Insta360最新全景综述:全景视觉的挑战、方法与未来
Insta360最新全景综述:全景视觉的挑战、方法与未来本文作者团队来自 Insta360 影石研究院及其合作高校。目前,Insta360 正在面向世界模型、多模态大模型、生成式模型等前沿方向招聘实习生与全职算法工程师,欢迎有志于前沿 AI 研究与落地的同
来自主题: AI技术研报
8262 点击 2025-10-06 14:46
 搜索
搜索
本文作者团队来自 Insta360 影石研究院及其合作高校。目前,Insta360 正在面向世界模型、多模态大模型、生成式模型等前沿方向招聘实习生与全职算法工程师,欢迎有志于前沿 AI 研究与落地的同
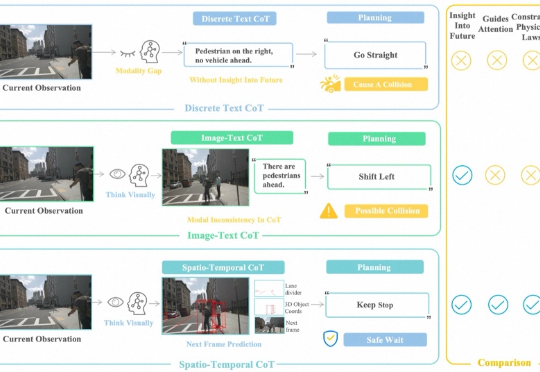
面向自动驾驶的多模态大模型在 “推理链” 上多以文字或符号为中介,易造成空间 - 时间关系模糊与细粒度信息丢失。FSDrive(FutureSightDrive)提出 “时空视觉 CoT”(Spatio-Temporal Chain-of-Thought),让模型直接 “以图思考”,用统一的未来图像帧作为中间推理步骤,联合未来场景与感知结果进行可视化推理。
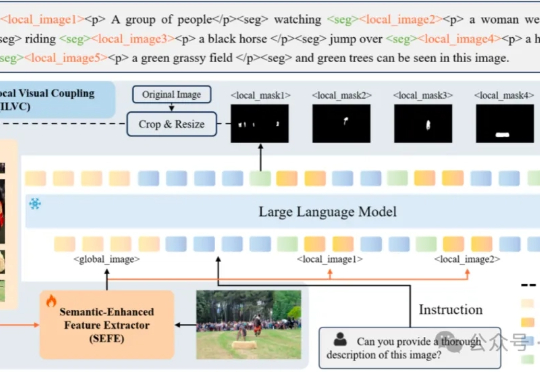
多模态大模型需要干的活,已经从最初的文生图,扩展到了像素级任务(图像分割)。
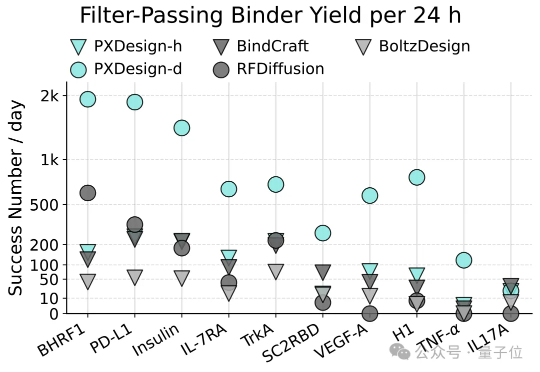
AI蛋白设计进入新阶段!最近,字节跳动Seed团队多模态生物分子结构大模型(Protenix)项目组提出了一种可扩展的蛋白设计方法,叫做PXDesign。在实际测试中,PXDesign展现出极高的效率,24小时内即可生成数百个高质量的候选蛋白,生成效率较业界主流方法提升约10倍,并在多个靶点上实现了20%–73%的湿实验成功率,达到了当前领域的领先水平。

由华中科技大学与小米汽车提出了业内首个无需 OCC 引导的多模态的图像 - 点云联合生成框架 Genesis。该算法只需基于场景描述和布局(包括车道线和 3D 框),就可以生成逼真的图像和点云视频。

近日,为了加速多元素催化剂的发现与优化,美国麻省理工学院团队开发了一个多模态机器人平台——CRESt(Copilot for Real-world Experimental Scientists)。该平台能够结合自动化设备、大规模模型和实验室监测,在实验设计中融入人类经验、文献知识和显微结构信息,从而加速多元素催化剂的发现和优化加速发展。
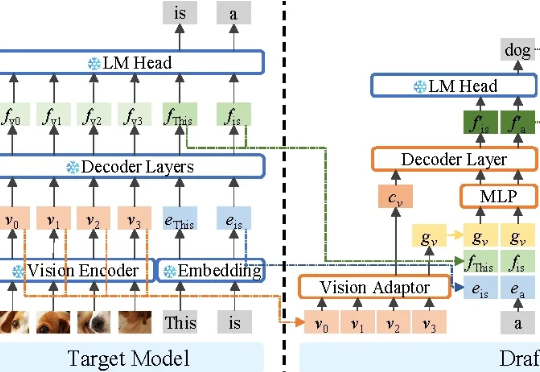
不牺牲任何生成质量,将多模态大模型推理最高加速3.2倍! 华为诺亚方舟实验室最新研究已入选NeurIPS 2025。
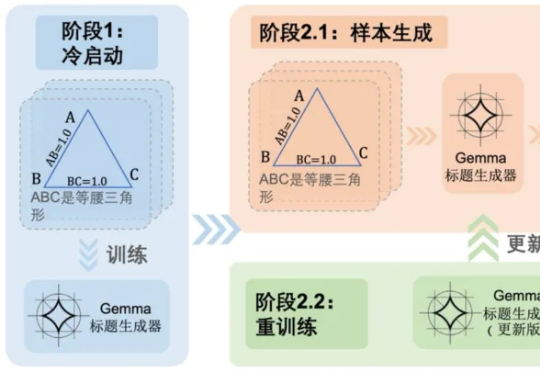
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视

奇多多AI学伴机是由无界方舟发布的国内首款基于「端到端实时多模态互动模型」的AI互动机器人,于本月2025外滩大会首次亮相。京东预售仅上线一周,销量便突破了10000台,在看似红海的儿童早教市场掀起波澜。在功能体验方面,它带来了三大突破:能“看”世界的眼睛、堪比真人的低延迟反馈速度、能“成长”的个性化陪伴感。
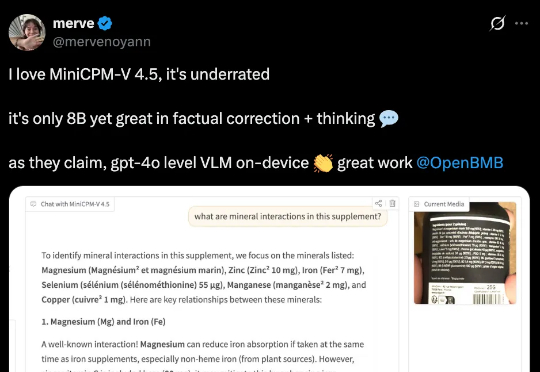
行业首个具备“高刷”视频理解能力的多模态模型MiniCPM-V 4.5的技术报告正式发布!报告提出统一的3D-Resampler架构实现高密度视频压缩、面向文档的统一OCR和知识学习范式、可控混合快速/深度思考的多模态强化学习三大技术。