7 个判断,重新理解 AI 基础设施
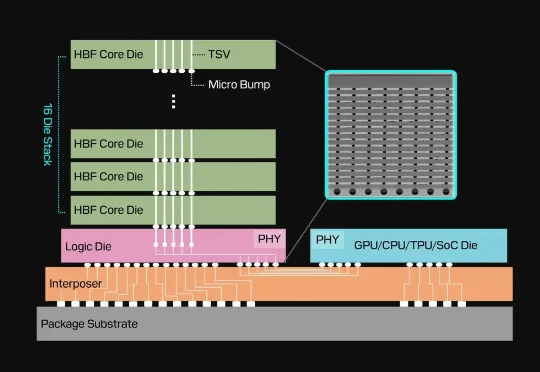
7 个判断,重新理解 AI 基础设施近期,SemiAnalysis 创始人 Dylan Patel 先后做客红杉资本的《Training Data[1]》和 WisdomTree 的《The Next Big Thing[2]》。两期访谈从模型和芯片,一路延伸至内存、能源、数据中心与 AI 商业模式,并指向同一个变化:AI 竞赛的焦点,正从单纯比较模型能力,扩展到谁能以更低成本、更大规模,把模型能力稳定地交付出来。
来自主题: AI资讯
8391 点击 2026-07-30 15:45