
首个多模态连续学习综述,港中文、清华、UIC联合发布
首个多模态连续学习综述,港中文、清华、UIC联合发布连续学习(CL)旨在增强机器学习模型的能力,使其能够不断从新数据中学习,而无需进行所有旧数据的重新训练。连续学习的主要挑战是灾难性遗忘:当任务按顺序训练时,新的任务训练会严重干扰之前学习的任务的性能,因为不受约束的微调会使参数远离旧任务的最优状态。
来自主题: AI技术研报
6052 点击 2024-11-13 16:02
 搜索
搜索
连续学习(CL)旨在增强机器学习模型的能力,使其能够不断从新数据中学习,而无需进行所有旧数据的重新训练。连续学习的主要挑战是灾难性遗忘:当任务按顺序训练时,新的任务训练会严重干扰之前学习的任务的性能,因为不受约束的微调会使参数远离旧任务的最优状态。
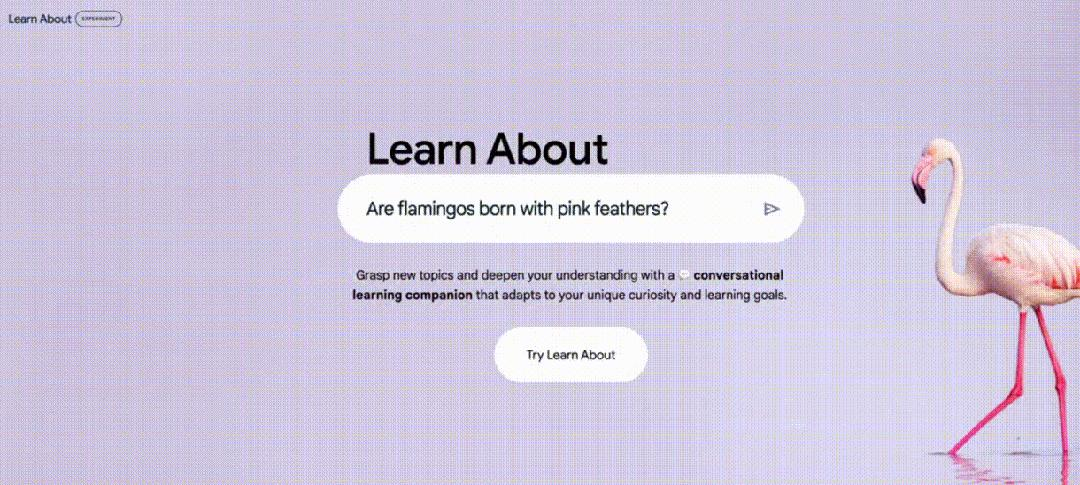
11月11日,谷歌推出了一款名为“Learn About” 的实验性的新 AI 工具,它不同于此前的聊天机器人,如 Gemini 和 ChatGPT。

第8届CoRL于2024年11月6日至9日在德国慕尼黑举行,展示了机器人学习领域的前沿研究和发展,尤其是在自主系统、机器人控制和多模态人工智能领域。

要说最近大模型应用里哪个赛道最火爆,AI搜索当属其一。 大厂初创纷纷下场不说,功能也越卷越深度:集成论文库、引入多模态实现图片分析……大有把知识获取成本再打骨折的趋势。 就在量子位近期收到的读者反馈中,我们也实实在在感受到了大家伙儿对AI搜索的期待,还观察到了一个呼声很高的需求——AI搜索+知识库。

在全球科技市场的前沿浪潮中,AI 与硬件的融合正成为企业创新的关键路径。从苹果的 Vision Pro 到 Meta 的智能拍摄眼镜,众多科技巨头纷纷投身于将大模型、多模态 AI 等顶尖技术与消费级硬件相结合的探索之旅。

随着AI大模型在今年618前夕打起价格战,当以GPT-4o为代表的多模态大模型将交互体验也推向更高的层次,也意味着杀手级AI应用或许真的来到了奇点时刻。如今AI行业的创业者已经不再聚焦大模型,而是开始尝试用AI赋能具体的应用场景。

