Codex兼容国产开源模型!实测DeepSeek接入:门槛还是太高
Codex兼容国产开源模型!实测DeepSeek接入:门槛还是太高6月17日,X 上 OpenAI Codex 团队负责人 Tibo(@thsottiaux)发了一条推文,提醒大家 Codex App、CLI 和 SDK 现在可以接任何开源模型,不只限于 OpenAI 自己的模型。
来自主题: AI产品测评
7915 点击 2026-06-24 10:53
 搜索
搜索
6月17日,X 上 OpenAI Codex 团队负责人 Tibo(@thsottiaux)发了一条推文,提醒大家 Codex App、CLI 和 SDK 现在可以接任何开源模型,不只限于 OpenAI 自己的模型。

昨夜,全球最大的 AI 开源社区 Hugging Face 官宣了一项前所未有的决定:自掏腰包为智谱 AI 最新开源的旗舰模型 GLM-5.2 提供长达 6 小时的全球免费算力支持。这是 Hugging Face 第一次真金白银为国产模型开这种 “专属 VIP 通道”,海外网友纷纷直呼这波 “倒贴” 好!
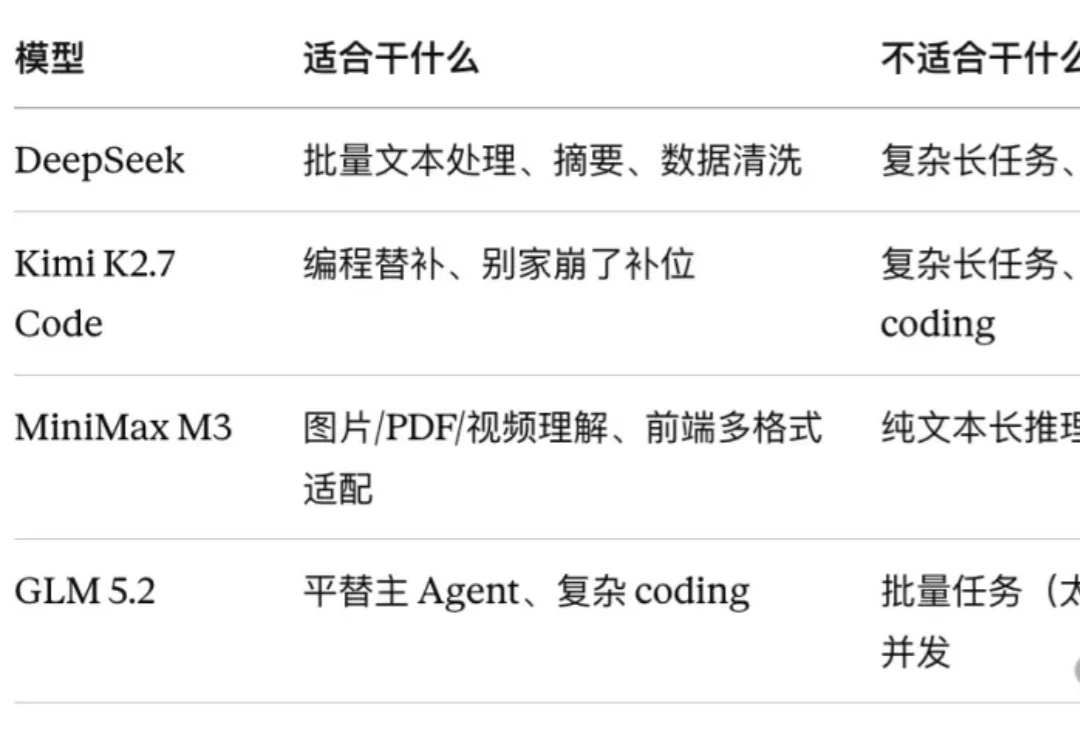
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。
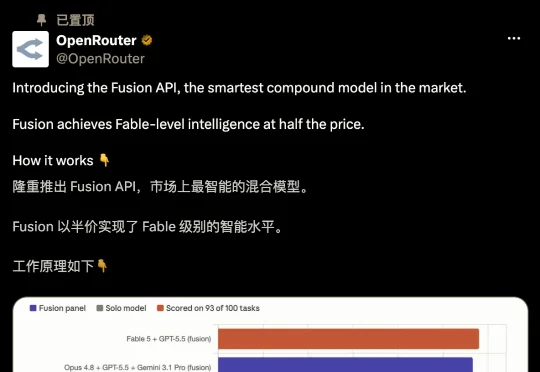
OpenRouter 上线了一个叫 Fusion 的新功能,把同一道题丢给一组模型,再让一个裁判模型把答案揉成一份。结果是,几个便宜的开源模型组起团来,能直接打平 Fable 5,价格只有其一半。

昨天,AI 圈大都被这一新闻「刷屏」:巴西里约热内卢市政府旗下的一家 IT 公司,平地一声雷地推出一款名为「Rio 3.5」397B 的开源模型,甚至还一路逆袭杀进了全球第一梯队,超越 Qwen 3.7 Plus 等开源模型,在多项基准测试中斩获 SOTA 性能。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。
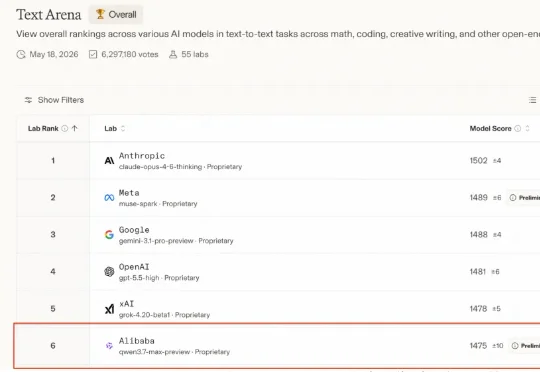
仅仅一个月后,阿里又带着最强旗舰模型杀回来了!今天上午,在 2026 阿里云峰会上,阿里全新一代千问旗舰模型 Qwen3.7-Max 登场了!在 Arena 公布的最新一期全球大模型盲测总榜中,Qwen3.7-Max 总成绩位列国产模型第一:傲视一众国产大模型
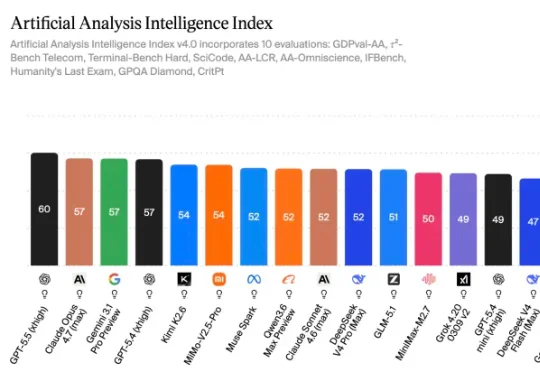
上周太集中发的后果就是光在用GPT -5.5了,小米的Mimo-V2.5-Pro,DeepSeek V4 Pro还没有放在Agent的场景上测。所以我跟钱包一拍即合,复制了4个一模一样的Hermes Agent,记忆一样,skill一样,系统设置一样,能调用的工具也一样。

从去年开始做这个账号以来,我其实写过不少测模型的文章。我相信也有很多朋友是因为看了我测评的文章关注我的。但从过年之后,真的就很少写模型评测的文章了。主要是我写文章的速度甚至一度跟不上模型发布的速度了。