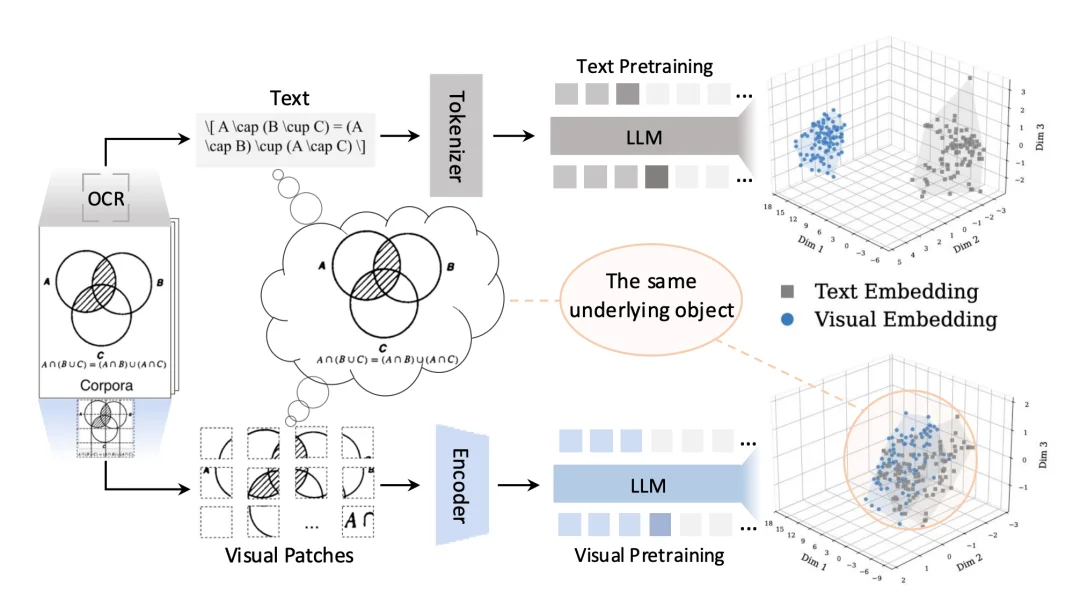
只读文本的AI,科学推理能力只有“看图”AI的1/3丨中科大
只读文本的AI,科学推理能力只有“看图”AI的1/3丨中科大目前,这项技术已成功应用于上海人工智能实验室Intern-S2-Preview 35B/397B系列多模态大模型的预训练中,有效提升了模型的科学推理与多模态理解能力。值得一提的是,相关研发均基于国产昇腾算力平台完成,并成功实现了面向大规模预训练的深度适配与优化。
来自主题: AI技术研报
7914 点击 2026-08-01 10:45
 搜索
搜索
目前,这项技术已成功应用于上海人工智能实验室Intern-S2-Preview 35B/397B系列多模态大模型的预训练中,有效提升了模型的科学推理与多模态理解能力。值得一提的是,相关研发均基于国产昇腾算力平台完成,并成功实现了面向大规模预训练的深度适配与优化。
