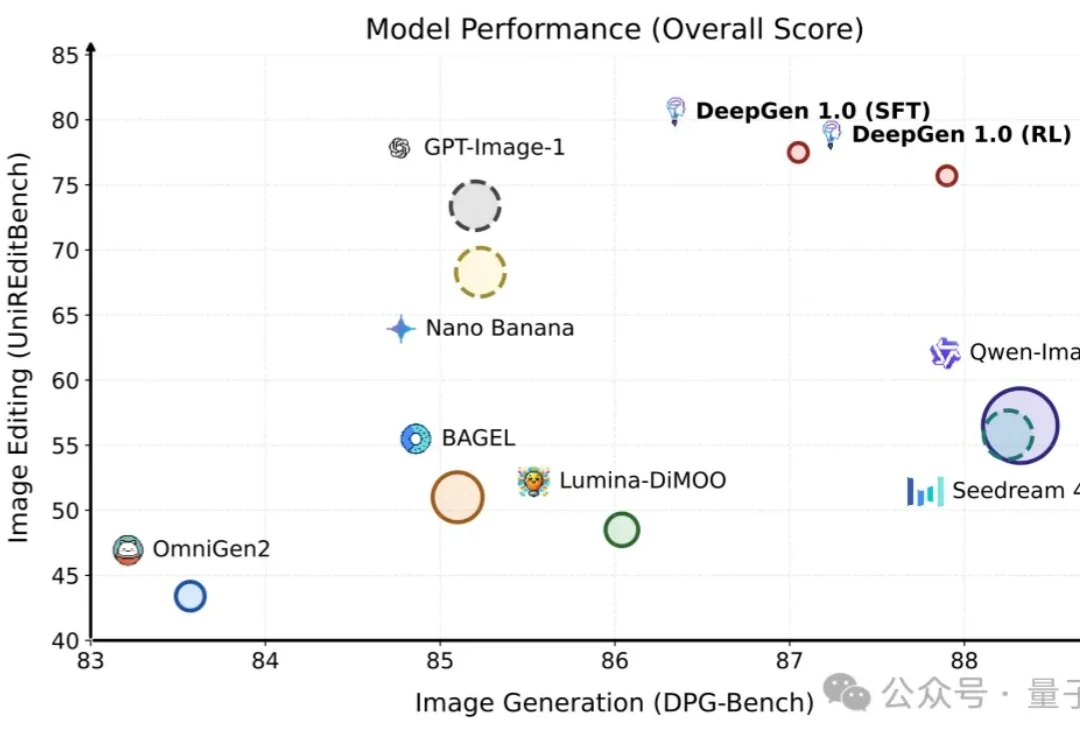
5B参数+4060Ti,10秒出图,全流程开源可复现!补齐统一多模态生成编辑的开源版图,让高质量图像生成真正变得更轻量、更普及
5B参数+4060Ti,10秒出图,全流程开源可复现!补齐统一多模态生成编辑的开源版图,让高质量图像生成真正变得更轻量、更普及统一多模态生成编辑模型,正在走向“重器化”
来自主题: AI技术研报
10643 点击 2026-03-18 16:15
 搜索
搜索
统一多模态生成编辑模型,正在走向“重器化”

多模态模型代码写得像老司机,却在数手指、量柱子时频频翻车?UniPat AI用五百行代码打造的SWE-Vision,让模型「掏出Python尺子」自我验证,一举拿下五大视觉相关基准SOTA。