一个5月份完成训练的大模型,无法对《黑神话·悟空》游戏内容相关问题给出准确回答。
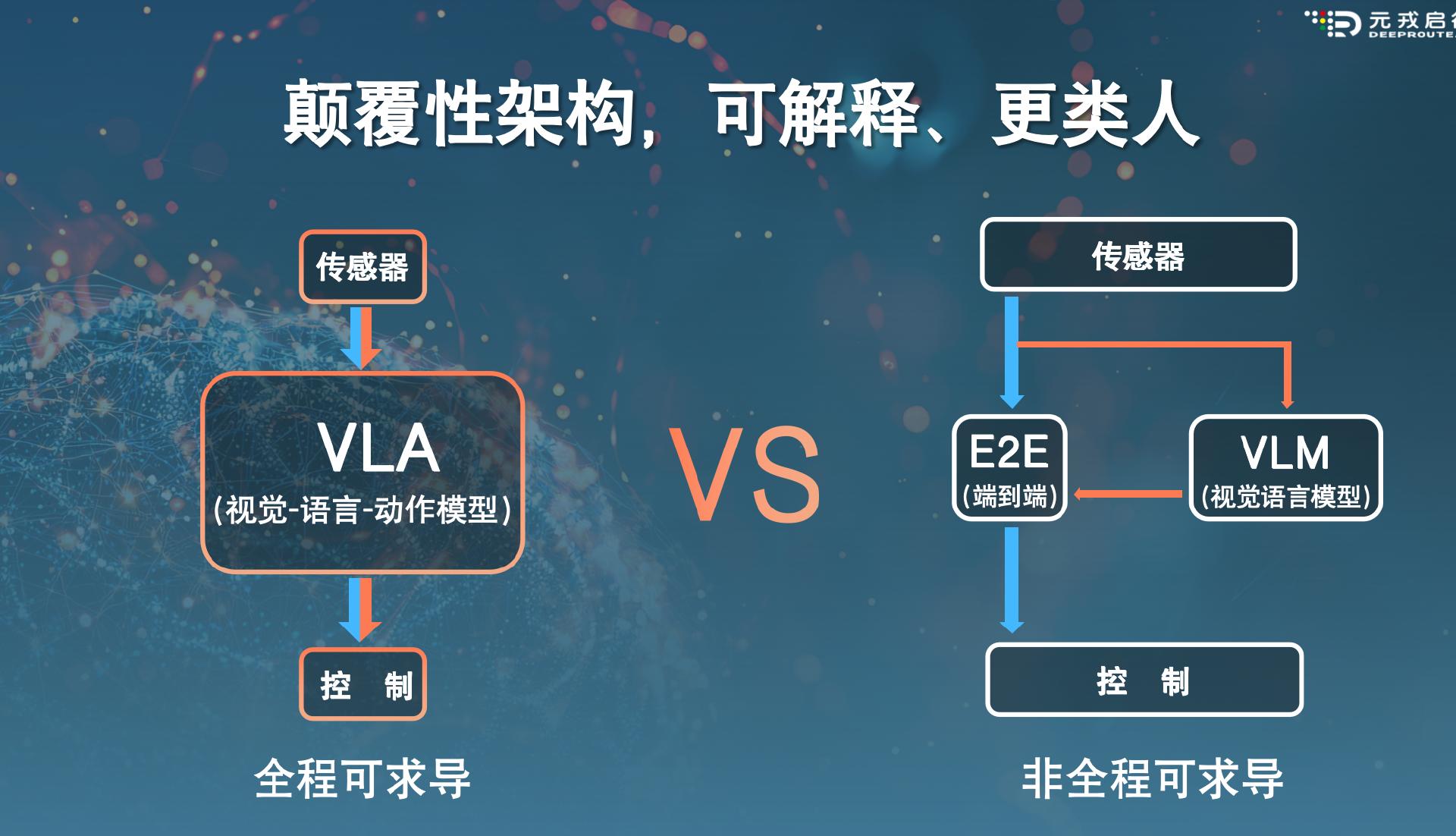
近期,智驾行业出现了一个融合了视觉、语言和动作的多模态大模型范式——VLA(Vision-Language-Action Model,即视觉-语言-动作模型),拥有更高的场景推理能力与泛化能力。不少智驾人士都将VLA视为当下“端到端”方案的2.0版本。

中国人民大学高瓴人工智能学院 GeWu 实验室、朝闻道机器人和 TeleAI 最近的合作研究揭示并指出了 “模态时变性”(Modality Temporality)现象,通过捕捉并刻画各个模态质量随物体操纵过程的变化,提升不同信息在具身多模态交互的感知质量,可显著改善精细物体操纵的表现。论文已被 CoRL2024 接收并选为 Oral Presentation。

MME-Finance 是一个专为金融领域设计的多模态基准测试,由同花顺财经旗下的 HiThink 研究团队联合多家高校共同开发,旨在评估和提升多模态大型语言模型(MLLMs)在金融领域的专业理解和推理能力。