# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态模型学会“按需搜索”!
字节&NTU最新研究,优化多模态模型搜索策略——
通过搭建网络搜索工具、构建多模态搜索数据集以及涉及简单有效的奖励机制,首次尝试基于端到端强化学习的多模态模型自主搜索训练。
经过训练的模型能够自主判断搜索时机、搜索内容并处理搜索结果,在真实互联网环境中执行多轮按需搜索。
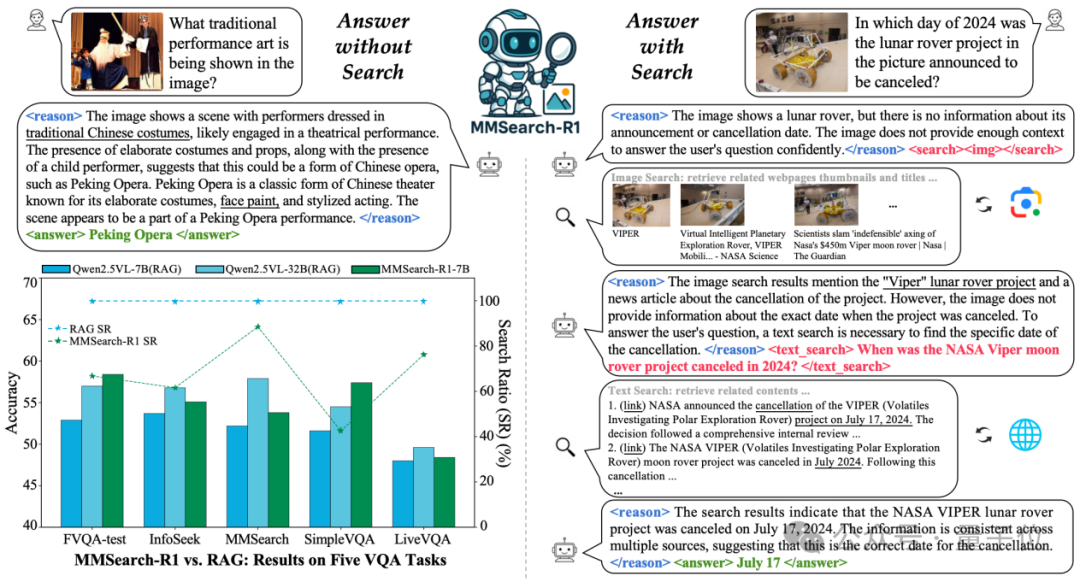
实验结果表明,在知识密集型视觉问答任务(Visual Question Answering, VQA)中,MMSearch-R1系统展现出显著优势:
其性能不仅超越同规模模型在传统检索增强生成(RAG)工作流下的性能,更在减少约30%搜索次数的前提下,达到了更大规模规模模型做传统RAG的性能水平。
下文将详细解析该研究的研究方法以及实验发现。

近年来,随着视觉-语言训练数据集在规模和质量上的双重提升,多模态大模型(Large Multimodal Models, LMMs)在跨模态理解任务中展现出卓越的性能,其文本与视觉知识的对齐能力显著增强。
然而,现实世界的信息具有高度动态性和复杂性,单纯依靠扩大训练数据规模的知识获取方式存在固有局限:难以覆盖长尾分布的知识、无法获取模型训练截止日期后的新信息,以及难以触及私域信息资源。
这些局限性导致模型在实际应用中容易产生幻觉现象,严重制约了其在广泛现实场景下部署的可靠性。