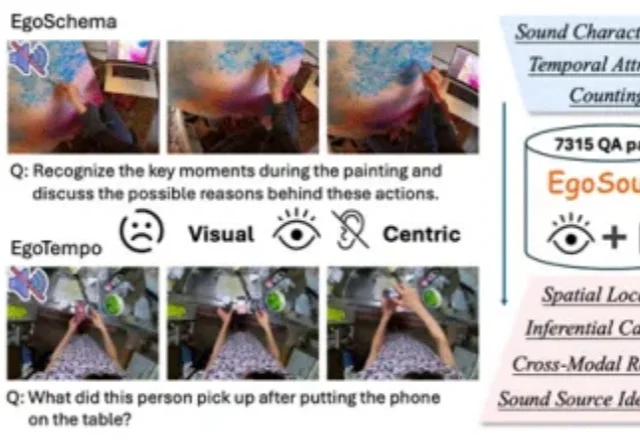
多模态大模型掉进真实世界,会“失聪”。
“时光流转,谁还用日记本。往事有底片为证。”—— 许嵩《摄影艺术》

NUS、ZJU、UW、Stanford、CUHK 联合提出 「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。仅用 2.4 万条数据微调 7B 统一模型,视觉推理平均提升 34.74%,多项任务比肩甚至超越 GPT-4o 和 Gemini 2.5 Flash。
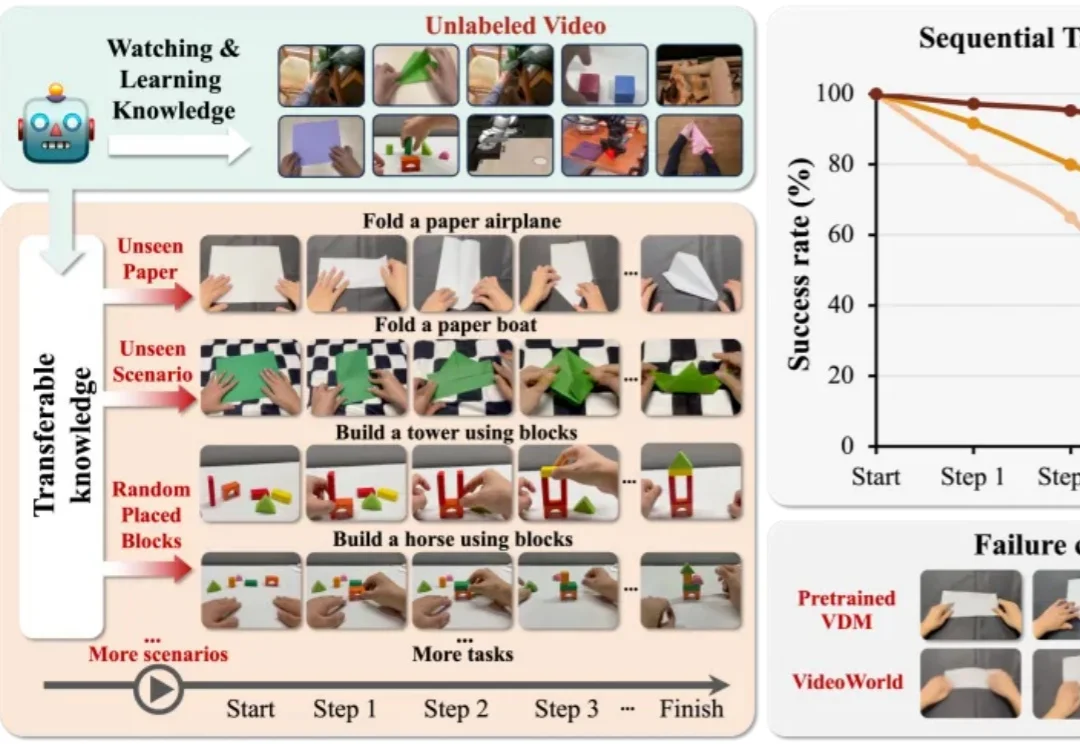
