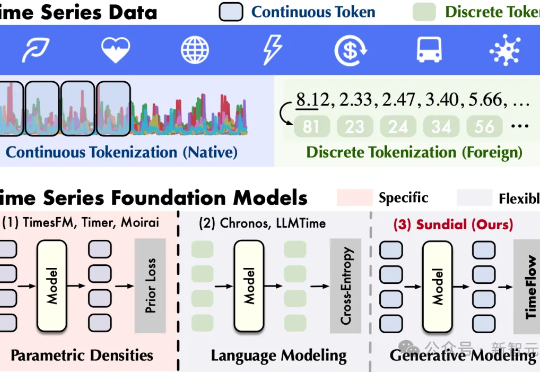
首个「万亿级时间点」预训练,清华发布生成式时序大模型日晷 | ICML Oral
首个「万亿级时间点」预训练,清华发布生成式时序大模型日晷 | ICML Oral清华大学软件学院发布生成式时序大模型——日晷(Sundial)。告别离散化局限,无损处理连续值,基于流匹配生成预测,缓解预训练模式坍塌,支持非确定性概率预测,为决策过程提供动态支持。
来自主题: AI资讯
10643 点击 2025-06-20 15:34
 搜索
搜索
清华大学软件学院发布生成式时序大模型——日晷(Sundial)。告别离散化局限,无损处理连续值,基于流匹配生成预测,缓解预训练模式坍塌,支持非确定性概率预测,为决策过程提供动态支持。
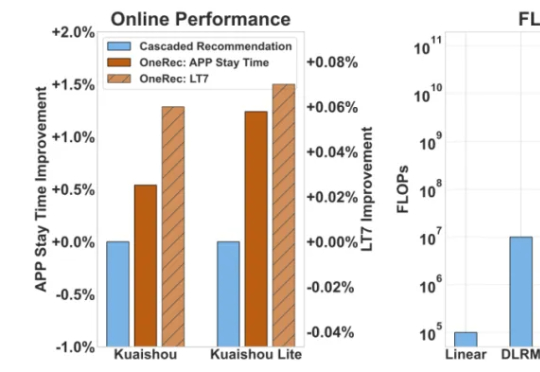
人人都绕不开的推荐系统,如今正被注入新的 AI 动能。 随着 AI 领域掀起一场由大型语言模型(LLM)引领的生成式革命,它们凭借着强大的端到端学习能力、海量数据理解能力以及前所未有的内容生成潜力,开始重塑各领域的传统技术栈。

从 8.8 万篇文献中提取 1.4 万种材料的化学组成
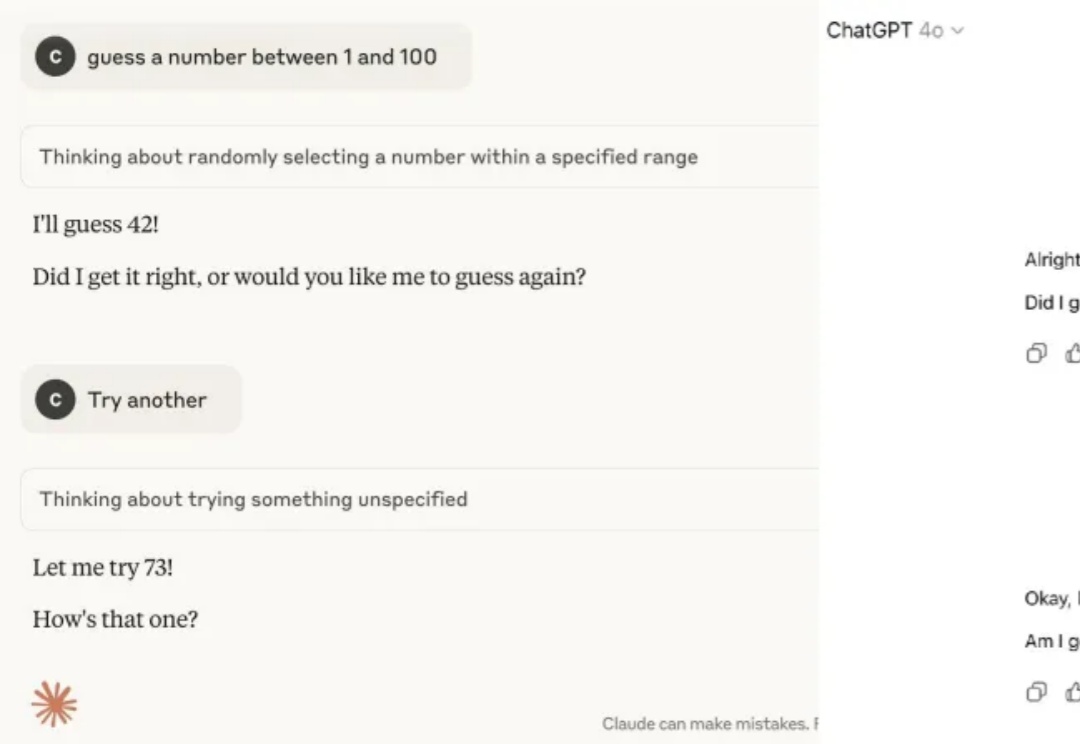
42,这个来自《银河系漫游指南》的「生命、宇宙以及一切问题的终极答案」已经成为一个尽人皆知的数字梗,似乎就连 AI 也格外偏好这个数字。

