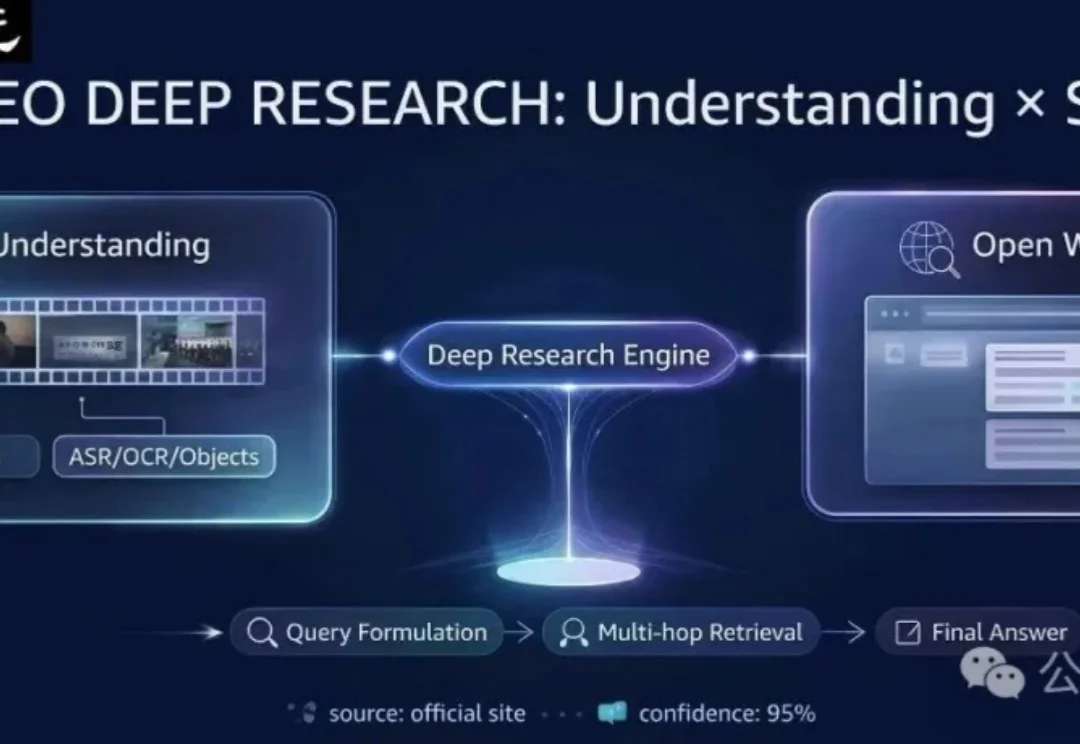
视频理解+开放网络搜索=首个视频Deep Research评测基准
视频理解+开放网络搜索=首个视频Deep Research评测基准现有的多模态模型往往被困在「视频」的孤岛里——它们只能回答视频内的问题。但在真实世界中,人类解决问题往往是「看视频找线索 -> 上网搜证 -> 综合推理」。
来自主题: AI技术研报
11379 点击 2026-01-22 16:10
 搜索
搜索
现有的多模态模型往往被困在「视频」的孤岛里——它们只能回答视频内的问题。但在真实世界中,人类解决问题往往是「看视频找线索 -> 上网搜证 -> 综合推理」。
