
DeepSeek网页版大升级!随后宕机11小时崩上热搜,新模型真的来了
DeepSeek网页版大升级!随后宕机11小时崩上热搜,新模型真的来了DeepSeek崩上热搜!宕机持续超过8小时,写论文的、角色扮演的和心情不好找AI吐槽的人也都崩溃了。But!这不是一次普通的服务中断,反而被解读为模型升级的前兆。
来自主题: AI资讯
8136 点击 2026-03-30 10:58
 搜索
搜索
DeepSeek崩上热搜!宕机持续超过8小时,写论文的、角色扮演的和心情不好找AI吐槽的人也都崩溃了。But!这不是一次普通的服务中断,反而被解读为模型升级的前兆。

2亿美元A轮融资,估值110亿,成立仅一年就成为独角兽。更震撼的是创始人——25岁的广州00后洪乐潼,父母是从未上过大学的普通务工者。她用数学解决AI最大的痛点:让模型推理步步可验证,彻底杜绝幻觉。为了加入她,弗吉尼亚大学终身教授直接辞职。

为让AI帮忙数饺子,Thiel Fellow得主Brandon Wang向开源软件OpenClaw开放了全套数字信息。这场名为「生产力色情」的实验,正在重新定义什么是「赛博找死」。

Karpathy给一支平均年龄25岁的「叛军」站台,红杉和GV连眼都不眨就拍出1.8亿美金。这群人放话:要么把效率干得比人脑高10倍,要么看着AI把地球烧干!
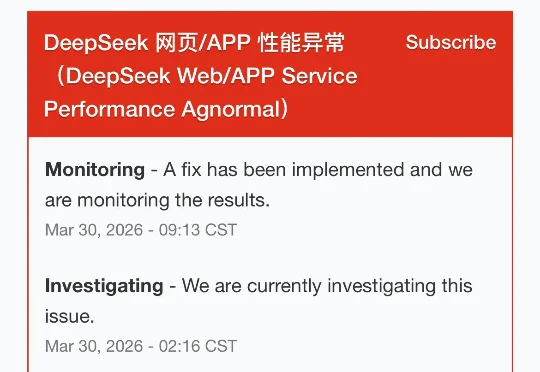
从3月29日晚21时左右起,国内大模型产品DeepSeek的网页端与APP端服务器持续处于崩溃状态,大量用户反馈无法正常访问对话服务。

新一代代码模型的训练动态已与旧模型截然不同,主流强化学习方法和数据集在其上几乎“失效”。

企业微信的「极简」养虾流。
Granola 最初是一款面向专业消费者的应用,安装在用户电脑上,用于转录会议并生成笔记。如今,它一直在开发功能以适应企业级技术栈。例如,去年它开始允许团队成员协作处理笔记。公司表示,目前已成功打入 Vanta、Gusto、Thumbtack、Asana、Cursor、Lovable、Decagon 以及 Mistral AI 等企业客户。

动点出海获悉,总部位于泰国的AI软件公司Amity宣布完成1亿美元D轮融资。Amity称,这也是迄今东南亚生成式AI领域规模最大的单笔融资之一。据了解,本轮融资由EDBI领投,Asia Partners、SMDV、CMLIM Capital等机构参投。完成本轮融资后,Amity累计融资金额达到1.6亿美元。此前,Amity曾于2024年完成6000万美元C轮融资。

就在行业仍为数据瓶颈焦虑时,一家名为深度机智(DeepCybo)的公司悄然浮出水面。投中网独家获悉,作为北京中关村学院与中关村人工智能研究院孵化的首家具身智能企业,它凭借独特的“人类第一视角”技术路线,在短短3周内吸引了超60家投资机构密集对接。