
专治AI生图「人脸崩坏」,8倍速碾压GPT!新版FLUX.1多方位刷新SOTA
专治AI生图「人脸崩坏」,8倍速碾压GPT!新版FLUX.1多方位刷新SOTAFLUX.1 Kontext是一款融合即时文本图像编辑与文本到图像生成的新一代模型,支持文本与图像提示,角色一致性强,速度快达GPT-Image-1的8倍。
来自主题: AI资讯
9701 点击 2025-05-31 14:26
 搜索
搜索
FLUX.1 Kontext是一款融合即时文本图像编辑与文本到图像生成的新一代模型,支持文本与图像提示,角色一致性强,速度快达GPT-Image-1的8倍。
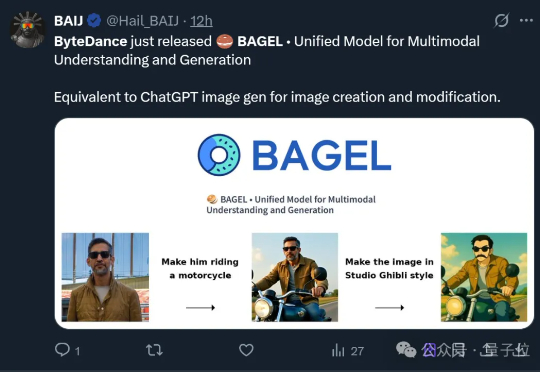
字节最近真的猛猛开源啊……这一次,他们直接开源了GPT-4o级别的图像生成能力。不止于此,其最新融合的多模态模型BAGEL主打一个“大一统”, 将带图推理、图像编辑、3D生成等功能全都集中到了一个模型。

字节开源图像编辑新方法,比当前SOTA方法提高9.19%的性能,只用了1/30的训练数据和1/13参数规模的模型。

随着Gemini、GPT-4o等商业大模型把基于文本的图像编辑这一任务再次推向高峰,获取更高质量的编辑数据用于训练、以及训练更大参数量的模型似乎成了提高图像编辑性能的唯一出路。然而浙大哈佛这个团队却反其道而行之,仅用以往工作0.1%的数据量(获取自公开数据集)和1%的训练参数,以极低成本实现了图像的高质量编辑,在一些方面媲美甚至超越商业大模型!

阶跃星辰正式发布并开源图像编辑大模型 Step1X-Edit,性能达到开源 SOTA。该模型总参数量为 19B (7B MLLM + 12B DiT),具备语义精准解析、身份一致性保持、高精度区域级控制三项关键能力;支持 11 类高频图像编辑任务类型,如文字替换、风格迁移、材质变换、人物修图等。
论文第一作者为余鑫,香港大学三年级博士生,通讯作者为香港大学齐晓娟教授。主要研究方向为生成模型及其在图像和 3D 中的应用,发表计算机视觉和图形学顶级会议期刊论文数十篇,论文数次获得 Oral, Spotlight 和 Best Paper Honorable Mention 等荣誉。此项研究工作为作者于 Adobe Research 的实习期间完成。
图像编辑大礼包!美图5篇技术论文入围CVPR 2025。