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。
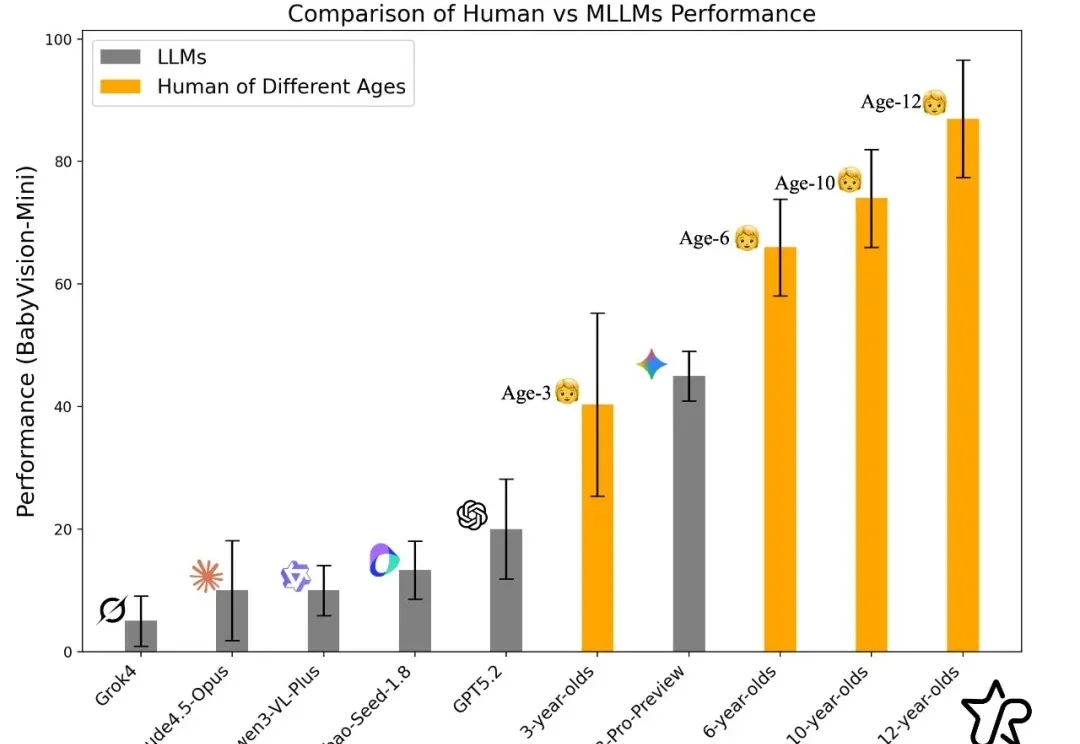
过去一年,大模型在语言与文本推理上突飞猛进:论文能写、难题能解、甚至在顶级学术 / 竞赛类题目上屡屡刷新上限。但一个更关键的问题是:当问题不再能 “用语言说清楚” 时,模型还能不能 “看懂”?
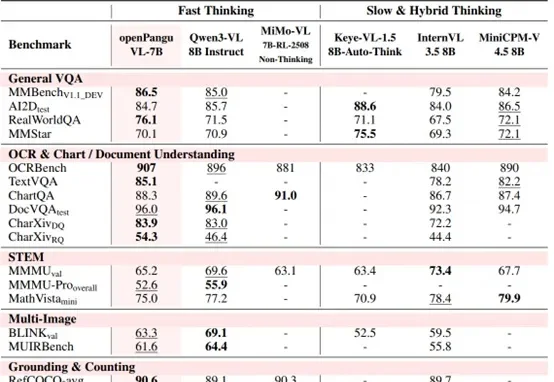
7B量级模型,向来是端侧部署与个人开发者的心头好。
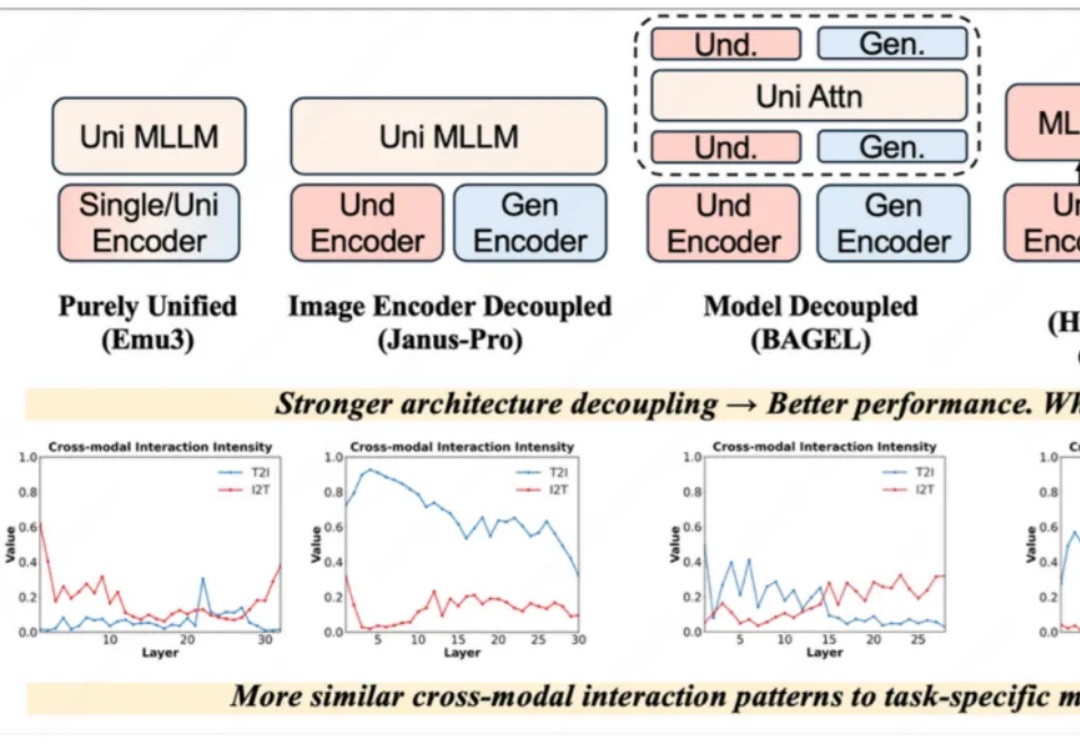
近一年以来,统一理解与生成模型发展十分迅速,该任务的主要挑战在于视觉理解和生成任务本身在网络层间会产生冲突。