在此背景下,网络搜索作为人类获取新知识的核心途径,被视为扩展模型能力边界的重要工具,正受到学术界的高度重视。
如何使多模态模型具备自主、精准的外部信息获取能力,从而实现准确的问题解答,成为当前研究的关键挑战。
因此,ByteDance与南洋理工大学(NTU)S-Lab联合开展的MMSearch-R1项目针对这一挑战进行了探索。
下面详细来看该研究的研究方法。
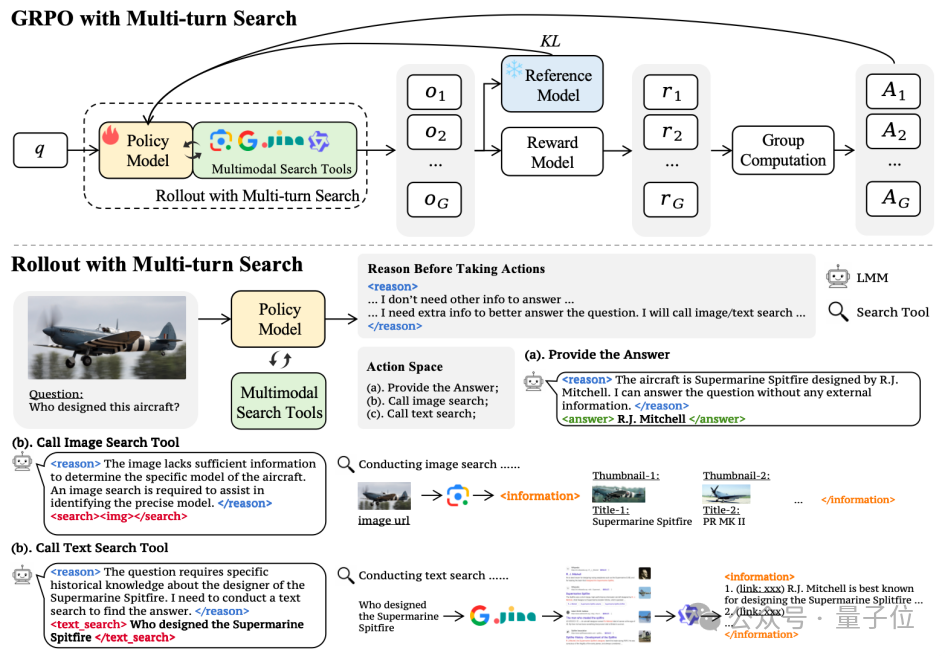
1、多模态搜索工具
MMSearch-R1集成图像搜索和文本搜索两种工具,以满足模型应对视觉问答任务的需求,其中图像搜索工具基于Google Lens,支持搜索与用户图像视觉外观匹配的网页标题以及主要缩略图,用于帮助模型准确识别重要的视觉元素。
文本搜索工具由Google Search,JINA Reader以及用于网页内容总结的语言模型构成的链路组成,支持搜索与模型生成的搜索内容最相关的网页及其内容摘要,用于帮助模型精确定位所需文本知识与信息。
2、多轮搜索强化学习训练
MMSearch-R1采用GRPO作为强化学习算法进行模型训练,基于veRL框架实现集成多轮对话与搜索的Rollout过程,在每轮对话中,模型首先进行思考,并执行可选的动作,如调用多模态搜索工具与真实互联网进行交互,或给出最终的答案。
3、带有搜索惩罚的奖励函数
MMSearch-R1的奖励函数由准确性得分和格式得分两部分以加权求和的形式构成,其权重分别为0.9和0.1,分别衡量模型是否准确回答了用户问题(模型所给答案与真实答案作字符串精确匹配)以及遵循了既定回复格式。