Grok连夜上线图片编辑功能,继Gemini引爆图片编辑热潮后,动动嘴就能实现「证件照换西装」、「黑发变金发」等专业级P图效果。随着AI巨头内卷加剧,很多工作可能会经历「从复杂操作到简单交互」的范式转移,大模型内卷,受伤可能是传统软件。
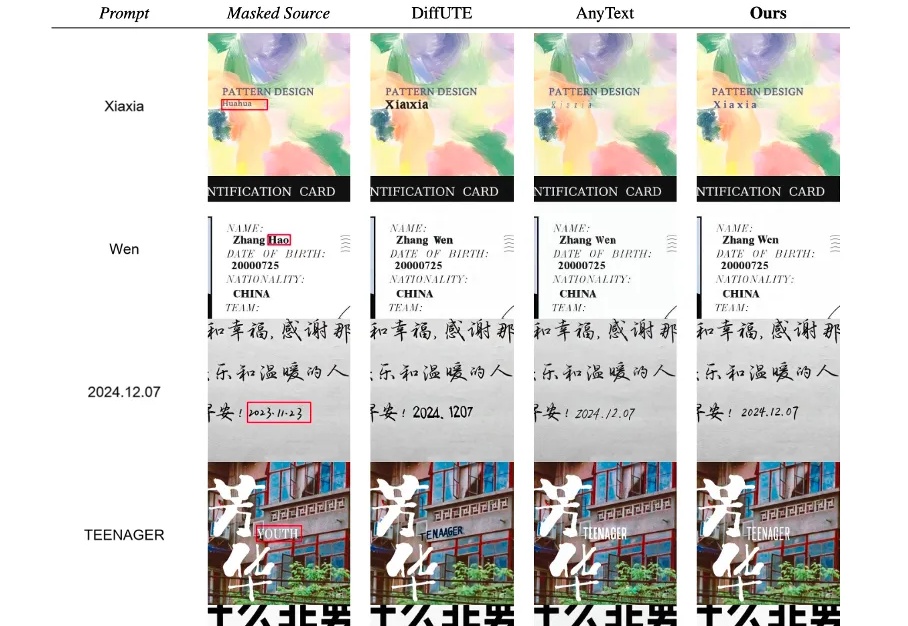
随着图像编辑工具和图像生成技术的快速发展,图像处理变得非常方便。然而图像在经过处理后不可避免的会留下伪影(操作痕迹),这些伪影可分为语义和非语义特征。
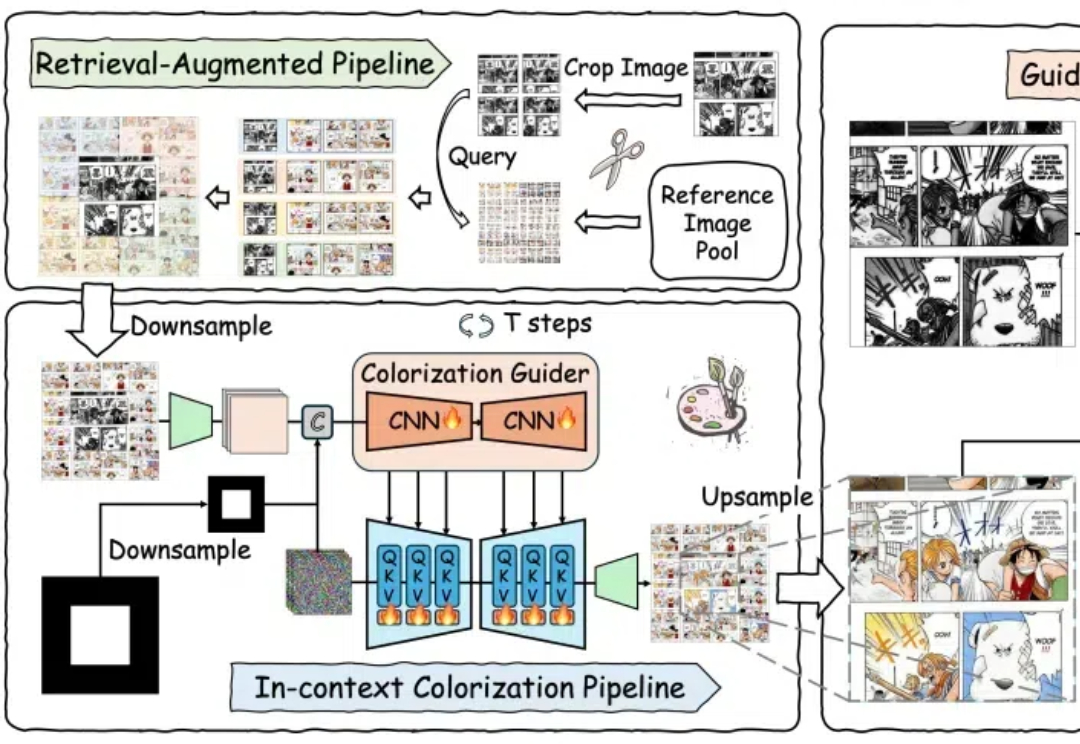
扩散模型在可控图像生成方面取得了空前进展,包括图像修补 ,图像着色和图像编辑。基于扩散模型的生成方案可以显著降低劳动力成本,尤其是在基于参考图像序列着色任务上,它可用于漫画创作,动画制作和黑白电影着色。