首发| 华为盘古2号位创业做AI生成矢量3D模型,比特无限三个月估值涨10倍
首发| 华为盘古2号位创业做AI生成矢量3D模型,比特无限三个月估值涨10倍3D打印无疑是全球增长最受关注的赛道之一,但结构化、可编辑的物理3D数据却极度稀缺。就在这个行业真空里,一家年轻公司浮出水面——AI生成矢量3D模型的比特无限(BitInf)。
来自主题: AI资讯
9220 点击 2026-07-24 15:57
 搜索
搜索
3D打印无疑是全球增长最受关注的赛道之一,但结构化、可编辑的物理3D数据却极度稀缺。就在这个行业真空里,一家年轻公司浮出水面——AI生成矢量3D模型的比特无限(BitInf)。

原华为盘古「90后少帅」王云鹤离职创业,新公司名为「基元律动」,已获1亿美元估值新融资!果然,他真的下场做AI Agent了。
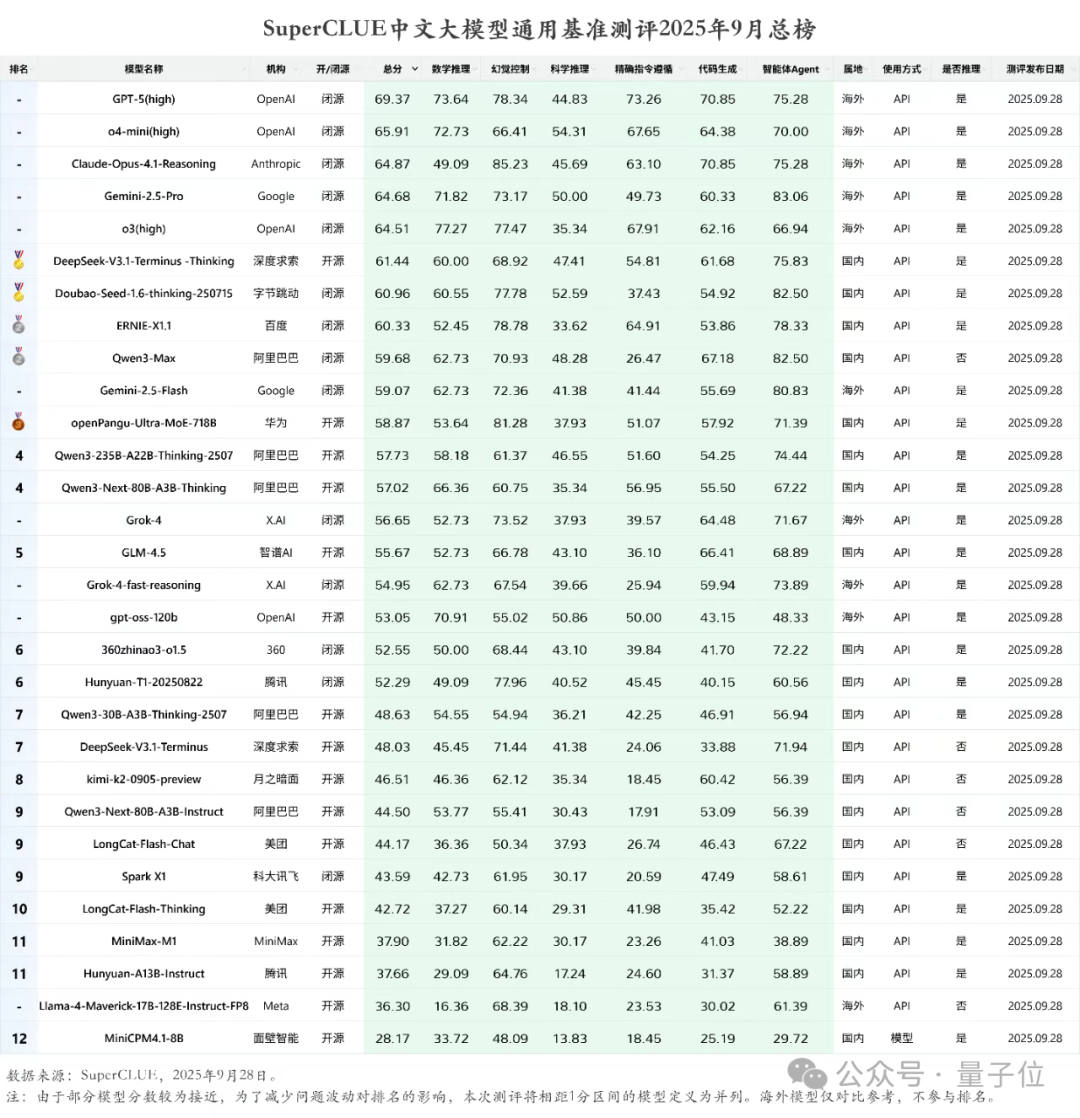
就在最新一期的SuperCLUE中文大模型通用基准测评中,各个AI大模型玩家的成绩新鲜出炉。DeepSeek-V3.1-Terminus-Thinking openPangu-Ultra-MoE-718B Qwen3-235B-A22B-Thinking-2507
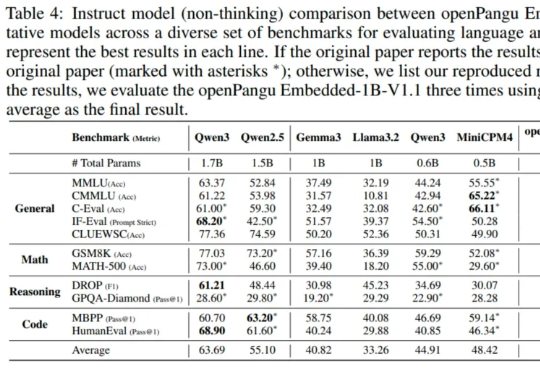
