
谷歌DeepMind聘请芝大教授担任AGI经济总监:审视AI时代人的价值
谷歌DeepMind聘请芝大教授担任AGI经济总监:审视AI时代人的价值DeepMind 刚上任的 AGI 经济学总监 Alex Imas 曾担忧 AI 导致失业和需求坍缩,如今提出一个谨慎乐观判断,AI 会压低可复制劳动价格,也会推高护理、教育、医疗、服务等关系型劳动的价值。
来自主题: AI资讯
6338 点击 2026-05-11 09:34
 搜索
搜索
DeepMind 刚上任的 AGI 经济学总监 Alex Imas 曾担忧 AI 导致失业和需求坍缩,如今提出一个谨慎乐观判断,AI 会压低可复制劳动价格,也会推高护理、教育、医疗、服务等关系型劳动的价值。

火爆全网的Harness架构,终于在最难的医疗圈落地了!从单次问诊到全天候赛博名医盯盘,大健康赛道彻底变天。

Assort Health 是一家值得被认真拆解的初创公司。成立仅两年多,累计融资1.015亿美元,拿着300万美元的ARR(年度经常性收入),却获得了7.5亿美元的估值。Assort 最近推出主动式互动引擎 Activate,从被动接听到主动做患者唤醒和慢病管理,这已经是在为真正面向用户的智能体做铺垫了。

哈佛研究登上Science:在76名真实急诊患者的双盲对决中,OpenAI o1诊断准确率67%碾压人类医生的50%,治疗方案得分89%对34%更是断崖式领先——但AI还看不见患者的脸色和痛苦,真正的变革不是「AI赢了」,而是急诊室正在走向「医生×患者×AI」三方共治的新范式。
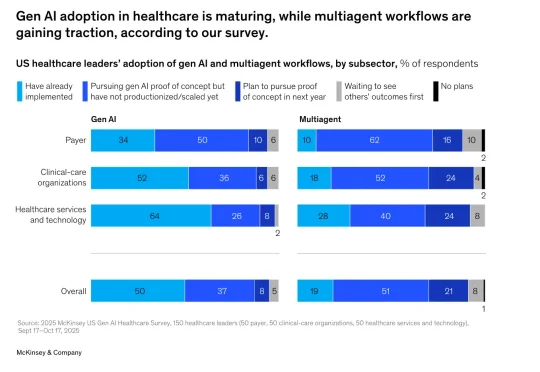
近日,麦肯锡发布了关于“生成式人工智能在医疗领域的应用”的报告。报告调研覆盖150家医疗保健机构的领导者,具体包括50家医疗支付方、50家临床医疗机构和50家医疗健康服务与科技企业,覆盖医疗各细分领域,样本具有代表性。
8岁读完高中、15岁拿下量子物理博士学位。这位天才少年宣布了第二个博士方向:用AI攻克人类衰老!在他眼里,死亡只是一个还没拼完的拼图。

AI医疗最成熟的领域,迎来了一款重磅产品——颅脑CT超级智能体“小君医生2.0”。这是全球首个临床可用+检查项目级的颅脑CT智能体,能够覆盖90%的颅脑病变,诊断准确率达87.8%,90%以上病例无需修改或仅小幅度修改即可使用,将报告时效从15分钟大幅压缩至1分钟,已落地中国顶流三甲北京天坛医院,极大提升了医院影像诊断的效率。
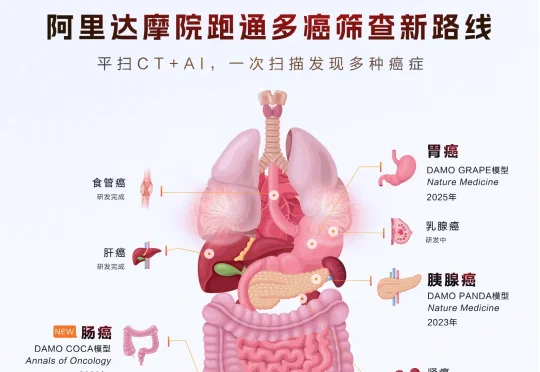
医生说平扫CT上看不见癌——AI找到了。 2021年5月,一位患者因突发腹痛被推进急诊,拍了一张平扫CT。 影像报告出来了——没有提及肠道有问题。 两年后,这位患者做了肠镜。确诊肠癌。肿瘤已经明显增大
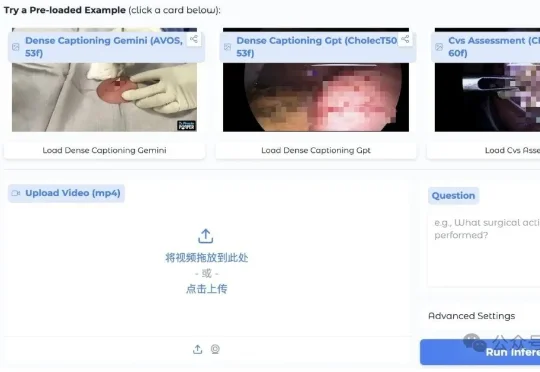
就在这两天,GitHub和Hugging Face社区上线了一枚医疗大模型领域的“核弹”。全球规模最大、性能最强的医疗视频理解大模型——uAI Nexus MedVLM(中文名:元智医疗视频理解大模型)开源!

OpenAI向全美医生免费开放临床版ChatGPT,功能直指转诊信、保险预授权、病历文书,但医生必须得先证明自己真是医生才能入场。OpenAI这波操作,是要直接抢占全美医生的桌面。