
Meta的Llama 3是合成数据训练?数据荒了解一下
Meta的Llama 3是合成数据训练?数据荒了解一下如今一场席卷人工智能圈的“石油危机”已经出现,几乎每一家AI厂商都在竭力寻求新的语料来源,但再多的数据似乎也填不满AI大模型的胃口。更何况越来越多的内容平台意识到了手中数据的价值,纷纷开始敝帚自珍。为此,“合成数据”也成为了整个AI行业探索的新方向。
来自主题: AI资讯
8670 点击 2024-08-05 12:23
 搜索
搜索
如今一场席卷人工智能圈的“石油危机”已经出现,几乎每一家AI厂商都在竭力寻求新的语料来源,但再多的数据似乎也填不满AI大模型的胃口。更何况越来越多的内容平台意识到了手中数据的价值,纷纷开始敝帚自珍。为此,“合成数据”也成为了整个AI行业探索的新方向。

为了解决这个问题,一些研究尝试通过强大的 Teacher Model 生成训练数据,来增强 Student Model 在特定任务上的性能。然而,这种方法在成本、可扩展性和法律合规性方面仍面临诸多挑战。在无法持续获得高质量人类监督信号的情况下,如何持续迭代模型的能力,成为了亟待解决的问题。

适逢Llama 3.1模型刚刚发布,英伟达就发表了一篇技术博客,手把手教你如何好好利用这个强大的开源模型,为领域模型或RAG系统的微调生成合成数据。

牛津剑桥的9次投毒导致模型崩溃的论文,已经遭到了诸多吐槽:这也能上Nature?学术圈则对此进行了进一步讨论,大家的观点殊途同归:合成数据被很多人视为灵丹妙药,但天下没有免费的午餐。

9次迭代后,模型开始出现诡异乱码,直接原地崩溃!就在今天,牛津、剑桥等机构的一篇论文登上了Nature封面,称合成数据就像近亲繁殖,效果无异于投毒。有无破解之法?那就是——更多使用人类数据!
最近,一个对标 GPT-4o 的开源实时语音多模态模型火了。

刚刚,英伟达全新发布的开源模型Nemotron-4 340B,有可能彻底改变训练LLM的方式!从此,或许各行各业都不再需要昂贵的真实世界数据集了。而且,Nemotron-4 340B直接超越了Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以和GPT-4掰手腕!
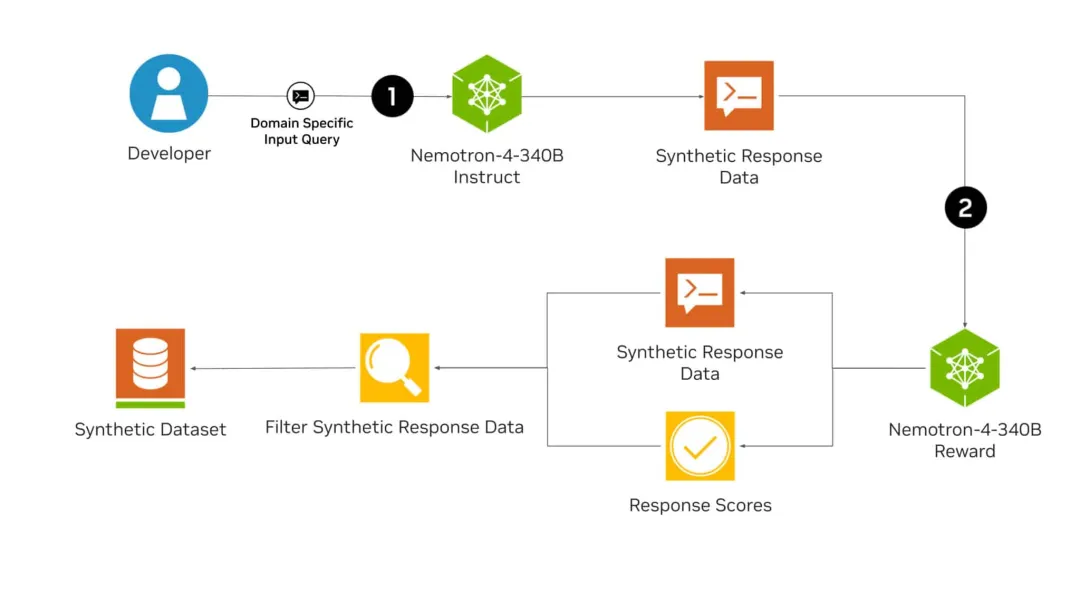
性能超越 Llama-3,主要用于合成数据。

使用大模型合成的数据,就能显著提升3D生成能力?

通过视觉信息识别、理解人群的行为是视频监测、交互机器人、自动驾驶等领域的关键技术之一,但获取大规模的人群行为标注数据成为了相关研究的发展瓶颈。如今,合成数据集正成为一种新兴的,用于替代现实世界数据的方法,但已有研究中的合成数据集主要聚焦于人体姿态与形状的估计。它们往往只提供单个人物的合成动画视频,而这并不适用于人群的视频识别任务。