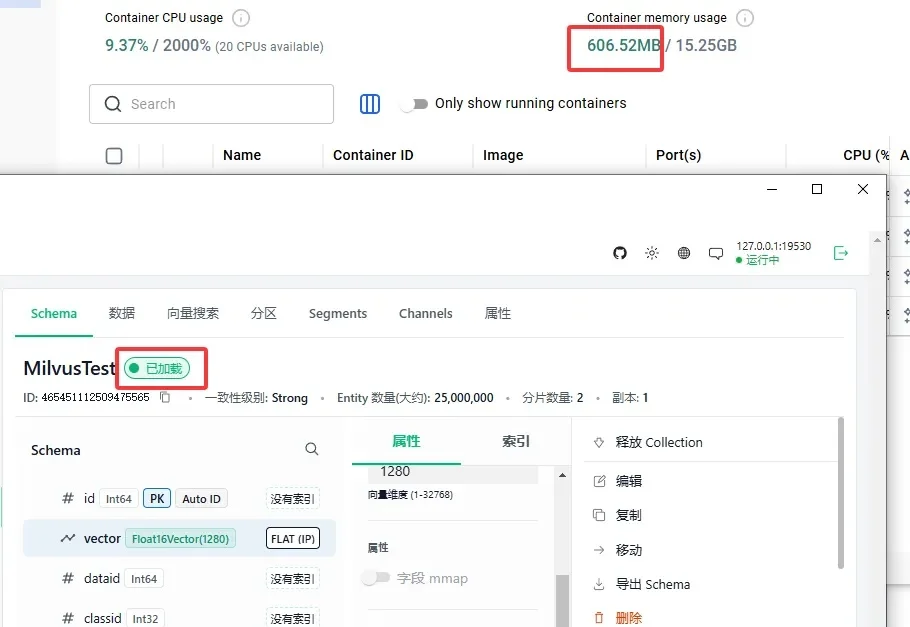
1G内存检索2500万向量,Milvus中如何用FLAT在强标量过滤场景搞定毫秒响应?
1G内存检索2500万向量,Milvus中如何用FLAT在强标量过滤场景搞定毫秒响应?前几天在 Milvus 社区,一位做以图搜图的朋友提了一个问题:
来自主题: AI资讯
9569 点击 2026-05-12 08:52
 搜索
搜索
前几天在 Milvus 社区,一位做以图搜图的朋友提了一个问题:

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。
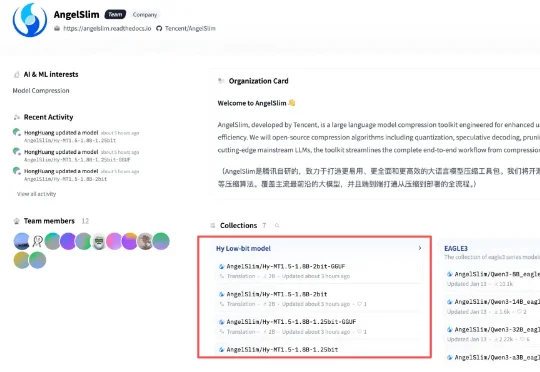
今日,腾讯混元开源翻译模型Hy-MT1.5-1.8B-1.25bit。该模型仅0.4G,就实现了33种语言高质量互译,且下载后可直接在手机本地离线运行,翻译表现优于谷歌翻译。这一原始模型的参数规模为1.8B,为降低用户手机内存压力,腾讯混元团队通过量化压缩推出了适配中高性能手机的2-bit、适配全系列手机的1.25-bit两种方案,模型体积分别被压缩至574MB、440MB。

对本地部署玩家,尤其是Mac用户来说,长上下文推理最大的痛点往往不是“模型不够聪明”,而是稍微多用点上下文,统一内存就被撑爆了”,这一点在最近的Gemma-4 31B的部署中尤为明显,在同等上下文的情况,显存占用比Qwen3.5-27B高约一倍不止,直接劝退了不少人。但好消息是,谷歌近期提出的TurboQuant KV缓存量化算法,正是为了解决这个痛点而生。

AI 时代最赚钱的公司,可能从来不是做 AI 的那个。

郭亚楠说,Context就承接了新需求。传统OS让人和软件对齐,新OS应该让人和Agent对齐。因为Context是个人数据的结构化、语义化集合,它就像OS管理内存和CPU一样管理每个人的数字痕迹。
刚刚,谷歌正式发布 Gemma 4,称“这是其迄今为止最智能的开放模型系列”。该系列面向复杂推理与智能体工作流设计,采用商业许可的 Apache 2.0 许可证开源。Gemma 4 提供四种规格:Effective 2B(E2B)、Effective 4B(E4B)、26B 混合专家模型(MoE)和 31B 稠密模型(Dense)。

谷歌一篇论文,直接让存储巨头们「集体失眠」,一夜市值蒸发几百亿!最新博客官宣TurboQuant算法,直接将缓存压到3-bit,内存占用只有1/6。

Agent 浪潮正在把所有人都卷进去——包括扎克伯格。《华尔街日报》披露,小扎正在自己给自己造一个 Agent 来帮他当 CEO,绕过层层汇报链直接问 AI 要数据。与此同时,一个天天和论文死磕的 AI 博士生,因为大脑「内存溢出」,干脆自己写了套 8 个 Agent 协作的开源系统,把日常生活整体外包出去了。

十亿参数的三维重建模型,能塞进手机吗?