# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
好夸张……
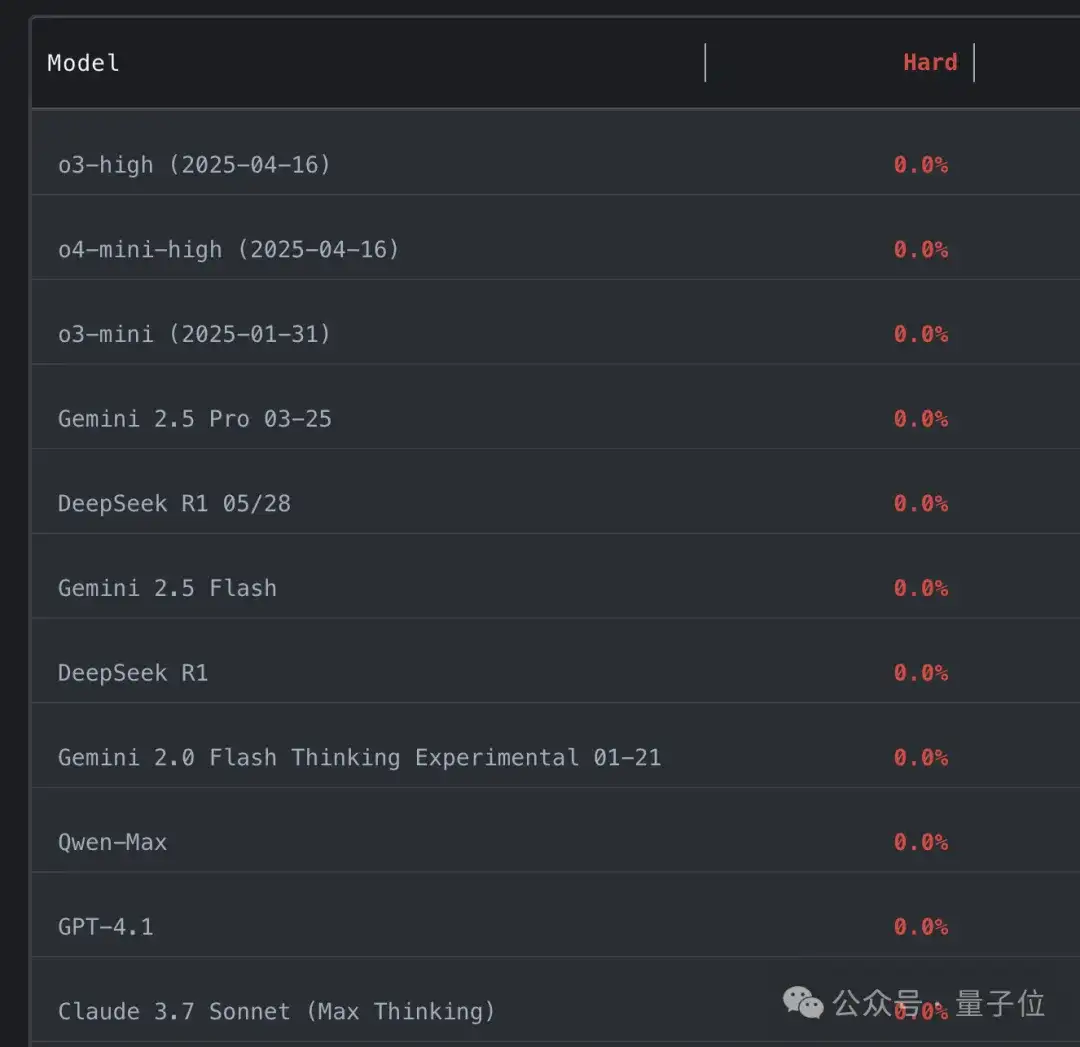
参赛大模型全军覆没,通通0分。
谢赛宁等人出题,直接把o3、Gemini-2.5-pro、Claude-3.7、DeepSeek-R1一众模型全都难倒。
到底是什么让一众领先模型一败涂地?

