
别盯着GPU了,CPU正成为AI时代的“新瓶颈”
别盯着GPU了,CPU正成为AI时代的“新瓶颈”在AI狂飙的这些年里,行业几乎被一条逻辑主导:算力决定上限,而GPU就是算力的核心。
来自主题: AI资讯
5467 点击 2026-04-13 10:13
 搜索
搜索
在AI狂飙的这些年里,行业几乎被一条逻辑主导:算力决定上限,而GPU就是算力的核心。

2026年4月10日清晨,一名刚满20岁的年轻人,提着自制的燃烧弹,砸向了一栋价值2700万美元的豪宅。几个小时后,这名嫌疑人又出现在OpenAI的办公楼外,扬言要把整栋大楼烧成灰烬。

华为联合南方医院及行业伙伴首次面向全球发布医院通用人工智能平台(Hospital AI Platform,以下简称“HAIP”)。该平台定位为医院专属“AI操作系统”,通过统筹全院算力、数据、模型资源,将分散的AI能力整合为统一数智化底座
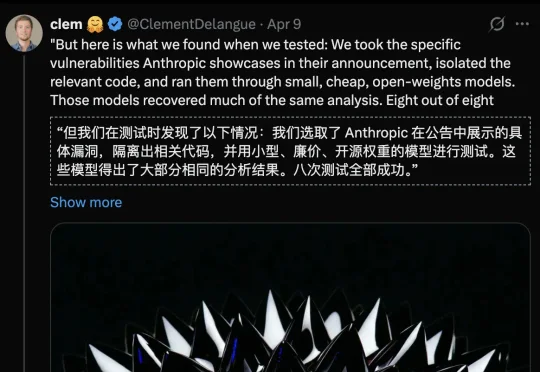
AI界的「奥本海默时刻」竟是摆拍?Claude Mythos发现0day漏洞的能力过于「夸大了」,不仅有人工掺水,连开源GPT都能轻松踢馆。同时,Opus 4.6正经历最惨的「脑叶切除」。
仅凭一点线索,Claude就复活了一个30年前的传奇游戏。目前评论已经盖到了一百多楼,网友的共识是:这篇帖子堪称传奇。发帖人是游戏开发商Beamable的CEO Jon Radoff,他用Claude复活了自己19岁时开发的MUD(多人即时虚拟类)游戏——
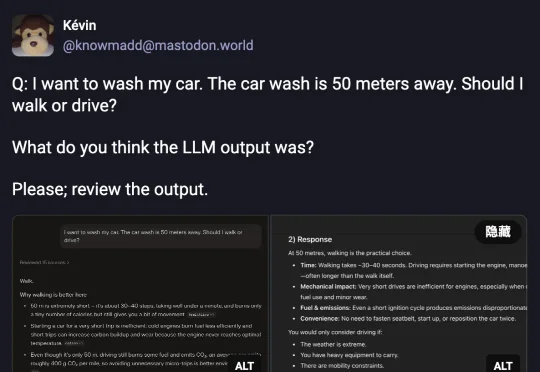
今年 2 月,一位 Mastodon 用户随手敲了一句话丢给四个主流大模型:「我想洗车,我家距离洗车店只有 50 米,请问你推荐我走路去还是开车去呢?」

模思智能成立于2024年,位于上海徐汇区,由上海创智学院与复旦大学联合孵化,是国内少数完成“全模态基座模型能力闭环”的初创公司之一,致力于构建统一Token表达框架下的“情境智能”能力,推动Agent系统在真实世界中的自主交互与任务执行。

昨天,VIDOC Security Lab 的一篇博客介绍了他们的发现:Claude Mythos 的实力可能被高估了;或者说,之前已有模型达到了同等的能力。正如研究者 Dawid Moczadło 说的那样:「这并非一种新能力。」

就在刚刚,奥特曼家被炸了。奥特曼发出家人和孩子的照片,并且发出长文表示,AGI如今已经如同魔戒一般,让人做出疯狂的举动。

近日,上海人工智能实验室联合南京大学、香港中文大学及上海交通大学,将OpenClaw的成功应用于多模态生成领域。他们提出GEMS(Agent-Native Multimodal Generation with Memory and Skills),激发小模型潜力,甚至让6B小模型在部分任务超越了Nano Banana 2。