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。
多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。
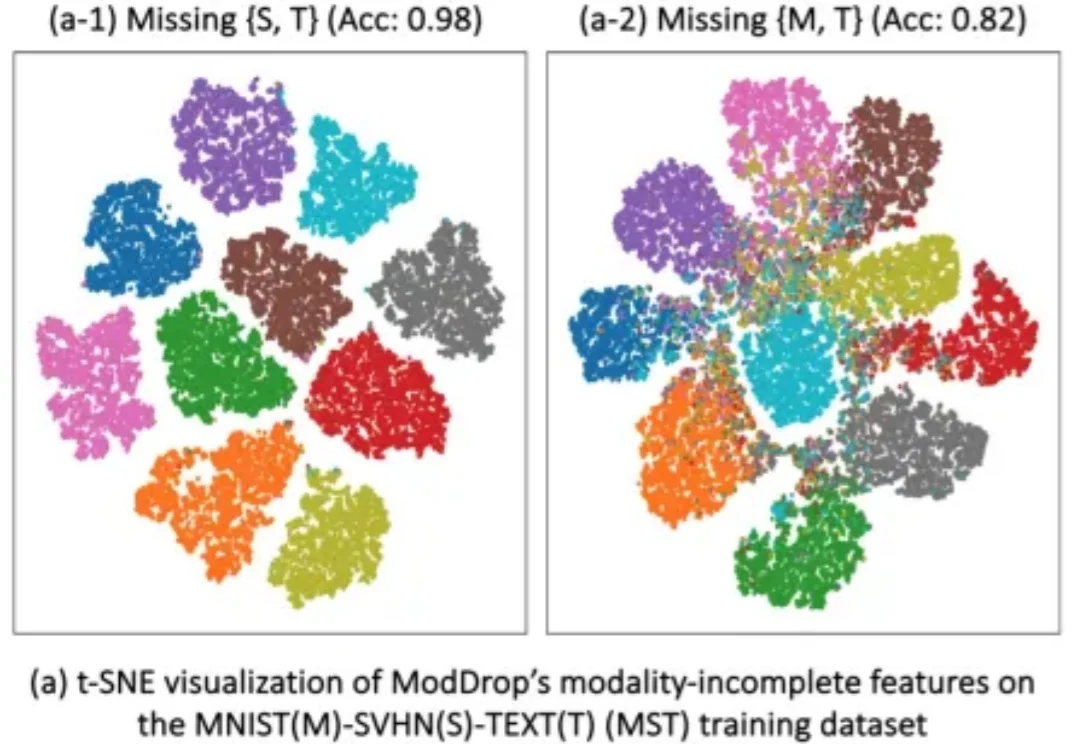
统一多模态模型在多模态内容理解与生成方面已展现出良好效果,但目前仍主要局限于图像领域。
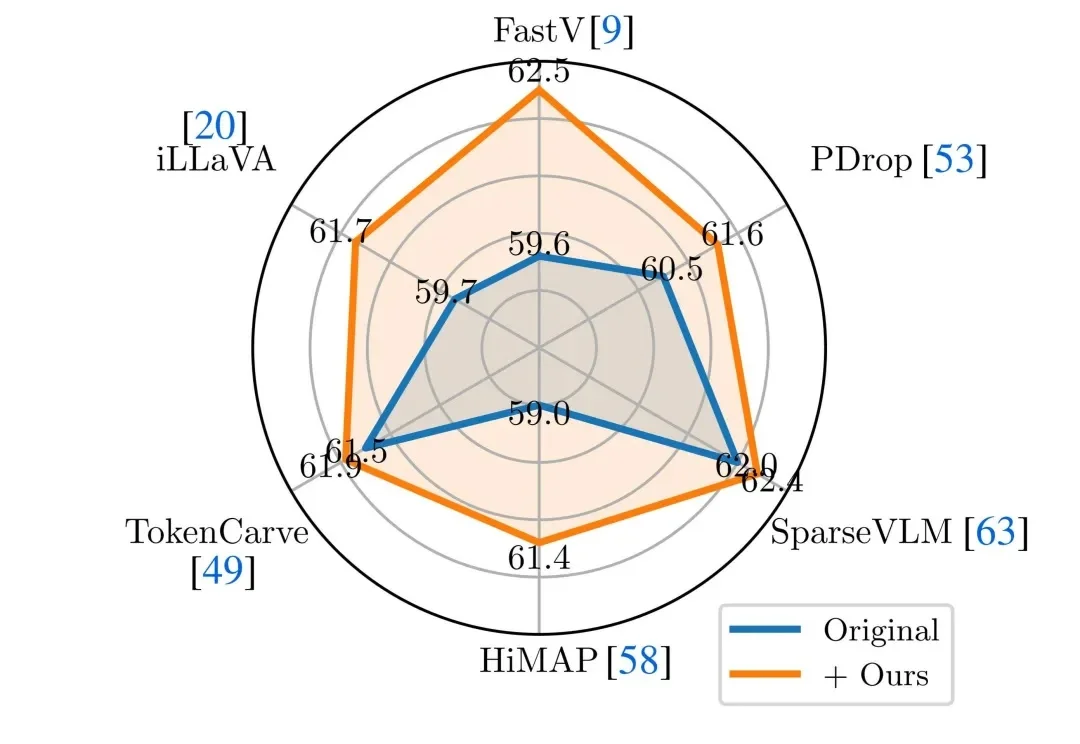
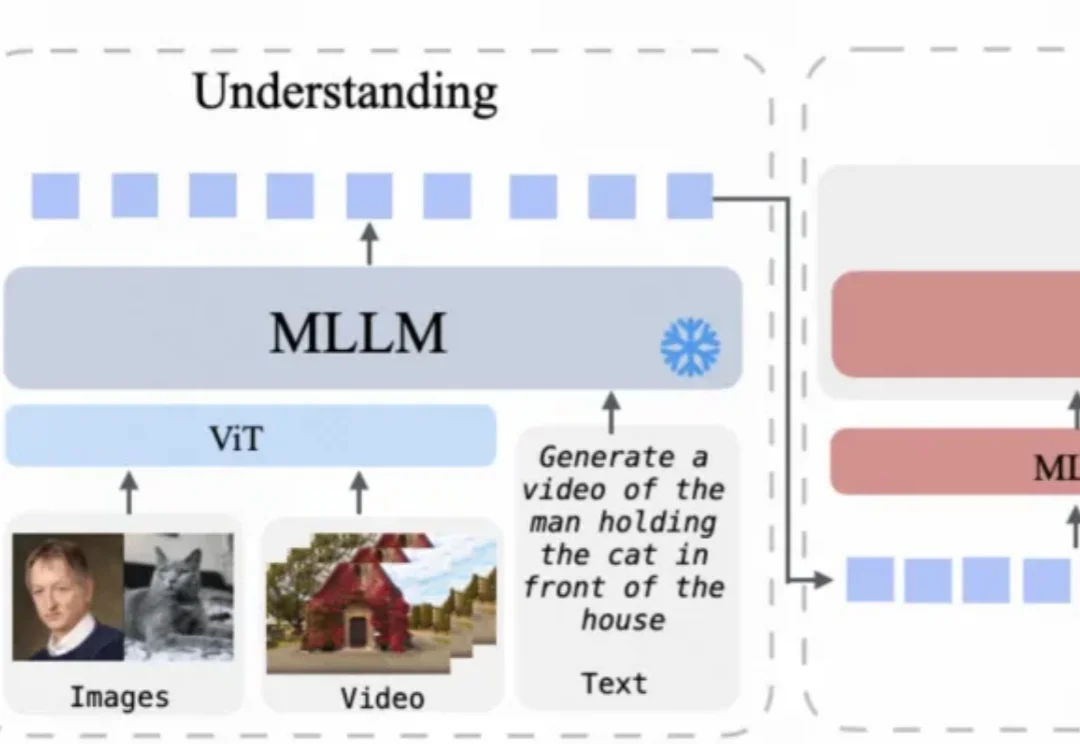
近年来,Vision-Language Models(视觉 — 语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。