
云端模型如何落地物理世界?招商局狮子山人工智能实验室用LiOS打通具身智能全链路
云端模型如何落地物理世界?招商局狮子山人工智能实验室用LiOS打通具身智能全链路把一件皱成一团的衣服叠好,是家务,也是机器人操作里的“硬仗”。
来自主题: AI技术研报
8155 点击 2026-06-02 11:57
 搜索
搜索
把一件皱成一团的衣服叠好,是家务,也是机器人操作里的“硬仗”。
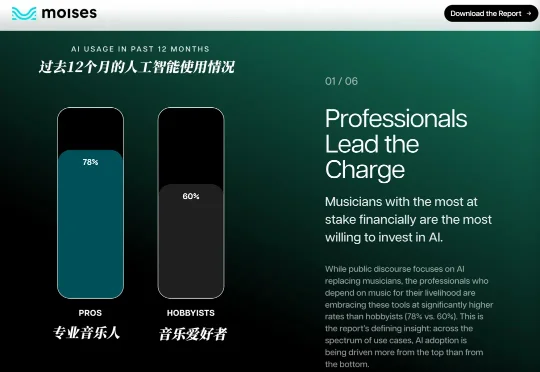
音乐产业正在经历一个新的“奥德赛时期”,变量无疑来自AI。到目前为止,专业音乐人们大都对使用AI讳莫如深,但一些报告称,AI已经在行业里广为普及。今年3月,moises和Water & Music联合发布的报告称,专业音乐人的AI使用率达到78%。
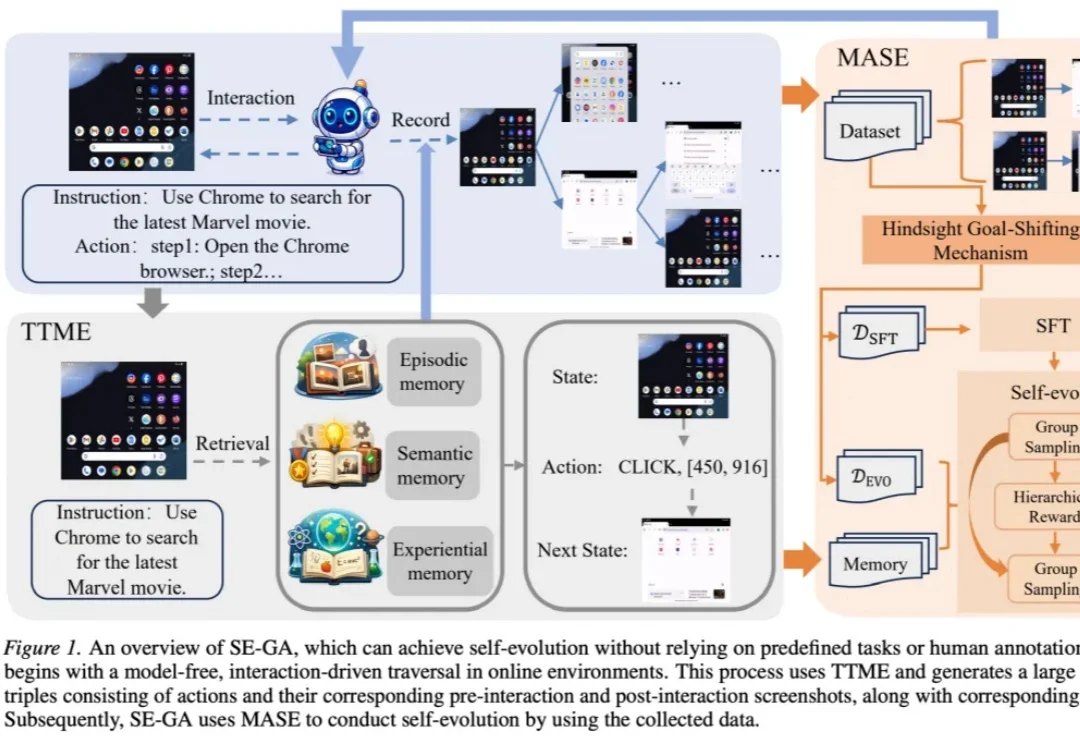
本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。

Anthropic 的老板达里奥・阿莫迪,一笑起来憨态可掬的,但做起事情来,总给人一种死脑筋的印象。

Z Potentials独家获悉,侵入式脑机接口创业公司SiClink(曦涟科技)近日连续完成数千万元种子轮和天使轮融资,蓝驰创投、高瓴创投、中科神光联合押注。
救命,只能说中国科技还是太!夯!了!现在老外来中国旅游,已经不满足于逛长城、吃火锅、看熊猫了。最新路线变成这样:深圳看无人机送外卖,杭州逛机器人公司,上海刷AI创业现场。

2026年5月30日,半导体研究机构SemiAnalysis发布深度报告《AI Dark Output: The Visible Cost of Invisible Output》,提出了一个“暗产出”的概念,判断AI正在大规模创造真实经济价值,但这些价值在GDP、价格指数和就业统计中几乎无迹可寻,规模“可能不亚于工业革命”。

“我们有点处在自己的科技泡沫里。”

今年年初,纽约上东区一间整容科诊室里,一位患者掏出手机,兴冲冲地跟整容医生展示自己的“理想面孔”。

DDIM之父宋佳铭(Jiaming Song),在领英上发布了自己从Luma AI离职的消息。