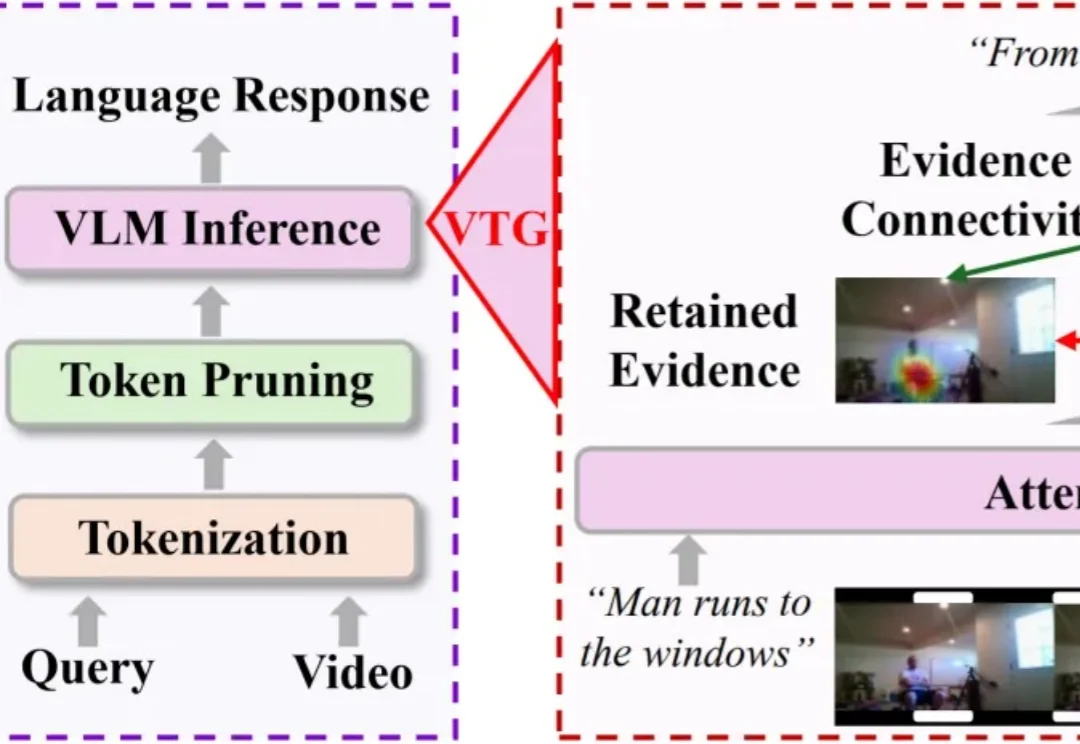
长视频理解,正在成为多模态大模型的重要能力。
BigMac 是原生多模场景下的流水并行训练新范式。它针对多模态大模型训练中计算效率与显存占用难以兼顾的问题,提出了依赖安全的嵌套流水线:以成熟的 LLM 流水线为主干,在不打乱 LLM 执行顺序的前提下,有序嵌入编码器和生成器计算,从而在不增加 LLM 流水线空泡、保持激活显存有界的同时,高效实现多模态流水训练。
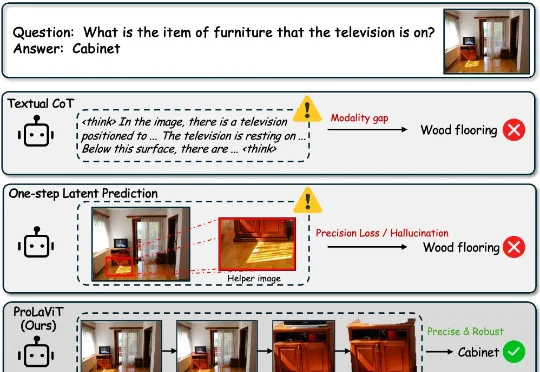
针对这一挑战,腾讯内容服务部 BAC 提出了一个名为 ProLaViT(Progressive Latent Visual Thought) 的全新框架。