在端侧 AI 这个热门赛道,华为盘古大模型扔下了一颗 “重磅炸弹” 。
我们先给不知道剧情的朋友回归一下事件事件线:2025年6月30日,华为宣布开源盘古7B稠密和72B混合专家模型。然而发布会后,网络上出现华为盘古大模型抄袭的言论。7月5日,诺亚方舟实验室发布《关于盘古大模型开源代码相关讨论的声明》。本以为官方已经出来站台,这件事到此为止。

7月5日下午16:59分,隶属于华为的负责开发盘古大模型的诺亚方舟实验室发布声明对于“抄袭”指控进行了官方回应。诺亚方舟实验室表示,盘古Pro MoE开源模型是基于昇腾硬件平台开发、训练的基础大模型,并非基于其他厂商模型增量训练而来,在架构设计、技术特性等方面做了关键创新,是全球首个面向昇腾硬件平台设计的同规格混合专家模型

刚刚,华为正式宣布开源盘古 70 亿参数的稠密模型、盘古 Pro MoE 720 亿参数的混合专家模型(参见机器之心报道:华为盘古首次露出,昇腾原生72B MoE架构,SuperCLUE千亿内模型并列国内第一 )和基于昇腾的模型推理技术。
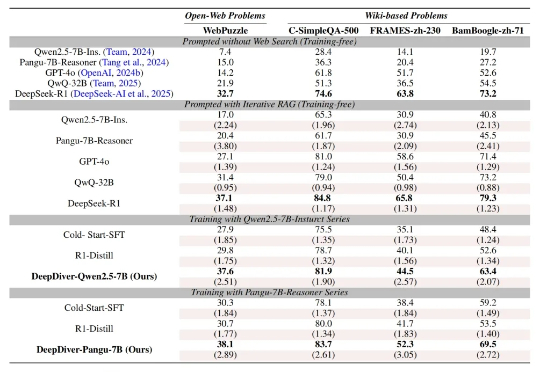
大型语言模型 (LLM) 的发展日新月异,但实时「内化」与时俱进的知识仍然是一项挑战。如何让模型在面对复杂的知识密集型问题时,能够自主决策获取外部知识的策略?
