
刚刚,谷歌Gemma 3上线!单GPU最强多模态手机可跑,27B完胜o3-mini
刚刚,谷歌Gemma 3上线!单GPU最强多模态手机可跑,27B完胜o3-mini就在刚刚,谷歌Gemma 3来了,1B、4B、12B和27B四种参数,一块GPU/TPU就能跑!而Gemma 3仅以27B就击败了DeepSeek 671B模型,成为仅次于DeepSeek R1最优开源模型。
来自主题: AI资讯
10647 点击 2025-03-12 18:43
 搜索
搜索
就在刚刚,谷歌Gemma 3来了,1B、4B、12B和27B四种参数,一块GPU/TPU就能跑!而Gemma 3仅以27B就击败了DeepSeek 671B模型,成为仅次于DeepSeek R1最优开源模型。

首次将DeepSeek同款RLVR应用于全模态LLM,含视频的那种!
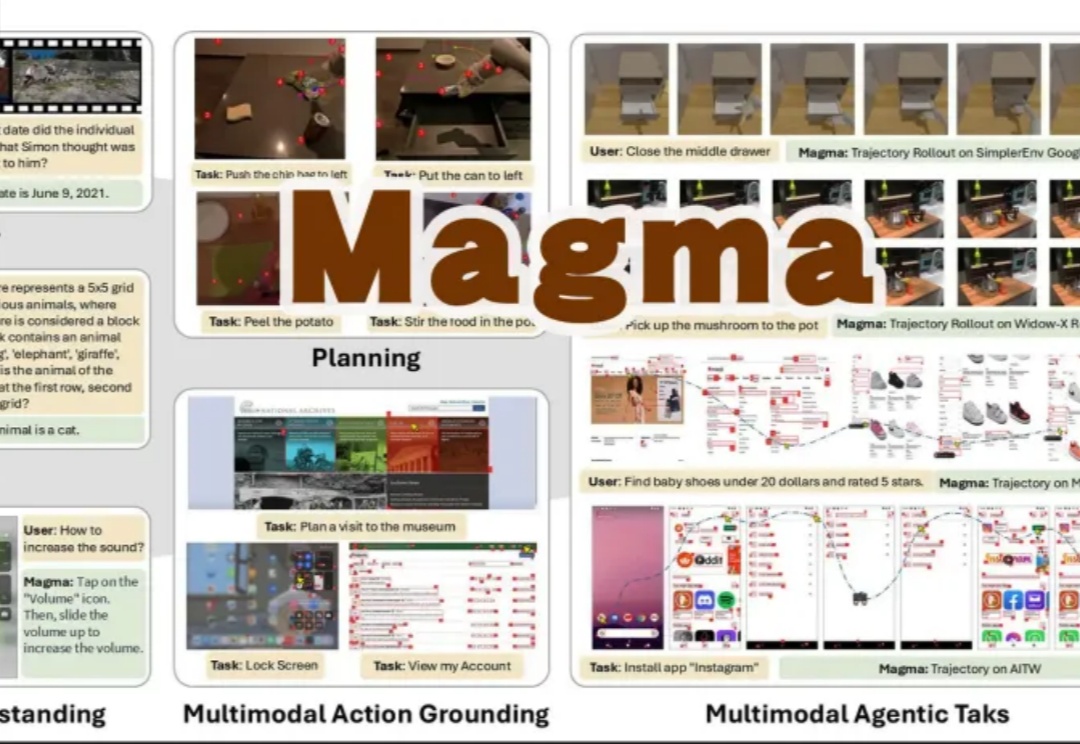
Magma是一个新型多模态基础模型,能够理解和执行多模态任务,适用于数字和物理环境:通过标记集合(SoM)和标记轨迹(ToM)技术,将视觉语言数据转化为可操作任务,显著提升了空间智能和任务泛化能力。

微软研究院官宣开源多模态AI——Magma模型。首个能在所处环境中理解多模态输入并将其与实际情况相联系的基础模型。
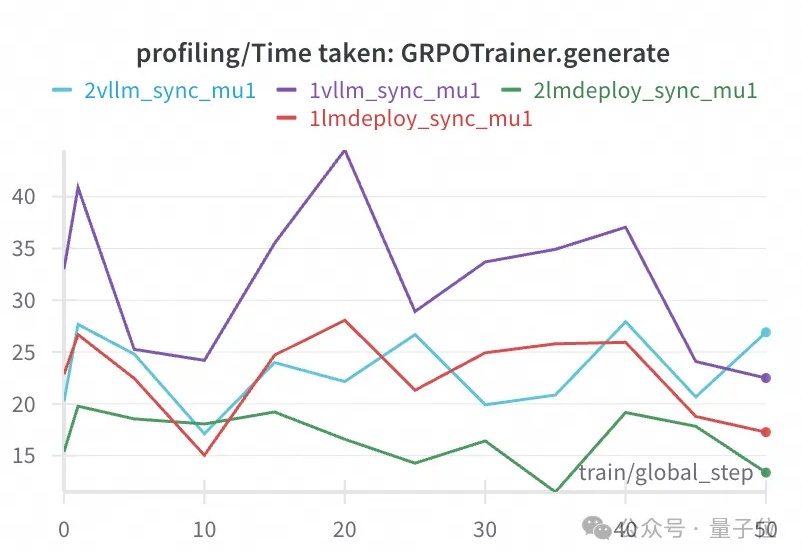
GRPO训练又有新的工具链可以用,这次来自于ModelScope魔搭社区。