早期的完全统一模型(如 Emu3)与单任务的方法差距巨大,Janus-Pro、BAGEL 通过一步一步解耦模型架构,极大地减小了与单任务模型的性能差距,后续方法甚至通过直接拼接现有理解和生成模型以达到极致的性能。
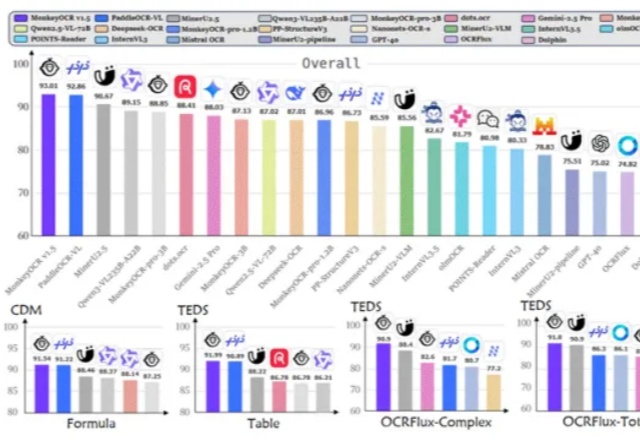
是金山派来的猴子,复杂文档解析有救了!

去年,谢赛宁(Saining Xie)团队发布了 Cambrian-1,一次对图像多模态模型的开放式探索。但团队没有按惯例继续推出 Cambrian-2、Cambrian-3,而是停下来思考:真正的多

当前机器人领域,基础模型主要基于「视觉-语言预训练」,这样可将现有大型多模态模型的语义泛化优势迁移过来。但是,机器人的智能确实能随着算力和数据的增加而持续提升吗?我们能预测这种提升吗?