AI上瘾堪比「吸毒」!MIT最新研究惊人发现:长期依赖大模型,学习能力下降、大脑受损,神经连接减少47%。AI提高效率的说法,或许根本就是误解!
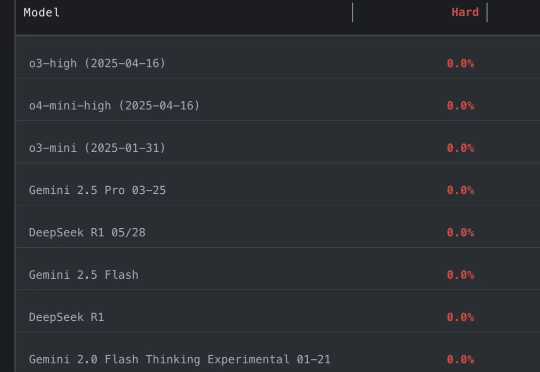
好夸张…… 参赛大模型全军覆没,通通0分。 谢赛宁等人出题,直接把o3、Gemini-2.5-pro、Claude-3.7、DeepSeek-R1一众模型全都难倒。

上世纪 50 年代信息论和 DNA 双螺旋的发现,点亮了生命科学与数字互联网这两个最关键的科技树;今天 AI for Science 开始将这两股洪流汇聚并指数级加速。 大模型对生物系统这样复杂、非线性的系统有着前所未有的理解和生成能力,有望成为加速科学发现的关键引擎。

据知情人士透露,代表亚马逊、亚马逊、微软和Meta的游说团体INCOMPAS,正敦促参议院通过一项为期10年的禁令,禁止各州推出自己的人工智能立法。这场游说活动的核心人物、INCOMPAS首席执行官、前国会议员Chip Pickering正代表他所在的科技行业协会的成员,倡导这项提案。
谷歌Gemini 2.5系列大模型技术报告发布,一大重点居然是AI玩《宝可梦》?
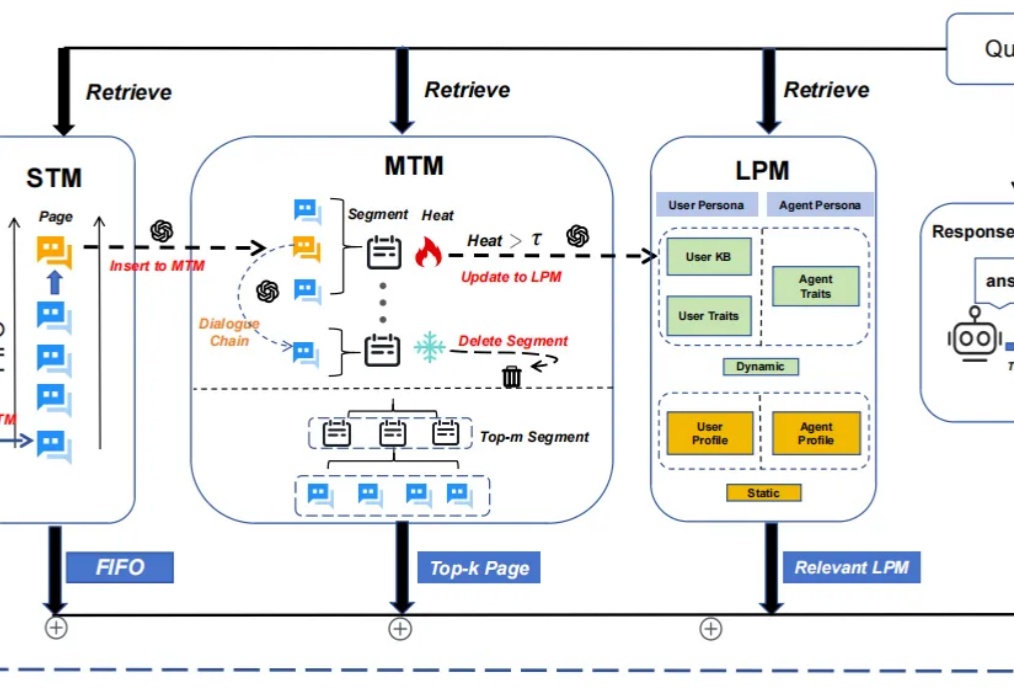
随着大模型应用场景的不断拓展,其在处理长期对话时逐渐暴露出的记忆局限性日益凸显,主要表现为固定长度上下文窗口导致的“健忘”问题。