来自哥本哈根大学、苏黎世联邦理工学院等机构的研究人员,提出了一个全新的多模态Few-shot 3D分割设定和创新方法。无需额外标注成本,该方法就可以融合文本、2D和3D信息,让模型迅速掌握新类别。

北京大学、上海人工智能实验室、南洋理工大学联合推出 DiffSensei,首个结合多模态大语言模型(MLLM)与扩散模型的定制化漫画生成框架。该框架通过创新的掩码交叉注意力机制与文本兼容的角色适配器,实现了对多角色外观、表情、动作的精确控制

智源联手多所顶尖高校发布的多模态向量模型BGE-VL,重塑了AI检索领域的游戏规则。它凭借独创的MegaPairs合成数据技术,在图文检索、组合图像检索等多项任务中,横扫各大基准刷新SOTA。

基于闭源评测基准,近期司南针对国内外主流多模态大模型进行了全面评测,现公布司南首期多模态模型闭源评测榜单。首期榜单共包含 48 个多模态模型,其中包含:3 个国内 API 模型:GLM-4v-Plus-20250111 (智谱),Step-1o (阶跃),BailingMM-Pro-0120 (蚂蚁)
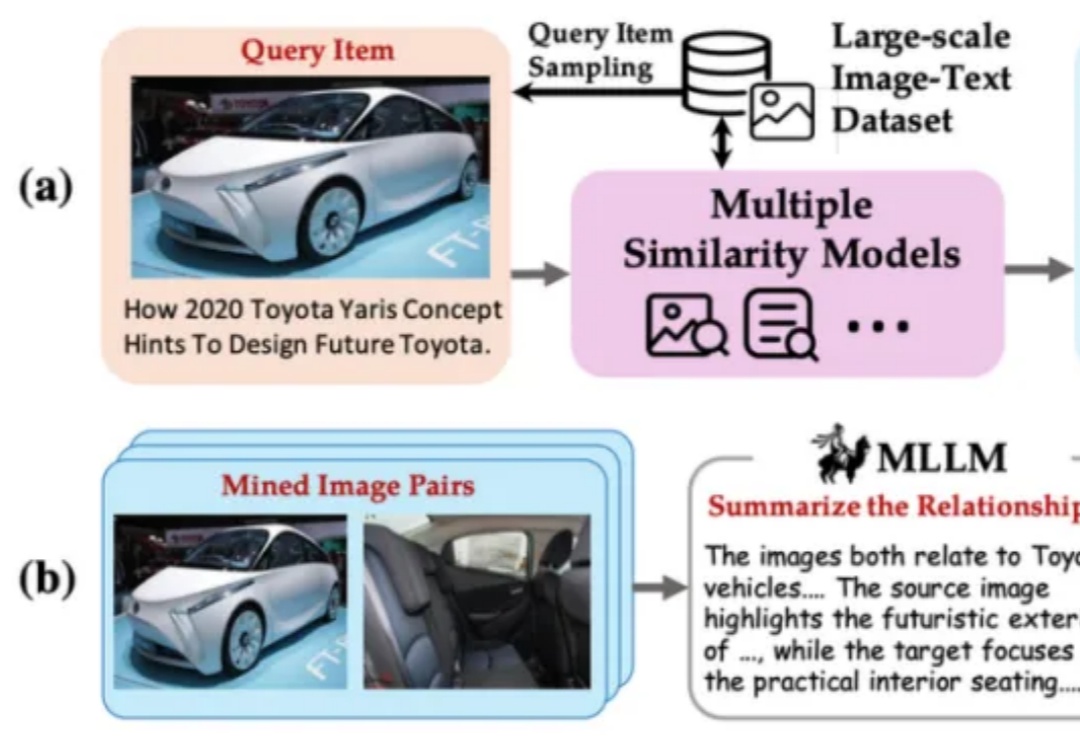
BGE 系列模型自发布以来广受社区好评。近日,智源研究院联合多所高校开发了多模态向量模型 BGE-VL,进一步扩充了原有生态体系。