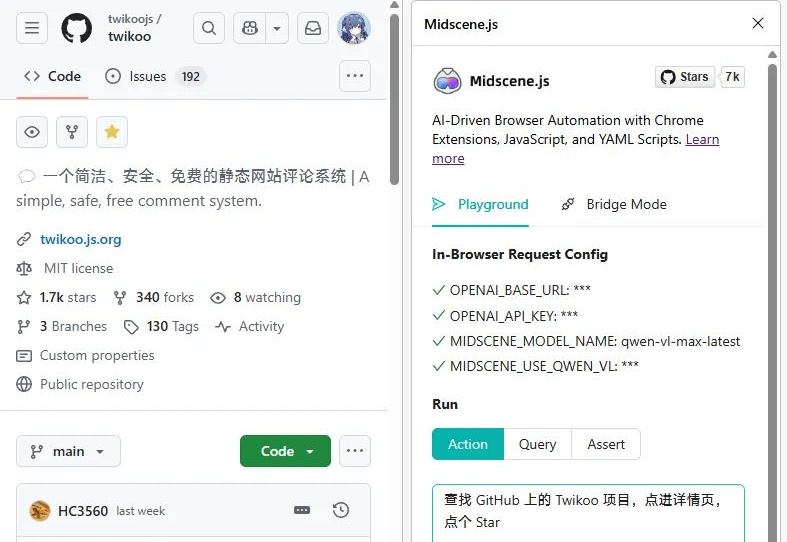
用多模态模型,写新一代爬虫
用多模态模型,写新一代爬虫字节有一个很实用但不怎么火的项目,叫 Midscene.js,Chrome 商店上的安装数仅有 1 万,它是一个由多模态模型驱动的前端自动化测试插件。自动化测试我平常很少用到,但我发现它特别适合用来写爬虫……
来自主题: AI技术研报
11484 点击 2025-04-02 16:09
 搜索
搜索
字节有一个很实用但不怎么火的项目,叫 Midscene.js,Chrome 商店上的安装数仅有 1 万,它是一个由多模态模型驱动的前端自动化测试插件。自动化测试我平常很少用到,但我发现它特别适合用来写爬虫……
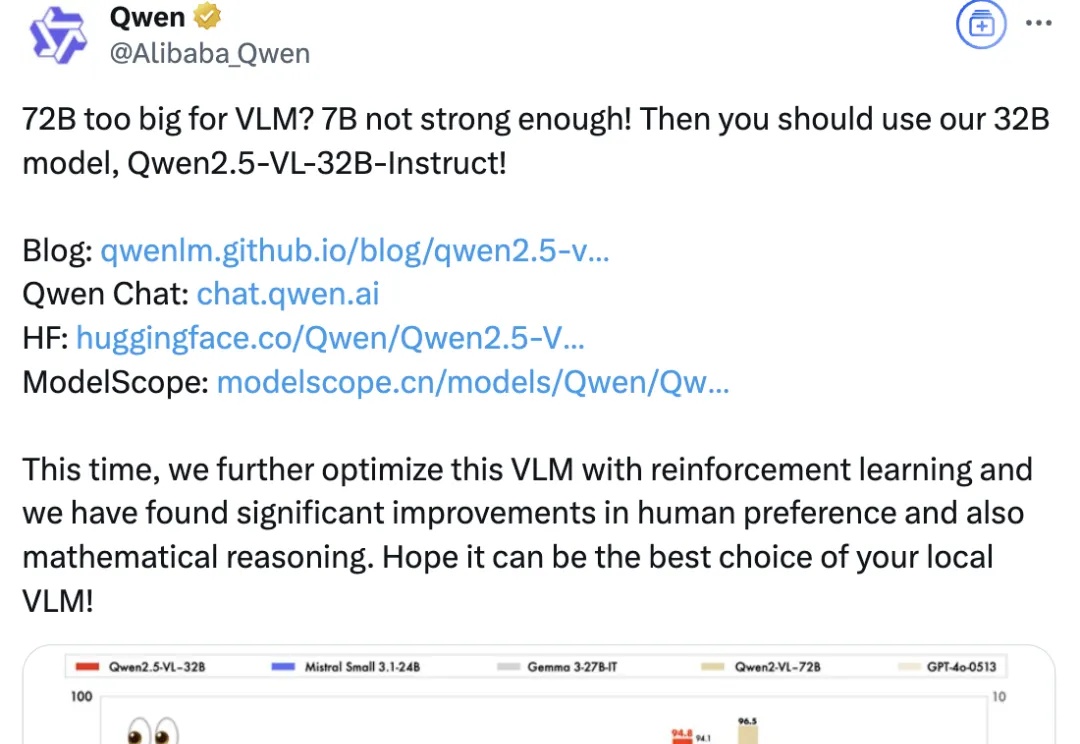
就在DeepSeek-V3更新的同一夜,阿里通义千问Qwen又双叒叕一次梦幻联动了——

