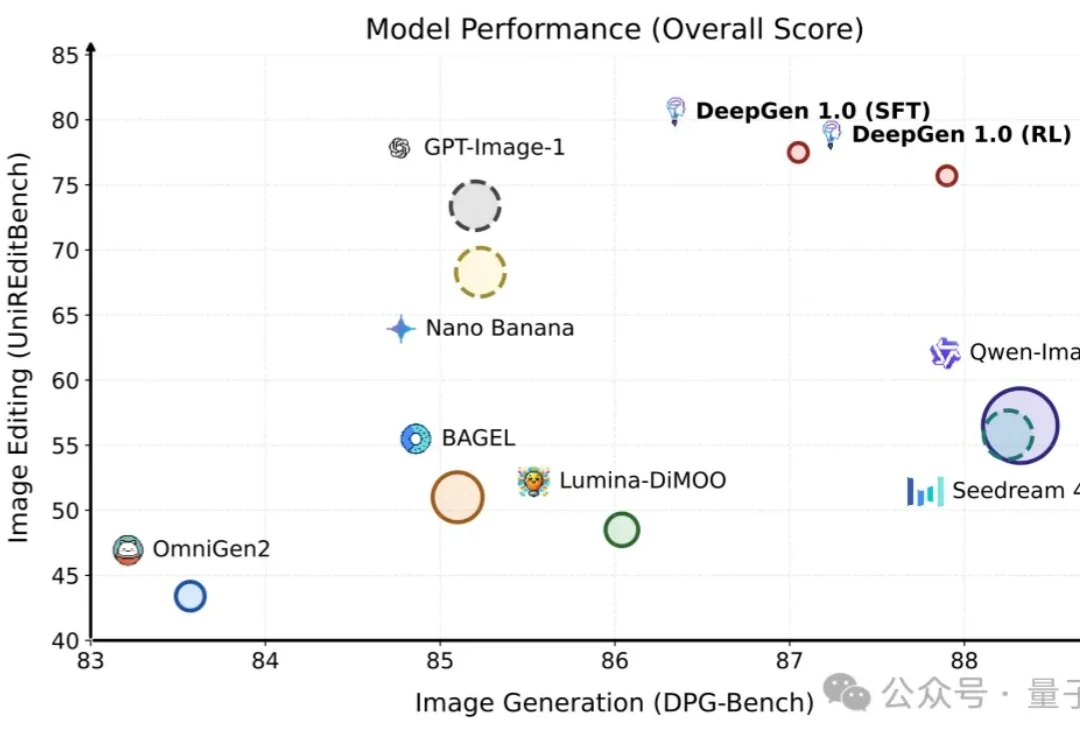
5B参数+4060Ti,10秒出图,全流程开源可复现!补齐统一多模态生成编辑的开源版图,让高质量图像生成真正变得更轻量、更普及
5B参数+4060Ti,10秒出图,全流程开源可复现!补齐统一多模态生成编辑的开源版图,让高质量图像生成真正变得更轻量、更普及统一多模态生成编辑模型,正在走向“重器化”
来自主题: AI技术研报
10636 点击 2026-03-18 16:15
 搜索
搜索
统一多模态生成编辑模型,正在走向“重器化”

多模态模型代码写得像老司机,却在数手指、量柱子时频频翻车?UniPat AI用五百行代码打造的SWE-Vision,让模型「掏出Python尺子」自我验证,一举拿下五大视觉相关基准SOTA。