LiveCodeBench Pro:一个包含来自IOI、Codeforces和ICPC的竞赛级编程问题的实时基准测试。
题库还每日更新,来预防LLMs“背题”,不得不说这太狠了(doge)。

谢赛宁虽然也参与了这项工作,但他谦虚地说自己只是个啦啦队成员。
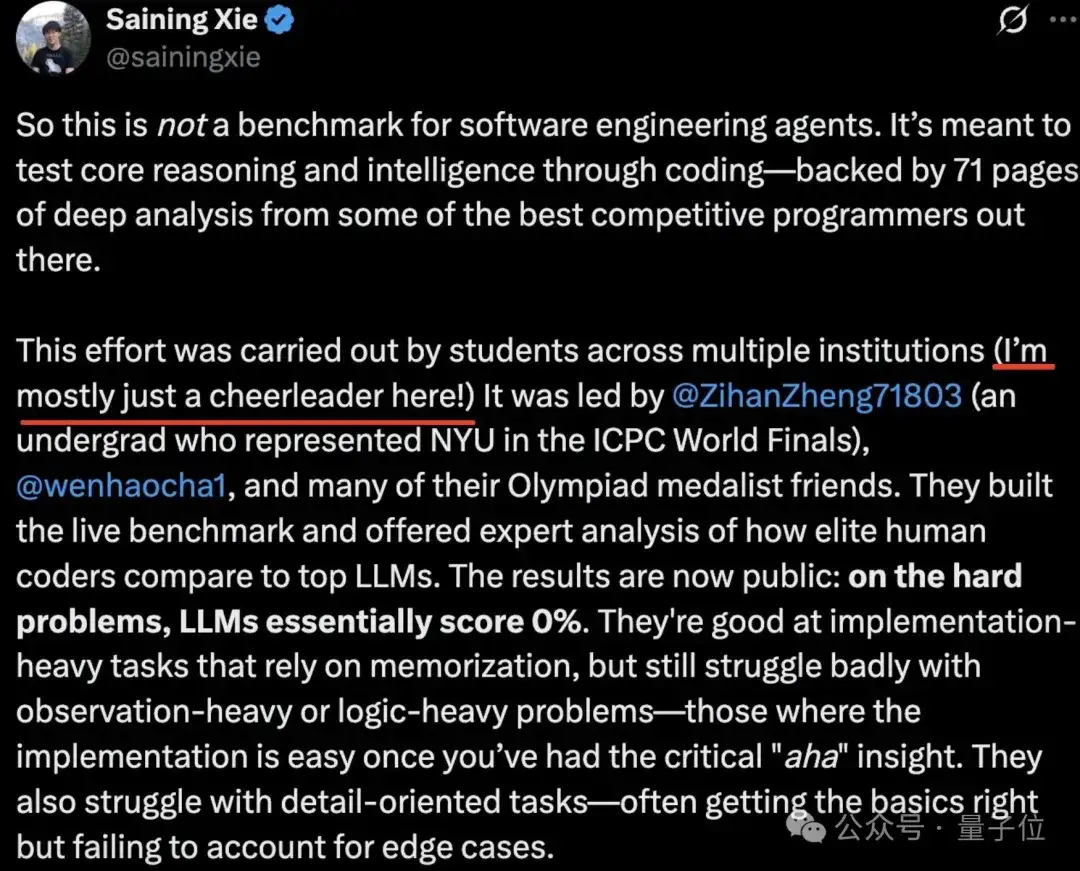
此前有报道称,LLM编程现在已超越人类专家,但本次测试结果表明并非如此。
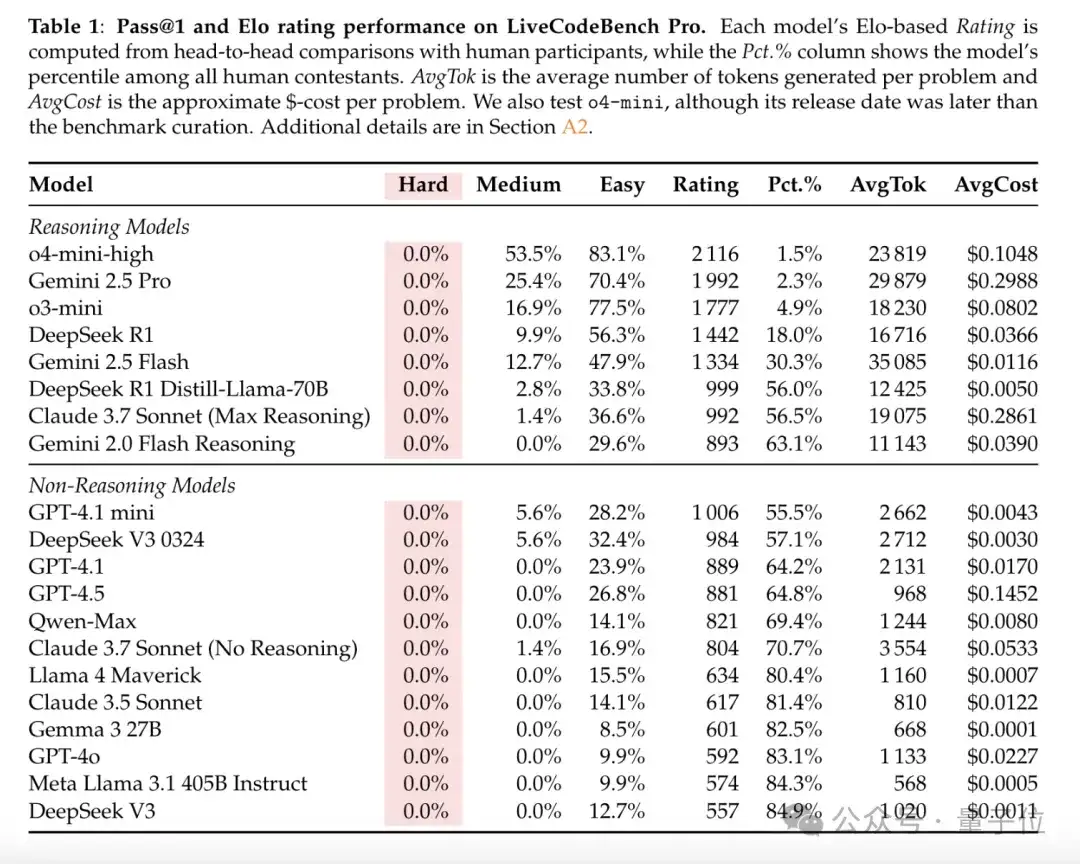
表现最佳的模型,在中等难度题上的一次通过率仅53%,难题通过率更是为0。
