
谷歌T5Gemma重燃架构之战!「套壳」反杀Gemma本尊,9B推理快得离谱
谷歌T5Gemma重燃架构之战!「套壳」反杀Gemma本尊,9B推理快得离谱Google双线出击!T5Gemma重燃encoder-decoder架构战火,性能暴涨12分;MedGemma坚守decoder-only路线,强攻医疗多模态,击穿闭源壁垒。Gemma体系完成「架构+落地」双重进化,打响Google开源反击战。
来自主题: AI技术研报
9417 点击 2025-07-15 15:05
 搜索
搜索
Google双线出击!T5Gemma重燃encoder-decoder架构战火,性能暴涨12分;MedGemma坚守decoder-only路线,强攻医疗多模态,击穿闭源壁垒。Gemma体系完成「架构+落地」双重进化,打响Google开源反击战。
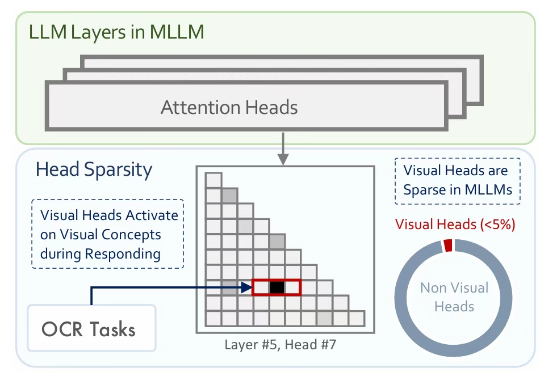
多模态大模型通常是在大型预训练语言模型(LLM)的基础上扩展而来。尽管原始的 LLM 并不具备视觉理解能力,但经过多模态训练后,这些模型却能在各类视觉相关任务中展现出强大的表现。
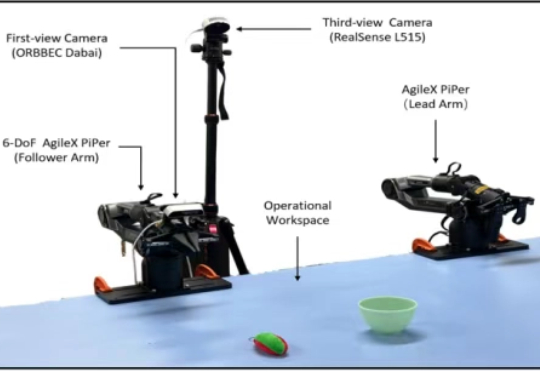
近年来,视觉 - 语言 - 动作(Vision-Language-Action, VLA)模型因其出色的多模态理解与泛化能力,已成为机器人领域的重要研究方向。尽管相关技术取得了显著进展,但在实际部署中,尤其是在高频率和精细操作等任务中,VLA 模型仍受到推理速度瓶颈的严重制约。

近年来,多模态大模型(MLLMs)发展迅猛,从看图说话到视频理解,似乎无所不能。

GPT-4o引爆全球「吉卜力风格」风潮后,其核心成员——华南理工学霸Lu Liu与伯克利博士Allan Jabri——双双跳槽Meta,两人曾在OpenAI主导多模态AI研究,与奥特曼同台展示关键功能。此次挖角再次凸显OpenAI内部动荡后的人才流失危机。
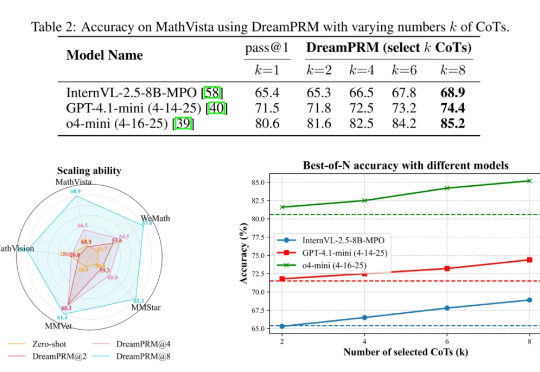
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:
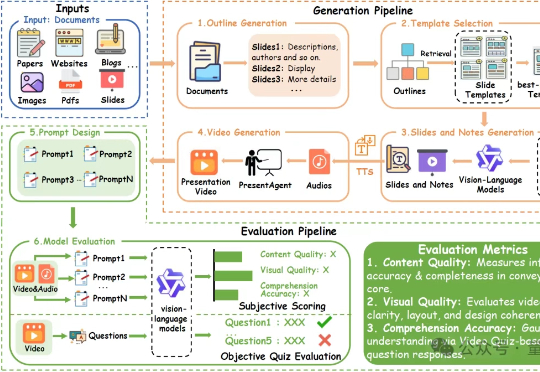
现在的AI Agent在文档生成PPT或视频方面,要想像人一样,把文字、图片、讲解、音视频全都串起来讲清楚,还真不太行。

让大模型在学习推理的同时学会感知。伊利诺伊大学香槟分校(UIUC)与阿里巴巴通义实验室联合推出了全新的专注于多模态推理的强化学习算法PAPO(Perception-Aware Policy Optimization)。
当前,驱动科学研究的人工智能(AI for Science,AI4S)在单点取得了可观的进展,实现了工具层面的革新,然而要成为「革命的工具」,需要采用「通专融合 AGI」方式。

MoCa框架把单向视觉语言模型转化为双向多模态嵌入模型,通过持续预训练和异构对比微调,提升模型性能和泛化能力,在多模态基准测试中表现优异,尤其小规模模型性能突出。