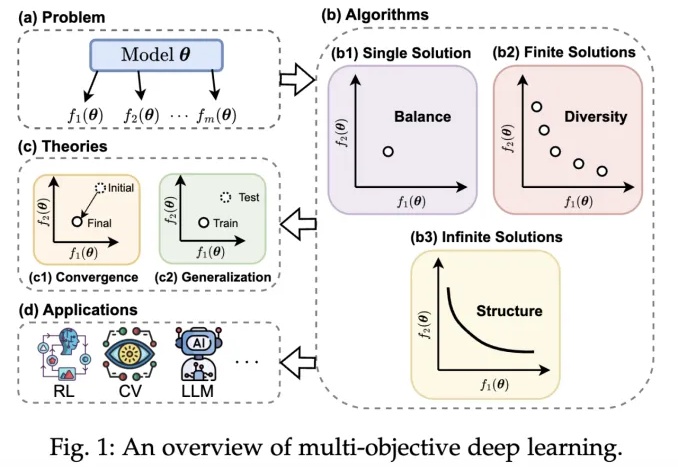
深度学习的平衡之道:港科大、港城大等团队联合发布多目标优化最新综述
深度学习的平衡之道:港科大、港城大等团队联合发布多目标优化最新综述近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。
来自主题: AI技术研报
7083 点击 2025-03-19 10:30
 搜索
搜索
近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。

CGPO框架通过混合评审机制和约束优化器,有效解决了RLHF在多任务学习中的奖励欺骗和多目标优化问题,显著提升了语言模型在多任务环境中的表现。CGPO的设计为未来多任务学习提供了新的优化路径,有望进一步提升大型语言模型的效能和稳定性。