即使是最好的模型o4-mini-high,一旦工具调用被屏蔽,Elo也只有2100,远低于真正大师级的2700传奇线。
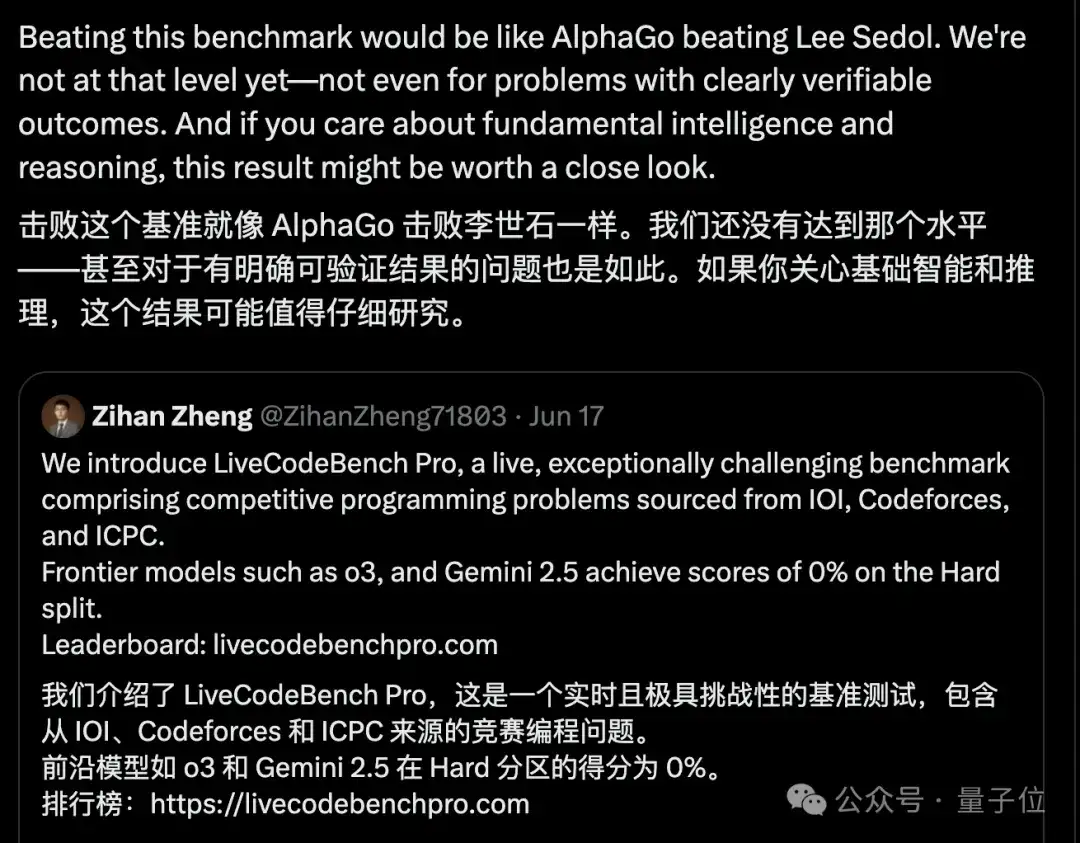
谢赛宁表示:
击败这个基准就像AlphaGo击败李世石一样。我们还没有达到那个水平——甚至对于有明确可验证结果的问题也是如此。
LiveCodeBench Pro:动态题库考验LLMs算法逻辑深度
测试是如何构建的
该基准由一众奥林匹克获奖者构建,在比赛结束后立即收集每道Codeforces、ICPC和IOI题目,在互联网上出现正确答案之前捕获每个问题。