它的核心思想是:别急着下结论,先在连续隐空间里像人一样「步步推导」。 即让模型遵循 「定位 → 聚焦 → 分离」(Locate → Focus → Isolate) 的因果链,逐步收紧视觉注意力,最终精准锁定目标。
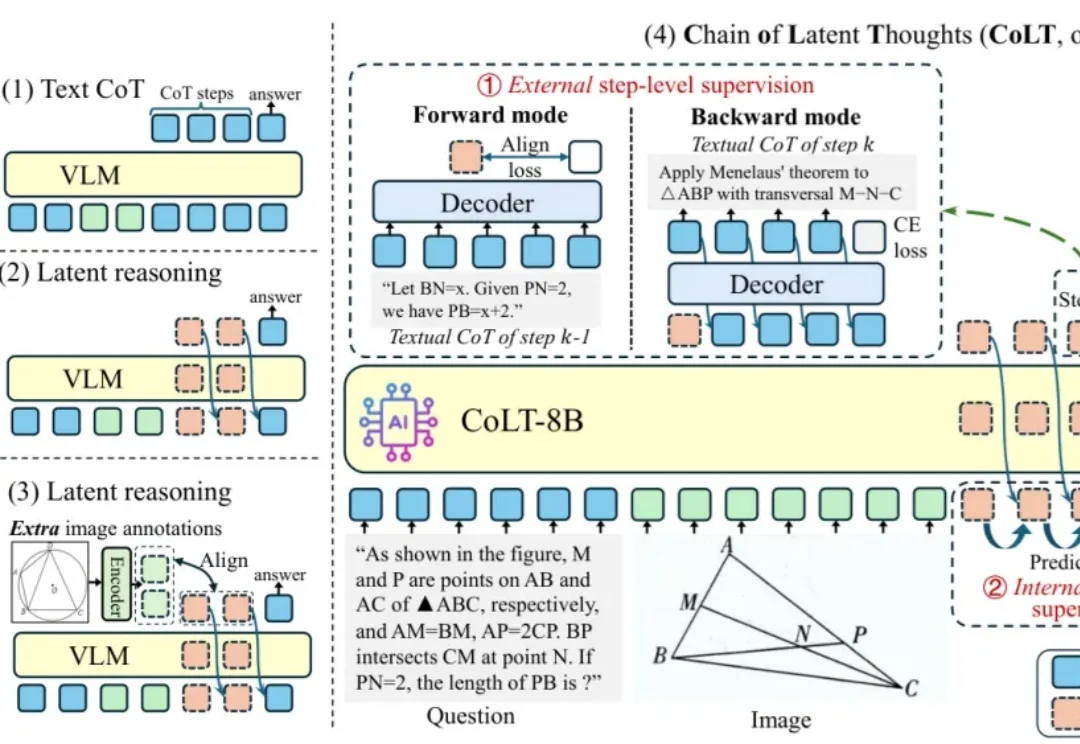
近年来,多模态大语言模型(MLLM)在视觉问答、图表理解、科学推理等任务上取得了令人瞩目的进展。

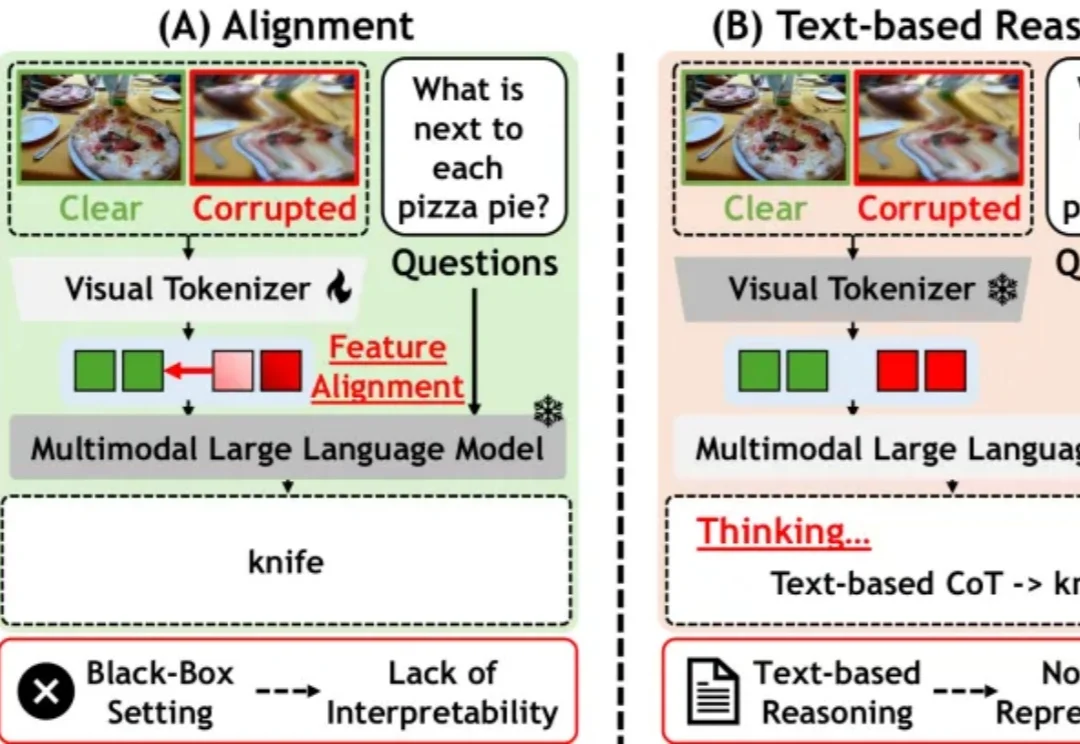
多模态大模型越来越会读图中文字,但最新研究显示,「读得出来」并不等于「防得住」。西湖大学 AGI Lab 的研究团队发现,当有害文本被渲染成低清、模糊或带噪图片后,模型在一个特定清晰度区间内反而更容易被越狱。
雨雪、雾霾、镜头噪点、压缩失真、夜间弱光……