微软研究院官宣开源多模态AI——Magma模型。首个能在所处环境中理解多模态输入并将其与实际情况相联系的基础模型。

基于闭源评测基准,近期司南针对国内外主流多模态大模型进行了全面评测,现公布司南首期多模态模型闭源评测榜单。首期榜单共包含 48 个多模态模型,其中包含:3 个国内 API 模型:GLM-4v-Plus-20250111 (智谱),Step-1o (阶跃),BailingMM-Pro-0120 (蚂蚁)

近年来大语言模型(LLM)的迅猛发展正推动人工智能迈向多模态融合的新纪元。然而,现有主流多模态大模型(MLLM)依赖复杂的外部视觉模块(如 CLIP 或扩散模型),导致系统臃肿、扩展受限,成为跨模态智能进化的核心瓶颈。

刚刚,阶跃星辰联合吉利汽车集团,开源了两款多模态大模型!新模型共2款:全球范围内参数量最大的开源视频生成模型Step-Video-T2V行业内首款产品级开源语音交互大模型Step-Audio多模态卷王开始开源多模态模型,其中Step-Video-T2V采用的还是最为开放宽松的MIT开源协议,可任意编辑和商业应用。
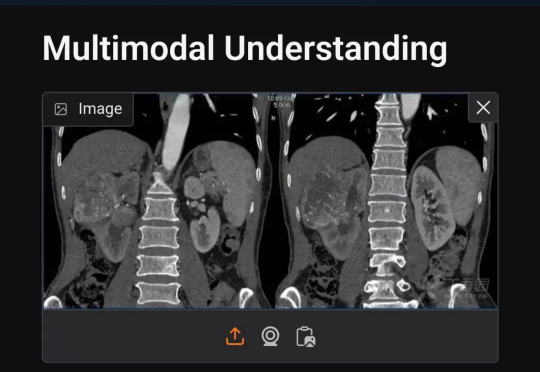
就在除夕前的晚上(2025 年 1 月 27 日),Deepseek 发布了多模态模型 Janus-Pro-7B,该模型在图像生成和多模态理解方面都超过了OpenAI的DALL-E 3(虽然也一般般),我相信能文生图功能一定很优秀了,今天搞点特殊的,测试下图像理解能力对专业的医学影像有没有应用的可行性,以下是常见的五种医学影像测试。

梁文锋带领着DeepSeek,还在继续搅动大模型行业。继用R1模型炸场之后,1月28日凌晨,除夕夜前一晚,DeepSeek又开源了其多模态模型Janus-Pro-7B,宣布在GenEval和DPG-Bench基准测试中击败了DALL-E 3(来自 OpenAI)和Stable Diffusion。
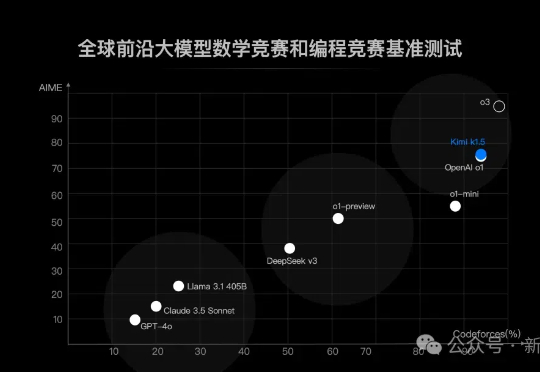
来了来了,月之暗面首个「满血版o1」来了!这是除OpenAI之外,首次有多模态模型在数学和代码能力上达到了满血版o1的水平。

以自研的“1+N”多模态模型系统,打造3D动态内容为核心的交互产品。