为了激励模型优先利用自身知识完成作答,还会对调用搜索工具才获得正确答案的回复进行惩罚(搜索惩罚因子为0.1),最终奖励函数为:

为了有效训练模型实现智能化的按需搜索能力,研究精心构建了FactualVQA(FVQA)数据集,包含训练集和测试集。该数据集的构建采用了一套精心设计的半自动化流程,重点聚焦于需要丰富视觉与文本知识支持的问答场景。
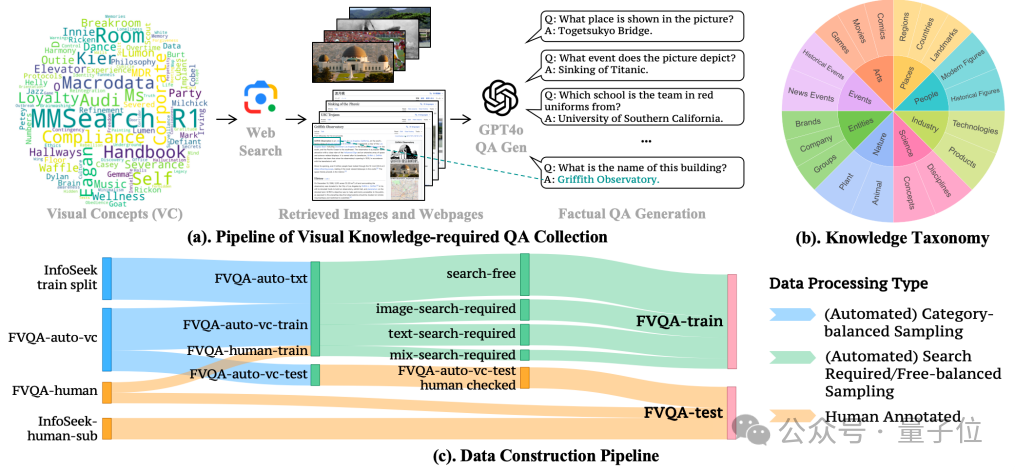
1、数据采集
团队首先基于MetaCLIP的元数据分布进行多层次采样,确保覆盖从高频到长尾的多样化视觉概念(Visual Concept),并从互联网中搜索与视觉概念最相关的图片,基于GPT-4o生成事实性问答对。
为增强数据集的文本知识维度,团队还从InfoSeek训练集中筛选了具有代表性的问答样本进行补充。为确保数据质量贴近真实应用场景,FVQA还补充了800个由标注人员标注问答对样本。
2、数据均衡
完成初步数据采集后,通过一个粗训练的模型对现有样本进行分类,检查每条数据的搜索必要性,最终训练数据集包含约3400个需要搜索的样本和1600个无需搜索的样本。
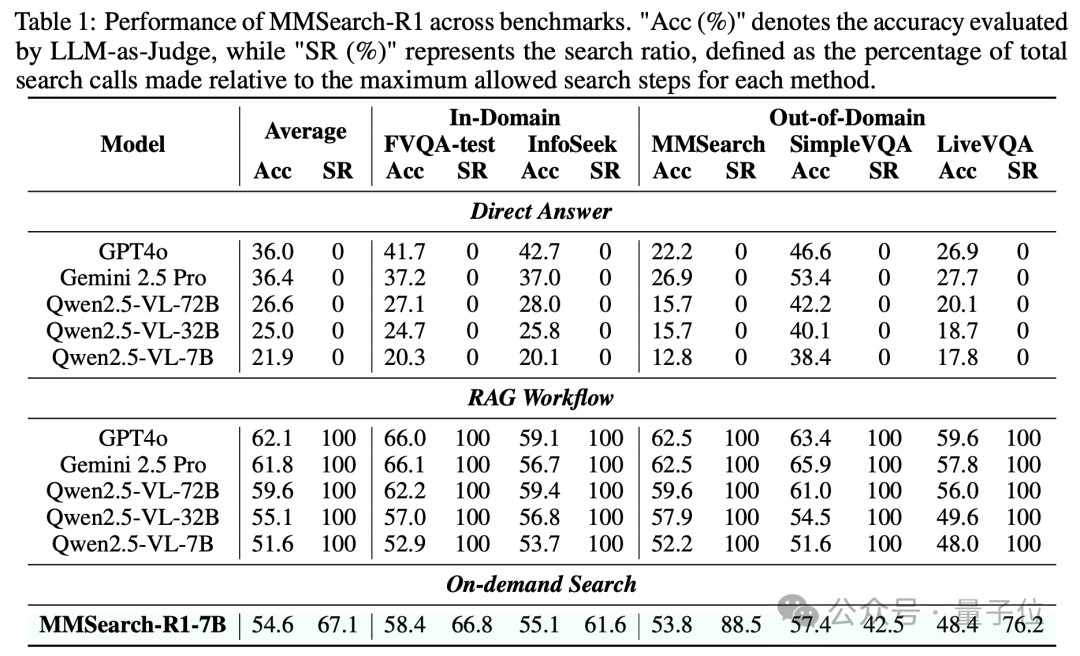
MMSearch-R1-7B基于Qwen2.5-VL-7B模型进行训练。
在FVQA-test、InfoSeek等知识密集型VQA任务中,MMSearch-R1-7B的平均准确率比同等规模模型的传统RAG基线高出约3%,搜索比率降低了32.9%,同时能够媲美32B模型RAG基线的效果。
