
字节最强多模态模型登陆火山引擎!Seed1.5-VL靠20B激活参数狂揽38项SOTA
字节最强多模态模型登陆火山引擎!Seed1.5-VL靠20B激活参数狂揽38项SOTA字节拿出了国际顶尖水平的视觉–语言多模态大模型。
来自主题: AI资讯
12630 点击 2025-05-14 16:23
 搜索
搜索
字节拿出了国际顶尖水平的视觉–语言多模态大模型。

4月29日,腾讯TEG进行架构调整,新成立大语言和多模态模型部,并对数据平台和机器学习平台职责进行调整。

研究揭示早融合架构在低计算预算下表现更优,训练效率更高。混合专家(MoE)技术让模型动态适应不同模态,显著提升性能,堪称多模态模型的秘密武器。

视觉AI终极突破来了!英伟达等机构推出超强多模态模型DAM,仅3B参数,就能精准描述图像和视频中的任何细节。刚刚,英伟达联手UC伯克利、UCSF团队祭出首个神级多模态模型——Describe Anything Model(DAM),仅3B参数。

GPT-4o更新的端到端多模态模型,让创意端获得前所未有的自由度。
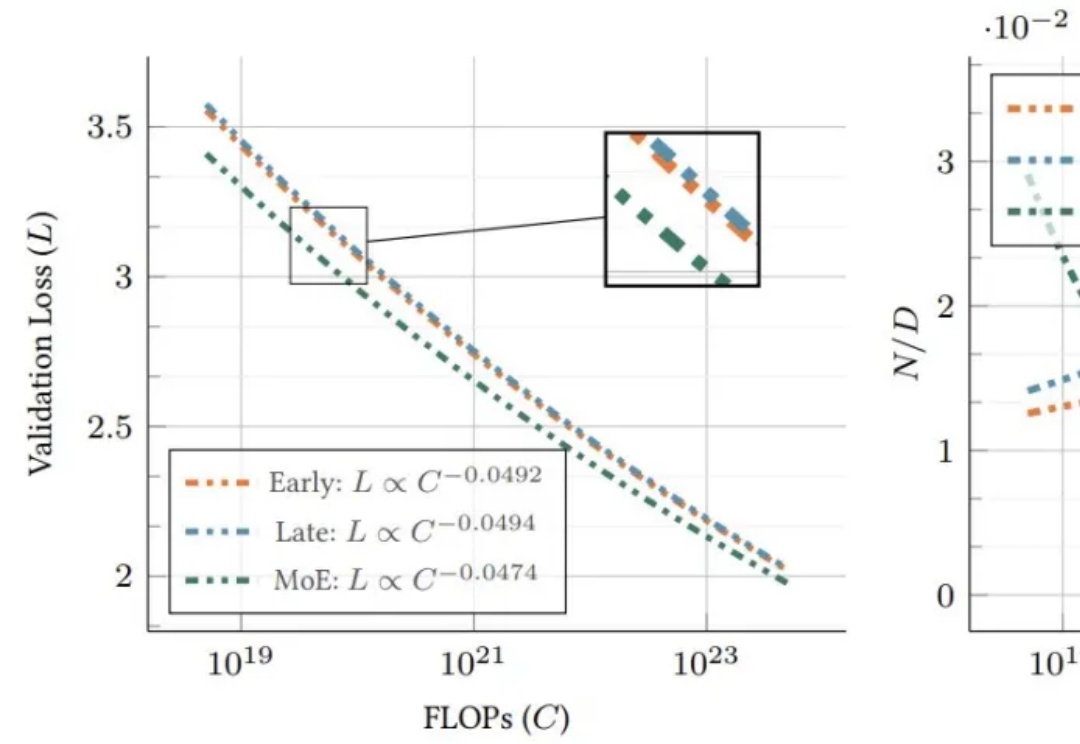
让大模型进入多模态模式,从而能够有效感知世界,是最近 AI 领域里人们一直的探索目标。
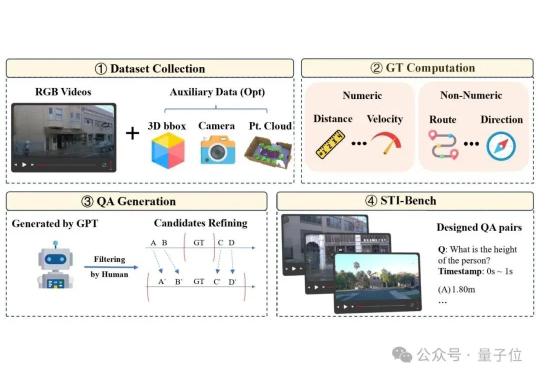
多模态大语言模型(MLLM)在具身智能和自动驾驶“端到端”方案中的应用日益增多,但它们真的准备好理解复杂的物理世界了吗?
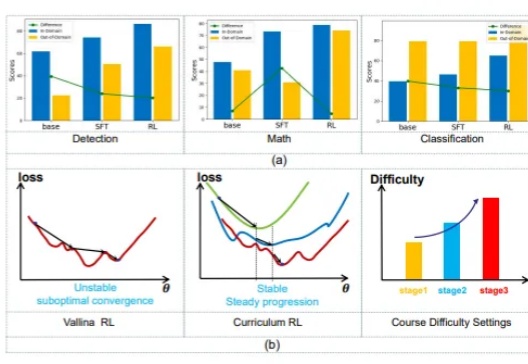
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。

来自Meta和NYU的团队,刚刚提出了一种MetaQuery新方法,让多模态模型瞬间解锁多模态生成能力!令人惊讶的是,这种方法竟然如此简单,就实现了曾被认为需要MLLM微调才能具备的能力。

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。