每日更新题库,以减少数据污染,保证评估环境的真实性与挑战性。
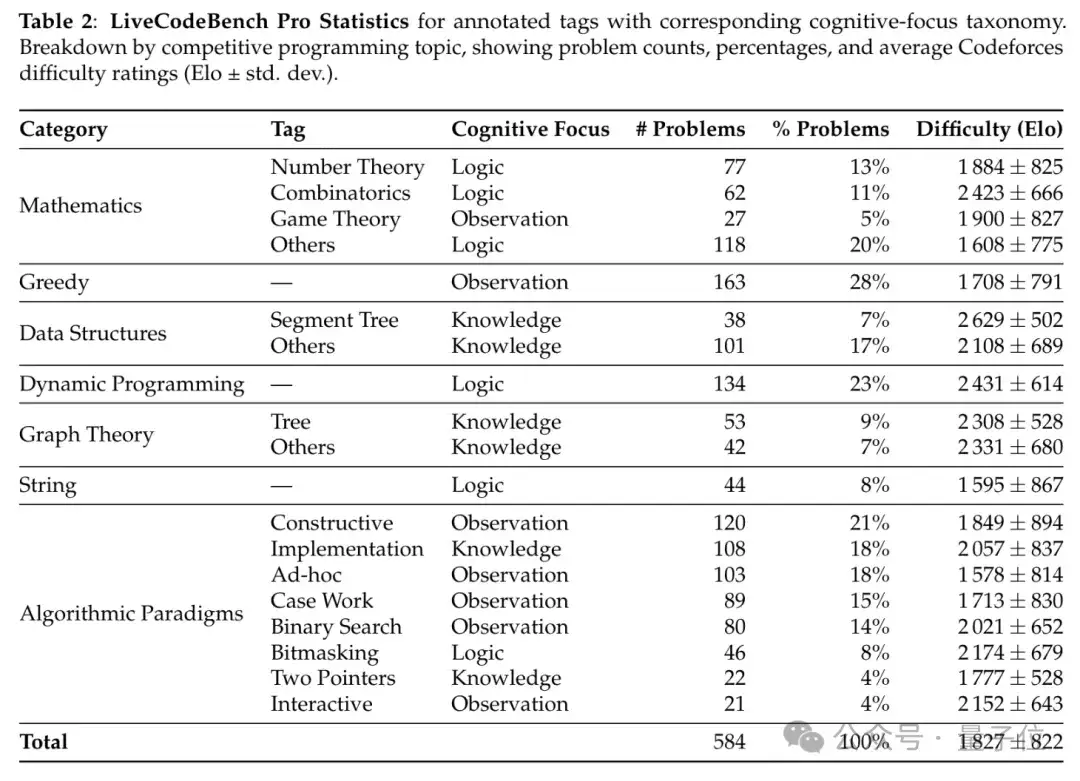
测试收录了584道顶流竞赛题,团队手动对每个问题进行标注,标注内容包括解决每个任务所需的关键技能,并根据问题的认知焦点将题目分为知识密集型、逻辑密集型和观察密集型三大类。
还将题目分为三个难度级别,这并非是人工挑选的,而是通过正态分布自动选择。
例如,所有Codeforces问题的评分在2000分以上的都会被归入困难等级。
模型具体表现