Google 最近发了 Gemini Embedding 2,他们第一个原生多模态向量模型。文本、图像、视频、音频、文档,全部映射到同一个 3072 维向量空间。这是 Omni Embedding(全模态向量模型)的大趋势:一个架构吃下所有模态,从 jina-embeddings-v4 到 Omni-Embed-Nemotron 再到 Omni-5,大家都在往这个方向收敛。
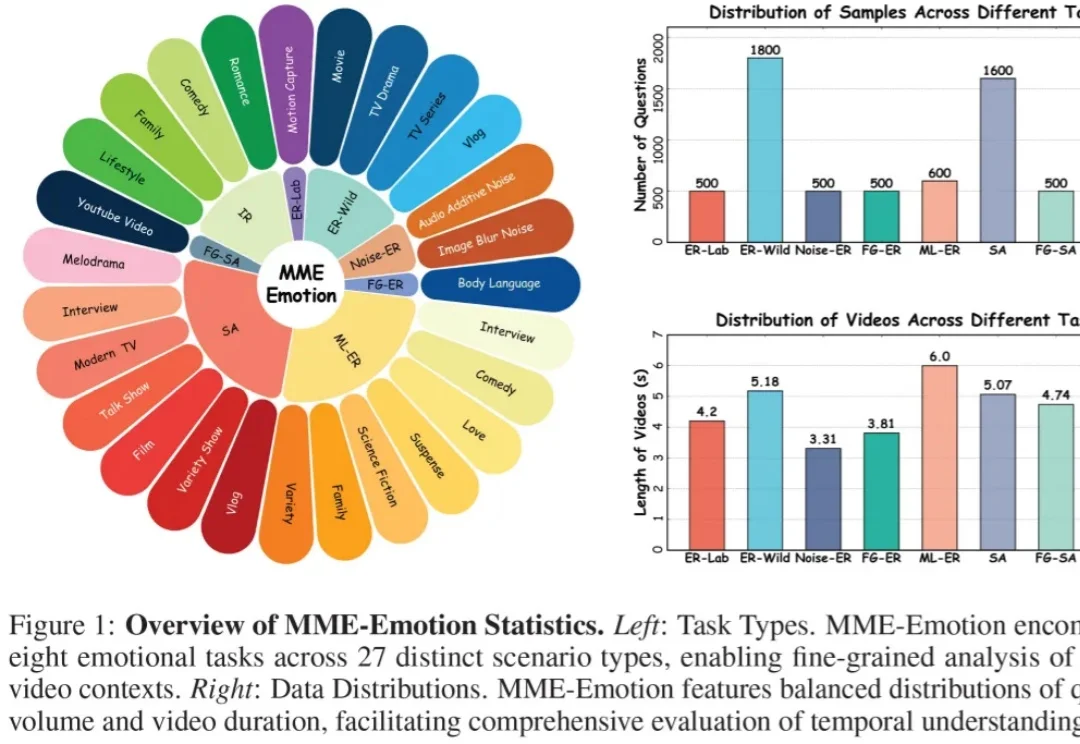
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?
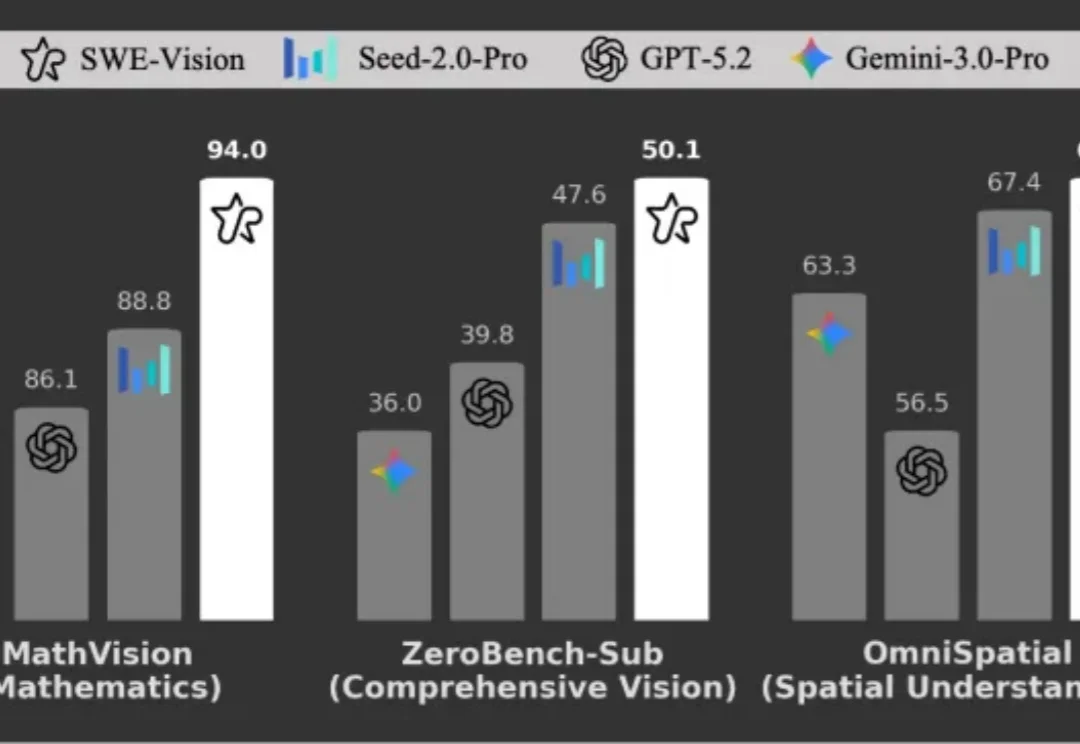
多模态大模型在代码能力上进步惊人,但在基础视觉任务上却频繁失误。UniPat AI 构建了一个极简的视觉智能体框架 ——SWE-Vision,让模型可以编写并执行 Python 代码来处理和验证自己的视觉判断。在五个主流视觉基准测试中,SWE-Vision 均达到了当前最优水平。

牛津大学团队推出全球首个心脏传感基础模型CSFM,能统一分析智能手环、心电图等多源数据,无论信号来自何处、是否完整,都能精准诊断房颤、预测死亡风险、重构血压波形,甚至用单一脉搏波生成完整心电图。打破了设备壁垒,让偏远地区也能享用顶级心脏监护,推动全球医疗平权。

我们独家获悉,外界千呼万唤的DeepSeek-V4将于4月正式上线。作为梁文锋打磨已久的多模态大模型,DeepSeek-V4除了在Coding能力上跃升之外,还将在LTM(long term memory长期记忆)上取得突破。
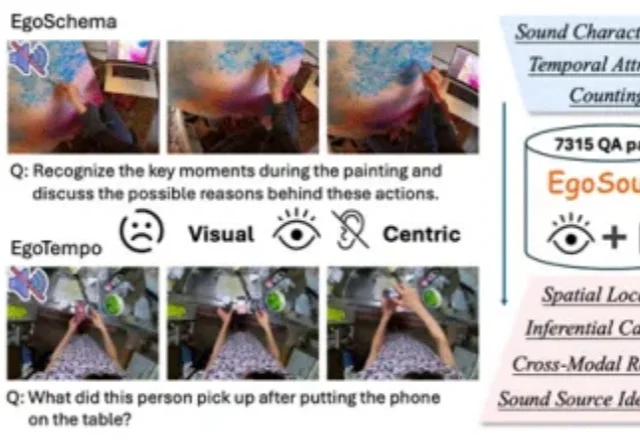
多模态大模型掉进真实世界,会“失聪”。
“时光流转,谁还用日记本。往事有底片为证。”—— 许嵩《摄影艺术》

刚刚,谷歌发布了首个原生多模态(Multimodal)嵌入模型——Gemini Embedding 2。这次模型最大的变化在于:把文本、图像、视频、音频和文档,全部映射进同一个统一的嵌入空间。