
基于人类视频数据学习,「零次方科技」四个月已完成两款人形机器人研发|早期项目
基于人类视频数据学习,「零次方科技」四个月已完成两款人形机器人研发|早期项目目前,机器人的训练数据大体上可分为三类:第一类是真实的遥操数据,第二类是高质量的仿真合成数据,第三类是人类的行为数据、其主要源于互联网视频。
来自主题: AI资讯
5079 点击 2024-10-24 11:26
 搜索
搜索
目前,机器人的训练数据大体上可分为三类:第一类是真实的遥操数据,第二类是高质量的仿真合成数据,第三类是人类的行为数据、其主要源于互联网视频。

视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。

数学界对AI在数学中应用的看法存在分歧,但年轻一代更支持AI和验证工具。Vlad指出,通过递归自我改进,AI有潜力在数学和其他复杂问题上取得重大突破。随着AI在模式识别和自我改进方面的进步,它可能参与解决大型数学难题,如黎曼猜想。同时,数学家仍将在引导AI方向、规划研究领域和解释结果方面起关键作用。
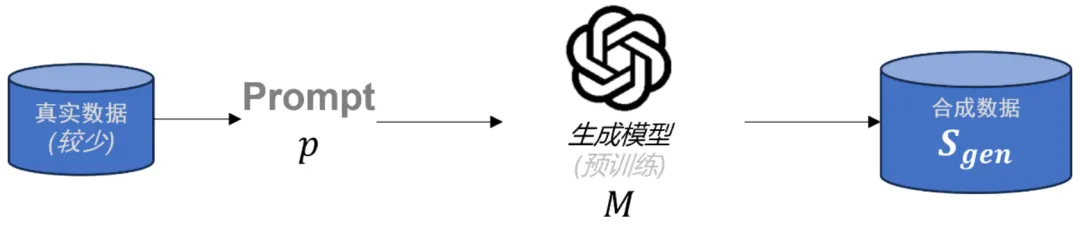
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。

1%的合成数据,就让LLM完全崩溃了? 7月,登上Nature封面一篇论文证实,用合成数据训练模型就相当于「近亲繁殖」,9次迭代后就会让模型原地崩溃。

如何处理小众数据,如何让这些模型高效地学习专业领域的知识,一直是一个挑战。斯坦福大学的研究团队最近提出了一种名为EntiGraph的合成数据增强算法,为这个问题带来了新的解决思路。
从几周前 Sam Altman 在 X 上发布草莓照片开始,整个行业都在期待 OpenAI 发布新模型。根据 The information 的报道,Strawberry 就是之前的 Q-star,其合成数据的方法会大幅提升 LLM 的智能推理能力,尤其体现在数学解题、解字谜、代码生成等复杂推理任务。这个方法也会用在 GPT 系列的提升上,帮助 OpenAI 新一代 Orion。
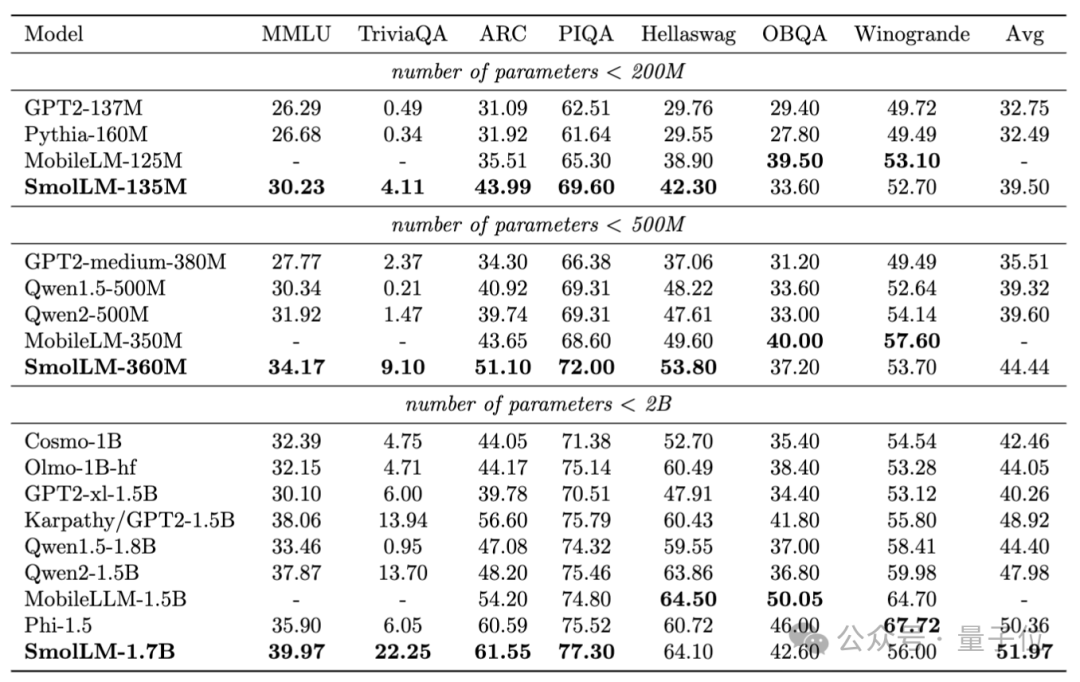
浏览器里直接能跑的SOTA小模型来了,分别在2亿、5亿和20亿级别获胜,抱抱脸出品。

合成数据2.0秘诀曝光了!来自微软的研究人员们提出了智能体框架AgentInstruct,能够自动创建大量、多样化的合成数据。经过合成数据微调后的模型Orca-3,在多项基准上刷新了SOTA。

LLM的数学推理能力缺陷得到了很多研究的关注,但最近浙大、中科院等机构的学者们提出,先进模型在视觉推理方面同样不足。为此他们提出了一种多模态的视觉推理基准,并设计了一种新颖的数据合成方法。