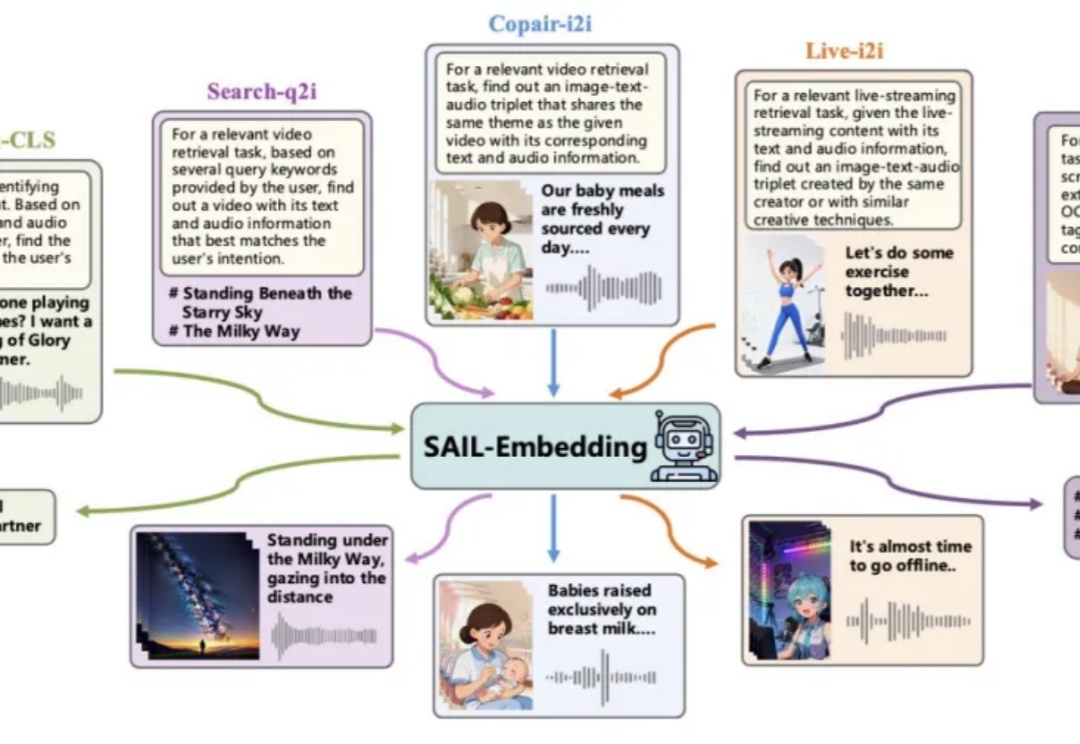
在短视频推荐、跨模态搜索等工业场景中,传统多模态模型常受限于模态支持单一、训练不稳定、领域适配性差等问题。
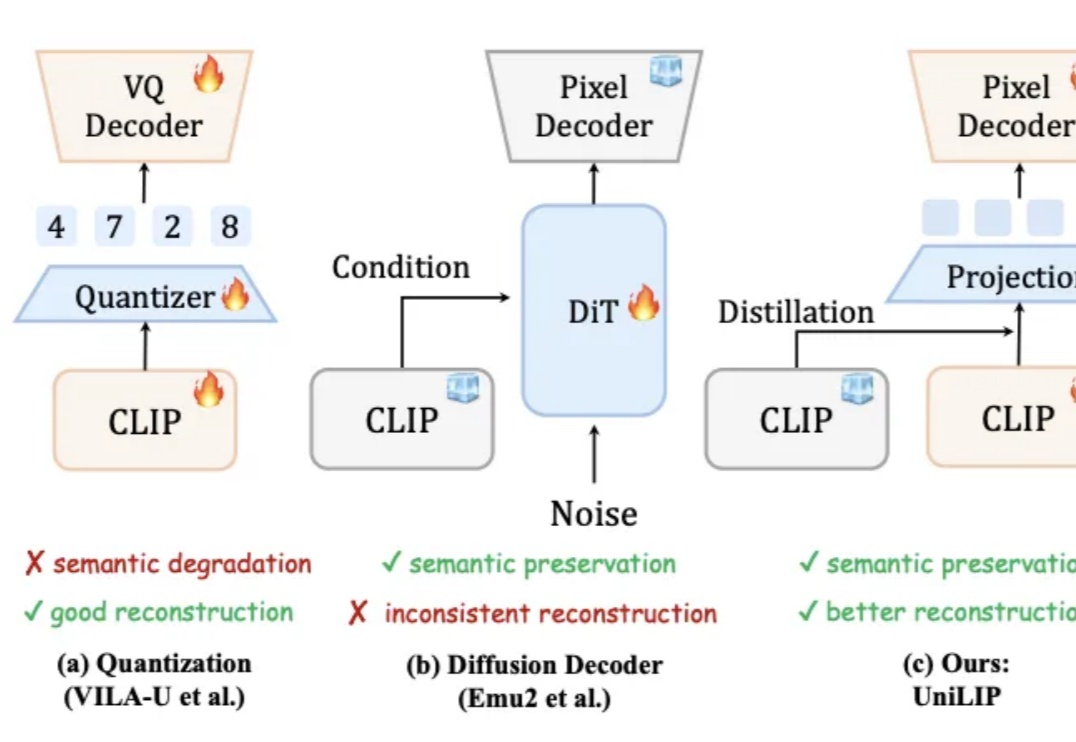
统一多模态模型要求视觉表征必须兼顾语义(理解)和细节(生成 / 编辑)。早期 VAE 因语义不足而理解受限。近期基于 CLIP 的统一编码器,面临理解与重建的权衡:直接量化 CLIP 特征会损害理解性能;而为冻结的 CLIP 训练解码器,又因特征细节缺失而无法精确重建。例如,RAE 使用冻结的 DINOv2 重建,PSNR 仅 19.23。