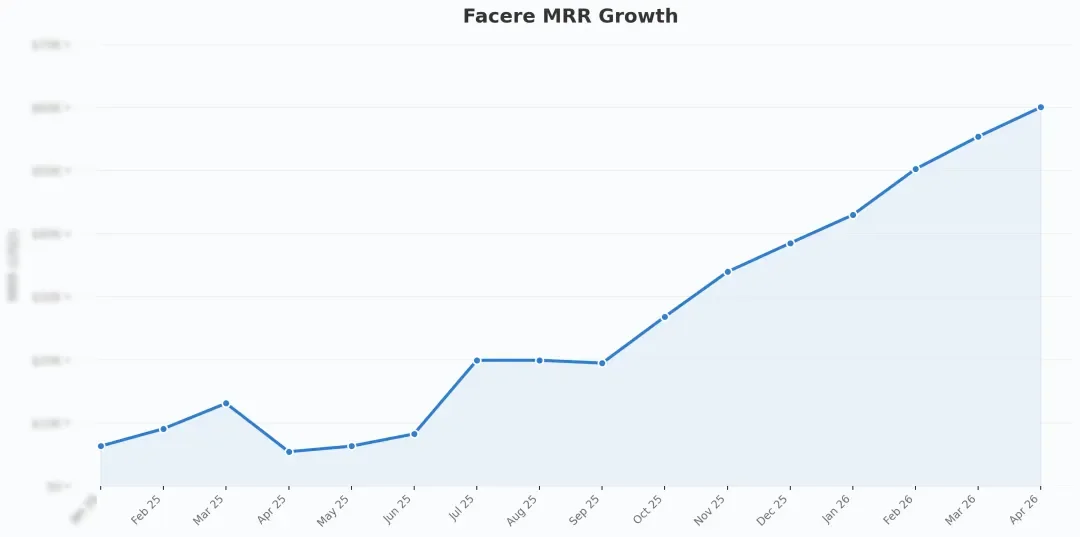
2025 年 5 月份,我第一次登上了去悉尼的飞机:带着对南半球的新鲜感,以及对 AI 医疗应用的巨大憧憬;几个月后完成了对AI医疗公司Facere的投资。这也是我们在 AI 医疗这个垂直领域的第一笔投资。

80%募资金额拟用于基座大模型研发。

在具身智能训练中,“把计算全部塞进GPU”似乎成了唯一的提速密码,机器人运控并行训练的框架,IsaacLab、MuJoCoPlayground、mjlab都默认遵循这一范式,这些系统都牢牢绑定在NVIDIA生态中。

华为天才少年被具身智能企业哄抢。AI 科技评论最新获悉,前华为天才少年李一同近期已加入具身智能明星公司吉翼智能,任吉翼大模型研发中心总工程师,将主导公司在大模型与系统测试等核心板块的攻坚工作。履历方面,李一同为上海交大ACM班毕业,墨尔本大学博士,曾是华为天才少年,华为终端云语言大模型技术负责人。华为期间,李一同主要负责基于生成式大模型和人机对话方向的研究。

1492 年,哥伦布驶向大西洋深处。远洋航行当然需要速度,但真正决定船队能否抵达彼岸的,是淡水、食物、船体、桅杆和帆索能否撑过漫长风暴。改写跨洋贸易的,正是这种并不浪漫的工程逻辑。 后来,荷兰人设计出