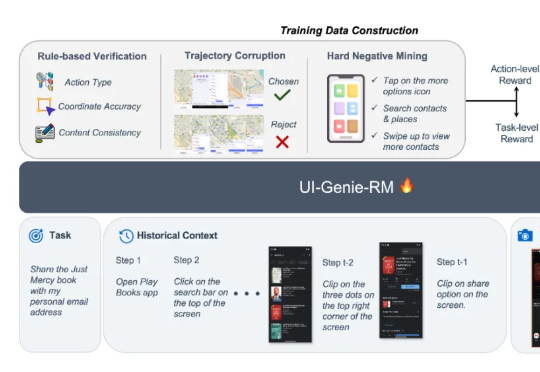
vivo AI Lab提出自我进化的移动GUI智能体,UI-Genie无需人工标注实现性能持续提升
vivo AI Lab提出自我进化的移动GUI智能体,UI-Genie无需人工标注实现性能持续提升本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le
来自主题: AI技术研报
8493 点击 2025-11-08 11:00
 搜索
搜索
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le
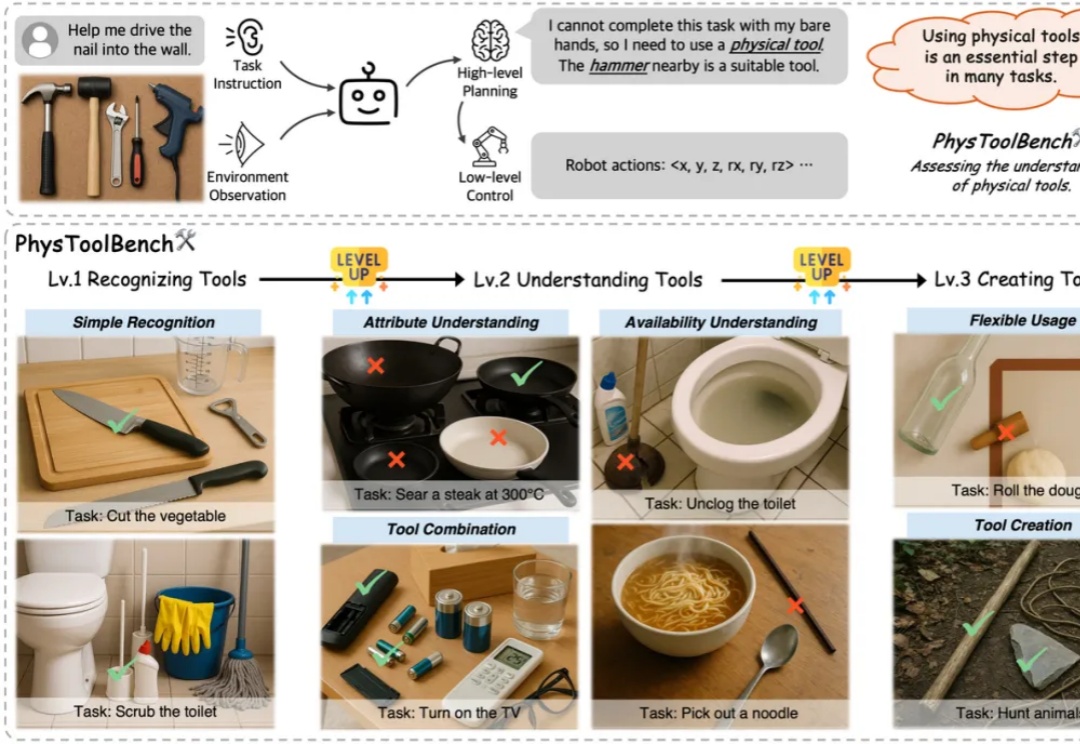
人类之所以能与复杂的物理世界高效互动,很大程度上源于对「工具」的使用、理解与创造能力。对任何通用型智能体而言,这同样是不可或缺的基本技能,对物理工具的使用会大大影响任务的成功率与效率。
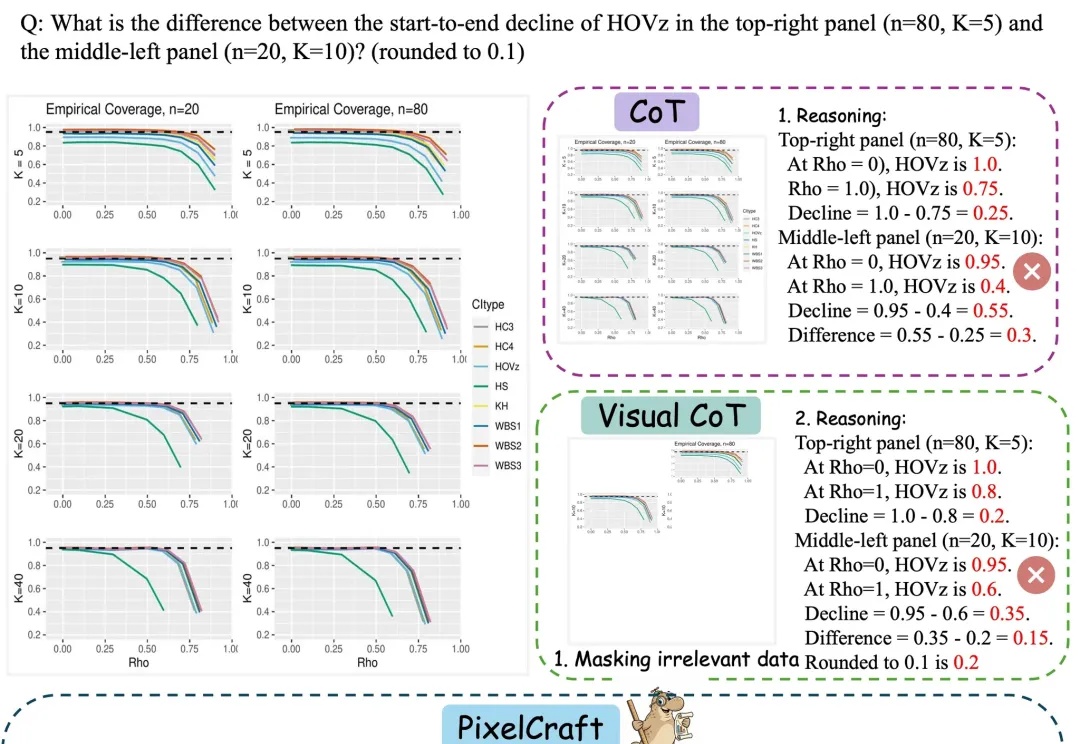
多模态大模型(MLLM)在自然图像上已取得显著进展,但当问题落在图表、几何草图、科研绘图等结构化图像上时,细小的感知误差会迅速放大为推理偏差。
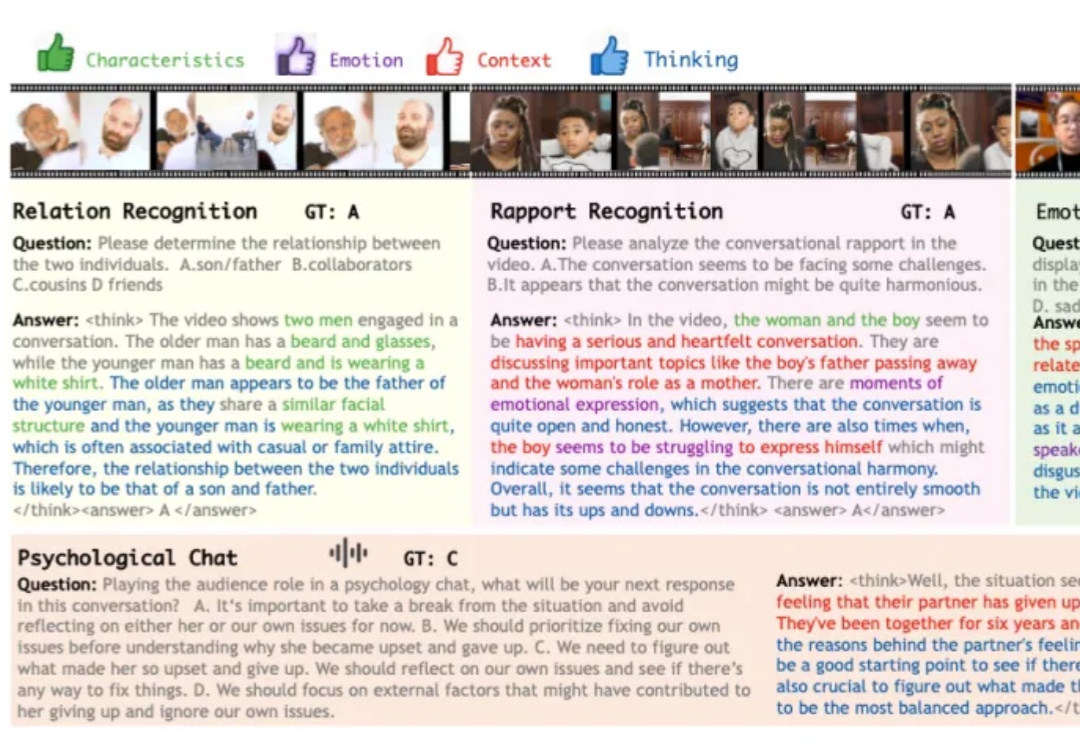