想象这样一个惬意的周末: 空调带来阵阵凉意,你靠在沙发上看书,突然耳边传来“哒哒哒”的小碎步声,接着,玄关门边传来了一阵清脆、略带急切的“呜呜”声,还伴随着爪尖轻轻扒拉木门的声响。

早在 2023 年大模型快速发展期,哈工大张民教授立知大模型团队已开展多模态大模型驱动的视频内容创作智能体研究,并全球首发开源了电影制作智能体 FilmAgent 与动画片生成智能体 Anim-Director,受到国内外智能体研究者与文艺创作者的广泛关注。
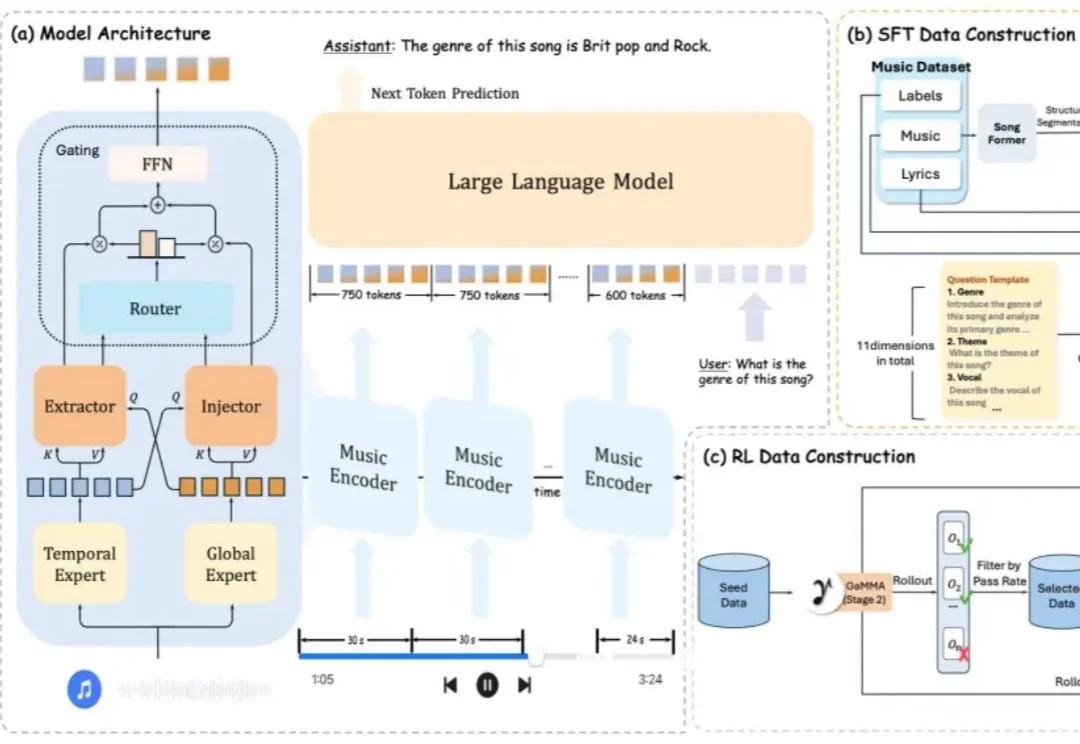
大模型的能力边界正在不断拓展,从文字到视觉,再到音频,全模态理解已渐成现实。然而,当你问一个多模态大模型「这首歌的高潮从第几秒开始?」或者「第 30 秒之后乐器编配发生了什么变化?」,得到的往往是一个模糊甚至错误的回答。