
美团 LongCat-2.0:第一个在纯国产芯片训练的万亿参数大模型
美团 LongCat-2.0:第一个在纯国产芯片训练的万亿参数大模型如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?
来自主题: AI资讯
9605 点击 2026-06-30 21:04
 搜索
搜索
如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?

AI进军物理世界!海光携手同济大学,落地全国首个国产千卡工科智算集群,让国产算力不仅懂科学,更懂精密工程。从实验室走向大国重器,AI4E时代正式开启。

AI时代,Token正成为新的“硬通货”。
国产算力生态的难题,从此有了 AI 解。

近日,北京大学 EvoPhys 团队推出首个以 “人” 为中心的 “场景级万物可控” 5D 世界模型 EvoPhys-World,基于摩尔线程全国产算力底座,团队首次将 AI 生成世界从 “可观看、可漫游,浅交互” 的阶段,推进到 “可操纵、深交互、自进化” 的新阶段。

DeepSeek V4发布,比模型本身更受关注的,是一个根本性的转变: 国产算力生态正在从过去“芯片被动适配模型”的单向奔赴,迈向“芯模协同”的新阶段。

近期,深圳河套学院(SLAI)AI训练平台项目团队,联合哈尔滨工业大学(深圳)、深圳大数据研究院、华为GTS(全球技术服务)团队与深智城AI算力平台,仅用1个月,共同基于昇腾910C国产算力集群实现DeepSeek-V4-Pro全参数续训练/SFT稳定运行,完成长稳训练1500+步,训练MFU超30%,关键训练算子效率提升14%。
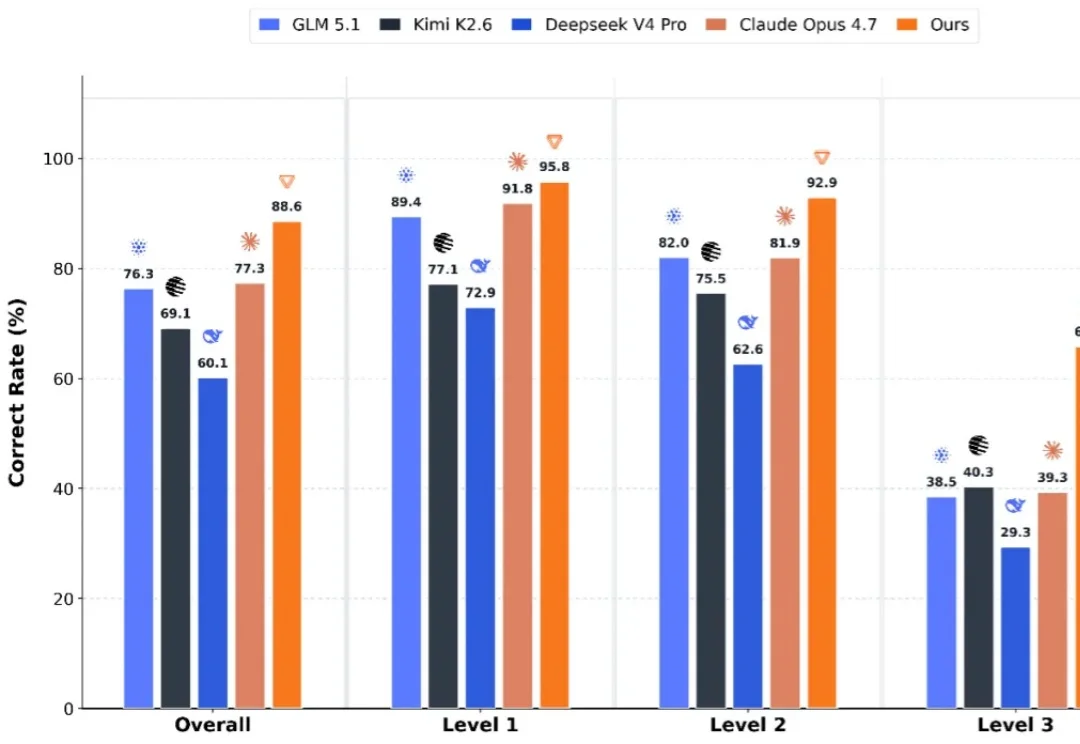
一边是 DeepSeek。2026 年 4 月 24 日,正式发布新一代模型DeepSeek-V4 系列预览版,并同步开源。另一边,美团闷声干了件大事——用全国产算力集群,训练出了万亿参数大模型 LongCat-2.0 系列预览版( LongCat-2.0-Preview )。

Clawdbot火爆全球,国产算力却不能用?AI Agent迎来高光时刻:Ollama只支持CUDA,中国团队直接把国产版开源了!正面硬刚Ollama,5分钟让国产芯片跑通OpenClaw!
国产算力基建跑了这么多年,大家最关心的逻辑一直没变:芯片够不够多?但对开发者来说,真正扎心的问题其实是:好不好使?