在科幻作品描绘的未来,人工智能不仅仅是完成任务的工具,更是为人类提供情感陪伴与生活支持的伙伴。在实现这一愿景的探索中,多模态大模型已展现出一定潜力,可以接受视觉、语音等多模态的信息输入,结合上下文做出反馈。

随着多模态大模型的不断演进,指令引导的图像编辑(Instruction-guided Image Editing)技术取得了显著进展。然而,现有模型在遵循复杂、精细的文本指令方面仍面临巨大挑战,往往需要用户进行多次尝试和手动筛选,难以实现稳定、高质量的「一步到位」式编辑。
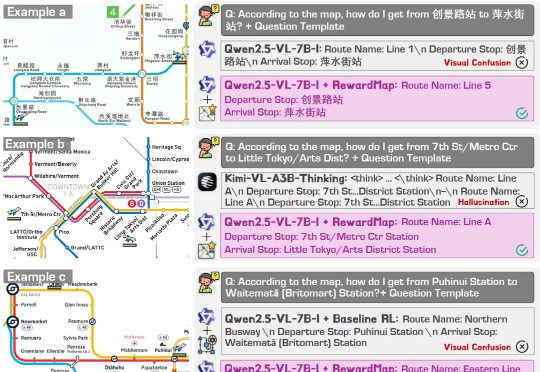
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