经过强化学习训练,模型提升了优化搜索内容以及处理搜索结果的能力(下图左,经过强化学习的模型执行RAG Workflow性能要好于原始模型),同时增强了挖掘利用自身固有知识的能力(下图右,模型提升了不搜索即可回答正确的比率)。
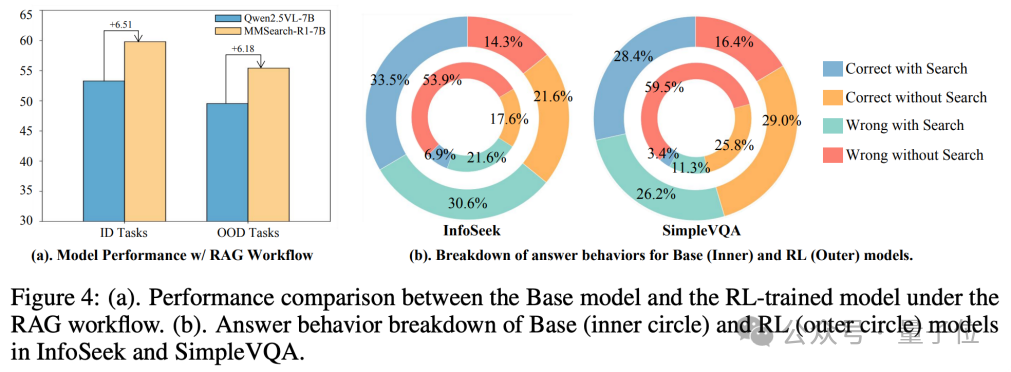
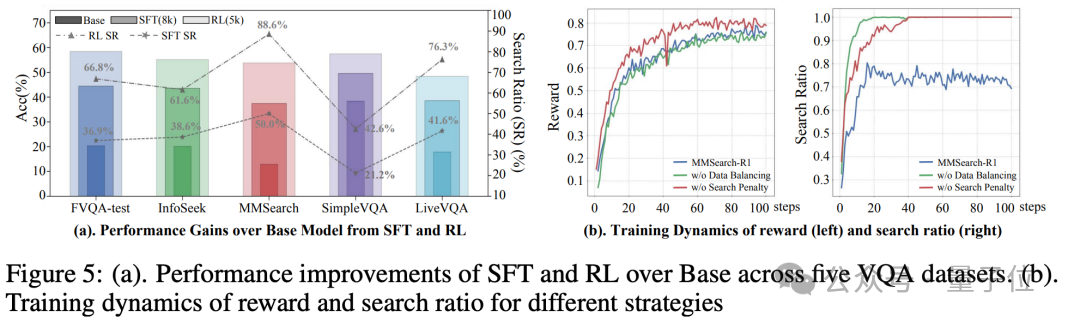
强化学习展现出比监督微调更大的潜力,在所有任务上以较少的训练样本取得更大的性能增益(下图左)。
同时证明数据搜索比例均衡以及奖励函数中的搜索惩罚机制有助于在训练过程中塑造模型的按需搜索行为(下图右)。
最后总结来说,MMSearch-R1是一个基于强化学习的创新框架,赋予多模态大模型在真实互联网环境中执行智能按需搜索的能力。该框架使模型能够自主识别知识边界,进而选择图像或文本搜索方式获取所需信息,并对搜索结果进行有效推理。
团队表示,该研究为开发具备现实世界交互能力的多模态大模型提供了重要洞见,为构建自适应、交互式的多模态智能体奠定了基础。期待随着模型通过更多工具与现实世界的持续交互,多模态智能将在推理和适应能力上实现新的飞跃。
论文地址:https://arxiv.org/abs/2506.20670
项目地址:https://github.com/EvolvingLMMs-Lab/multimodal-search-r1
文章来自于微信公众号“量子位”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