然而,这类模型在实际应用中往往面临推理开销大、效率受限的问题,研究者通常依赖 visual token pruning 等策略降低计算成本,其中 attention 机制被广泛视为衡量视觉信息重要性的关键依据。
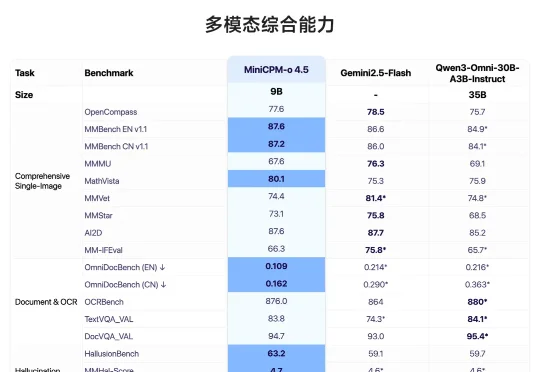
面壁开源了行业首个全双工全模态大模型 MiniCPM-o 4.5,相比已有多模态模型,MiniCPM-o 4.5 首次实现了「边看边听边说」以及「自主交互」的全模态能力,模型不再只是把视觉、语音作为静态输入处理,而是能够在实时、多模态信息流中持续感知环境变化,并在输出的同时保持对外界的理解。