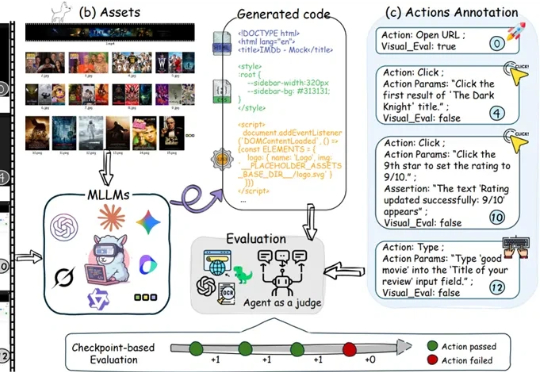
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。
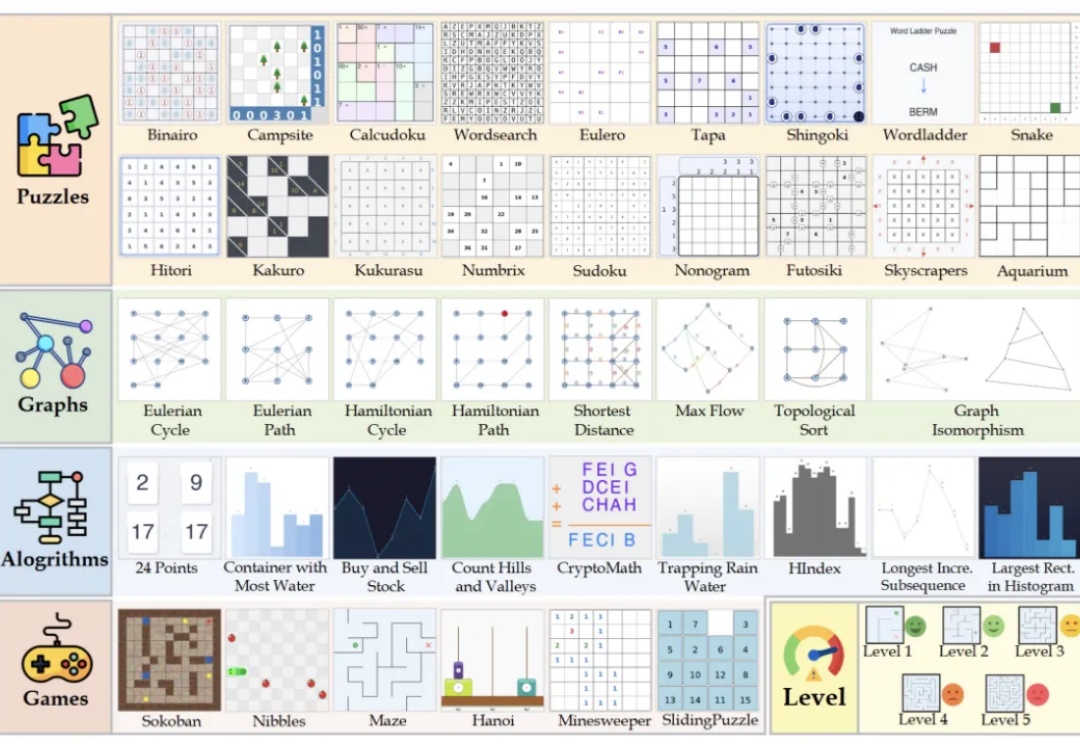
多模态大模型表现越来越惊艳,但人们也时常困于它的“耿直”。

多模态大模型首次实现像素级推理,指代、分割、推理三大任务一网打尽!
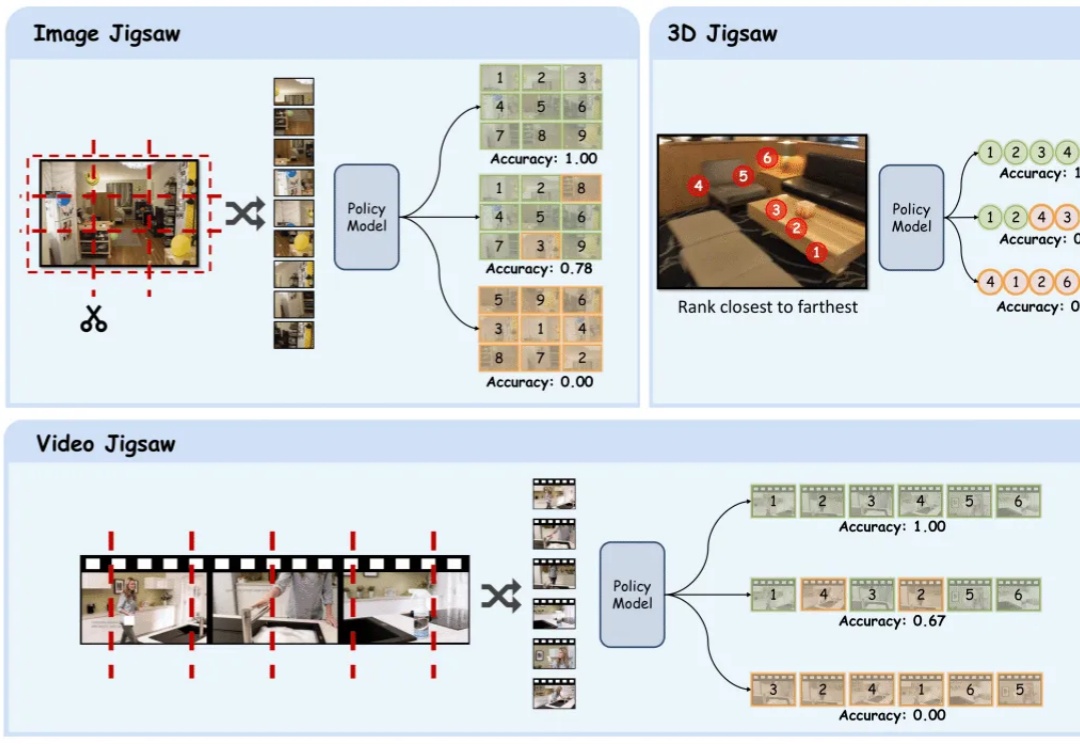
在多模态大模型的后训练浪潮中,强化学习驱动的范式已成为提升模型推理与通用能力的关键方向。