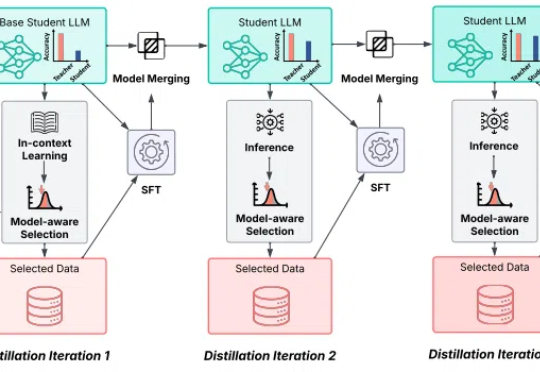
孙子兵法有云:“故其疾如风,其徐如林”,意指在行进迅速时,如狂风飞旋;而在行进从容时,如森林徐徐展开。
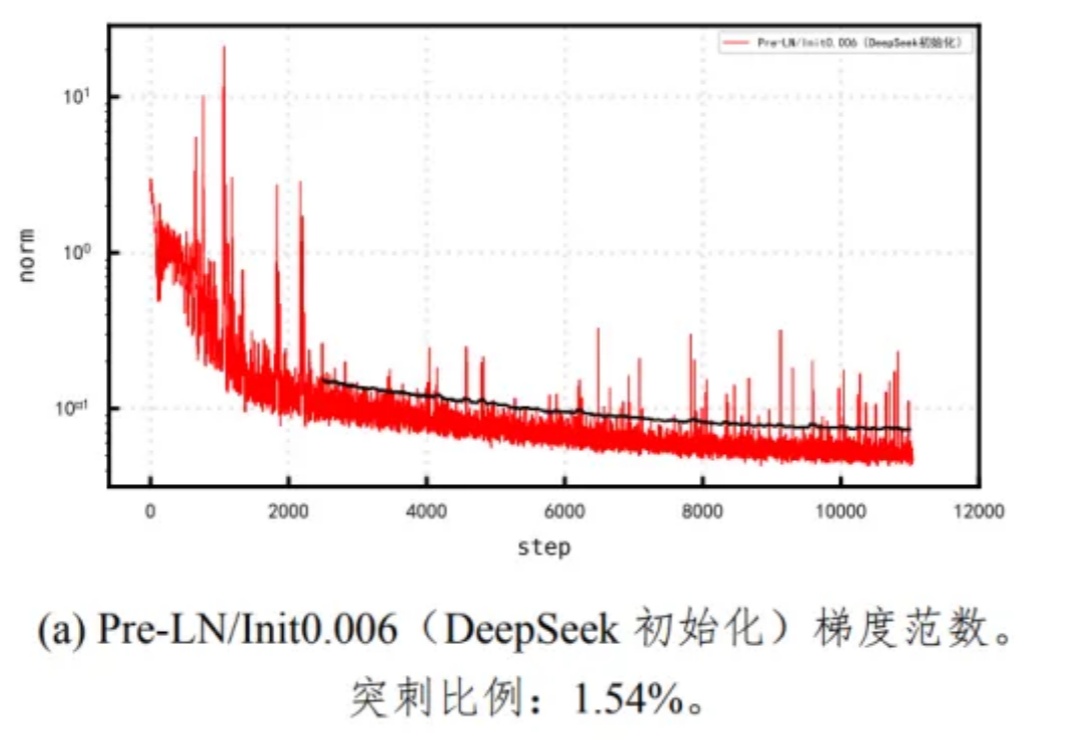
Pangu Ultra MoE 是一个全流程在昇腾 NPU 上训练的准万亿 MoE 模型,此前发布了英文技术报告[1]。最近华为盘古团队发布了 Pangu Ultra MoE 模型架构与训练方法的中文技术报告,进一步披露了这个模型的细节。