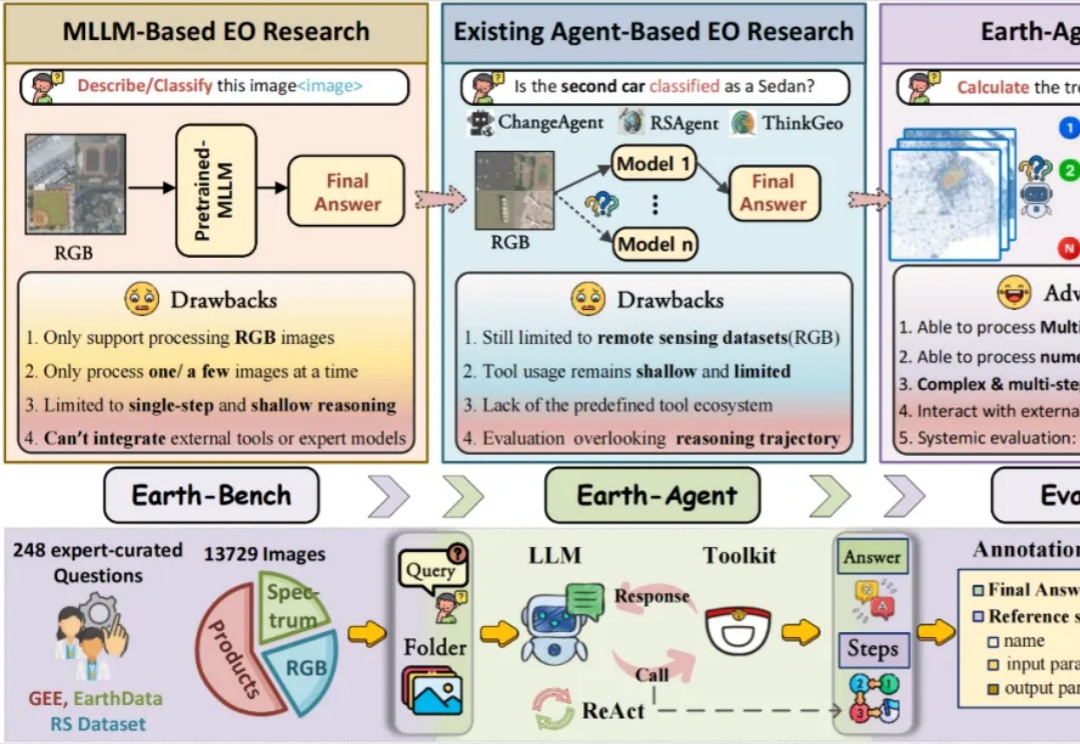
首个地球科学智能体Earth-Agent来了,解锁地球观测数据分析新范式
首个地球科学智能体Earth-Agent来了,解锁地球观测数据分析新范式当强大的多模态大语言模型应用于地球科学研究时,它面临着无法忽视的 「阿克琉斯之踵」
来自主题: AI技术研报
9378 点击 2025-10-28 14:45
 搜索
搜索
当强大的多模态大语言模型应用于地球科学研究时,它面临着无法忽视的 「阿克琉斯之踵」

能看懂相机参数,并且生成相应视角图片的多模态模型来了。

近日,在 CNCC2025 大会上,郑波首次公开了淘宝全模态大模型的最新进展,并系统介绍了多模态智能在淘宝 AIGX 技术体系的研究应用。另外,结合 AI 模型技术在淘宝应用中的实践,他认为,「狭义 AGI 很可能在 5-10 年内到来。」
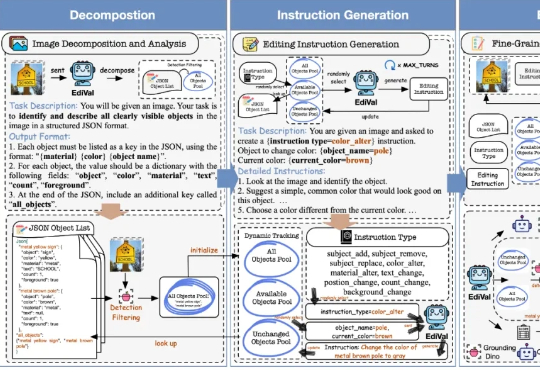
在 AIGC 的下一个阶段,图像编辑(Image Editing)正逐渐取代一次性生成,成为检验多模态模型理解、生成与推理能力的关键场景。我们该如何科学、公正地评测这些图像编辑模型?

dots.ocr 支持多语言文档的解析,能够在单一模型中统一完成版面检测、文本识别、表格解析、公式提取等任务,并保持良好的阅读顺序。他们之所以在一个模型中完成这些任务,是因为他们相信这些任务之间可以相互促进,为彼此提供更多的 context,从而达到更高的性能上限。目前,该项目的 star 量已经超过了 5000。
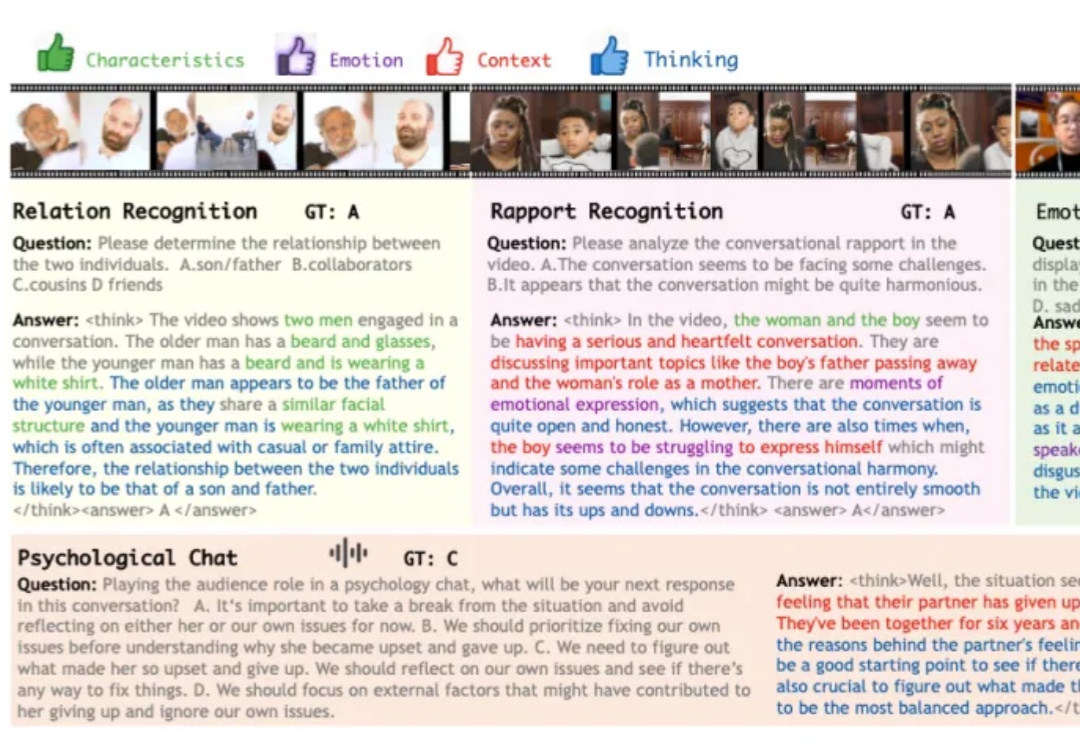
在科幻作品描绘的未来,人工智能不仅仅是完成任务的工具,更是为人类提供情感陪伴与生活支持的伙伴。在实现这一愿景的探索中,多模态大模型已展现出一定潜力,可以接受视觉、语音等多模态的信息输入,结合上下文做出反馈。
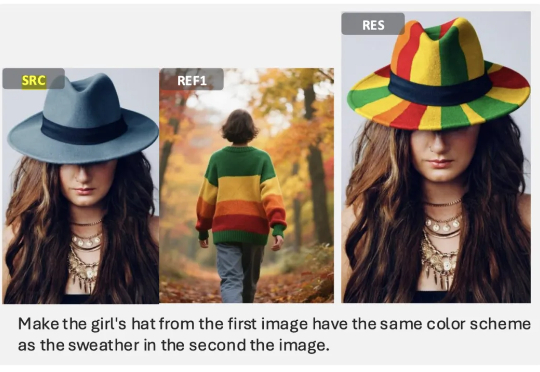
两周前,港科大讲座教授、冯诺依曼研究院院长贾佳亚团队开源了他们的最新成果 DreamOmni2,专门针对当前多模态指令编辑与生成两大方向的短板进行了系统性优化与升级。该系统基于 FLUX-Kontext 训练,保留原有的指令编辑与文生图能力,并拓展出多参考图的生成编辑能力,给予了创作者更高的灵活性与可玩性。

随着多模态大模型的不断演进,指令引导的图像编辑(Instruction-guided Image Editing)技术取得了显著进展。然而,现有模型在遵循复杂、精细的文本指令方面仍面临巨大挑战,往往需要用户进行多次尝试和手动筛选,难以实现稳定、高质量的「一步到位」式编辑。

学术展示视频作为科研交流的重要媒介,制作过程仍高度依赖人工,需要反复进行幻灯片设计、逐页录制和后期剪辑,往往需要数小时才能产出几分钟的视频,效率低下且成本高昂,这凸显了推动学术展示视频自动化生成的必要性。
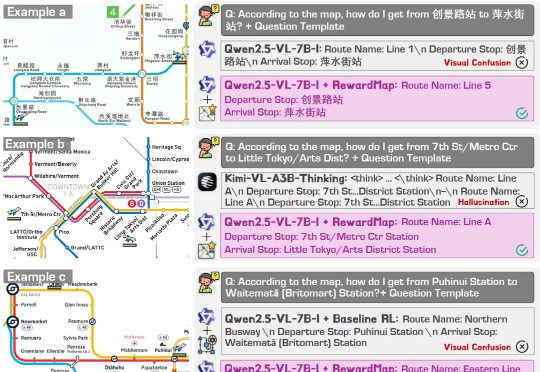
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。