团队会基于题目背后的算法思想进行分类,记录Codeforces官方难度评级(对应Elo分数下50%的成功率),同时梳理关键观察点、常见陷阱及边缘案例,为评估提供多维度参考。
在测试过程中,团队对模型和人类专家提交的每个解决方案,记录其判定结果(如通过、答案错误、超时等),并标注根本原因(思路层面错误或实现层面错误)。
如果代码无法通过题目自带的样例输入输出,会标记 “样例未通过”。
结合题目分类与提交结果,对比人类专家的解题模式,分析模型在不同难度(简单 / 中等 / 困难)、题型(知识密集型 / 逻辑密集型 / 观察密集型)下的表现,定位模型在算法推理、样例利用及边缘案例处理等方面的短板。
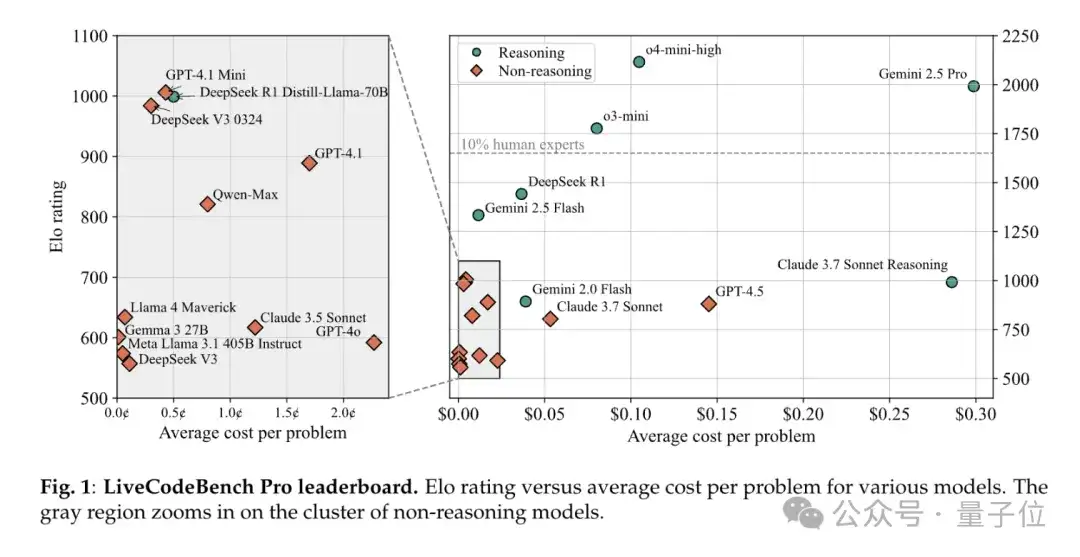
团队一共测试了22款大模型,并根据表现给出了完整榜单,大家可以自行查看任何一个模型在每一个问题上给出的解决方法。
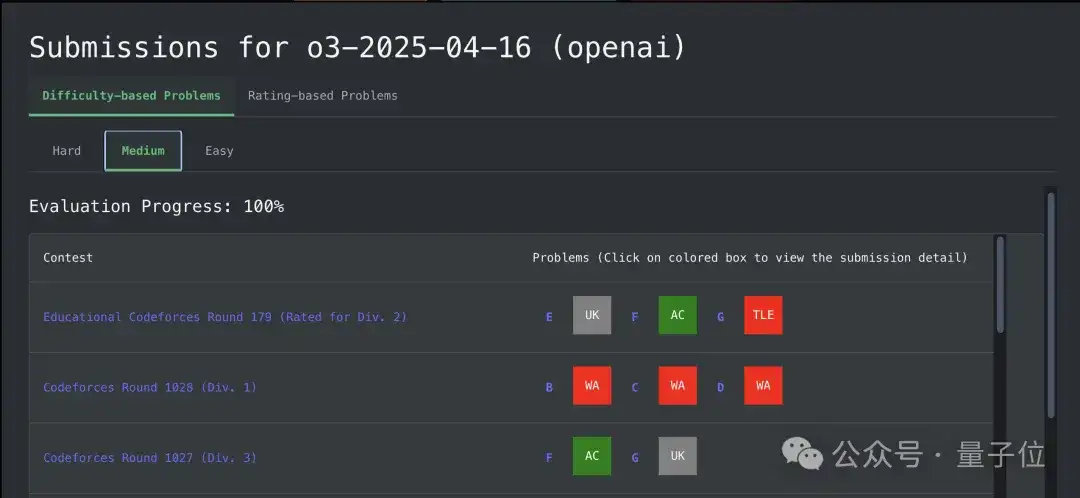
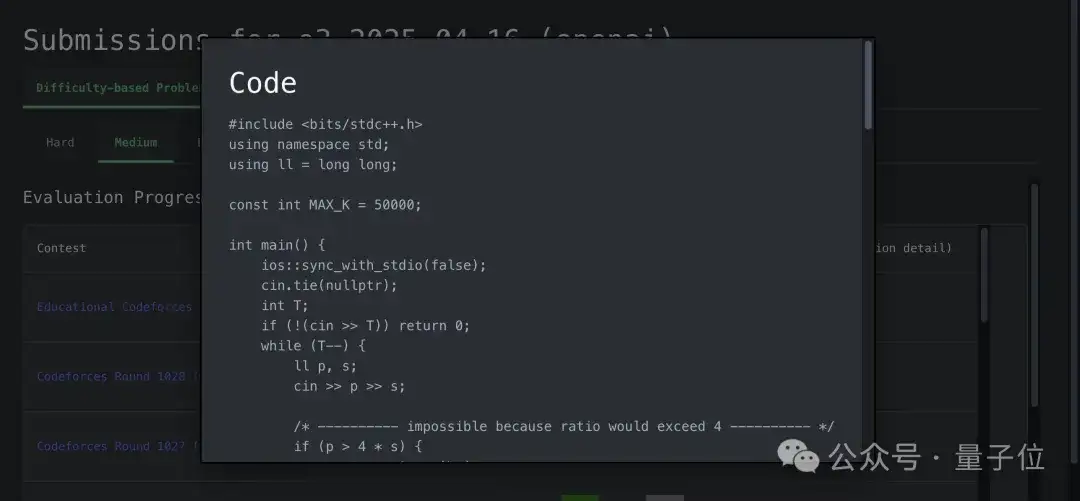
同时绘制了每一个模型的评分趋势,可供自由选择想要了解的模型。
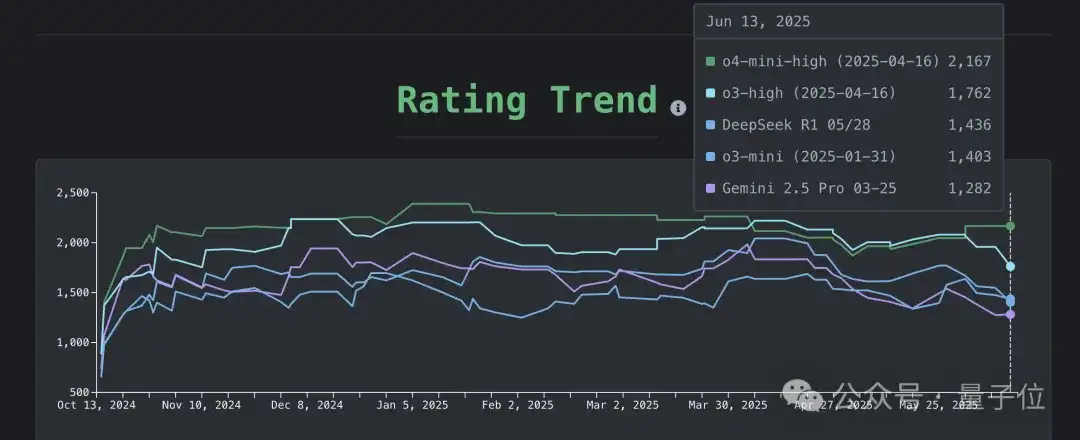
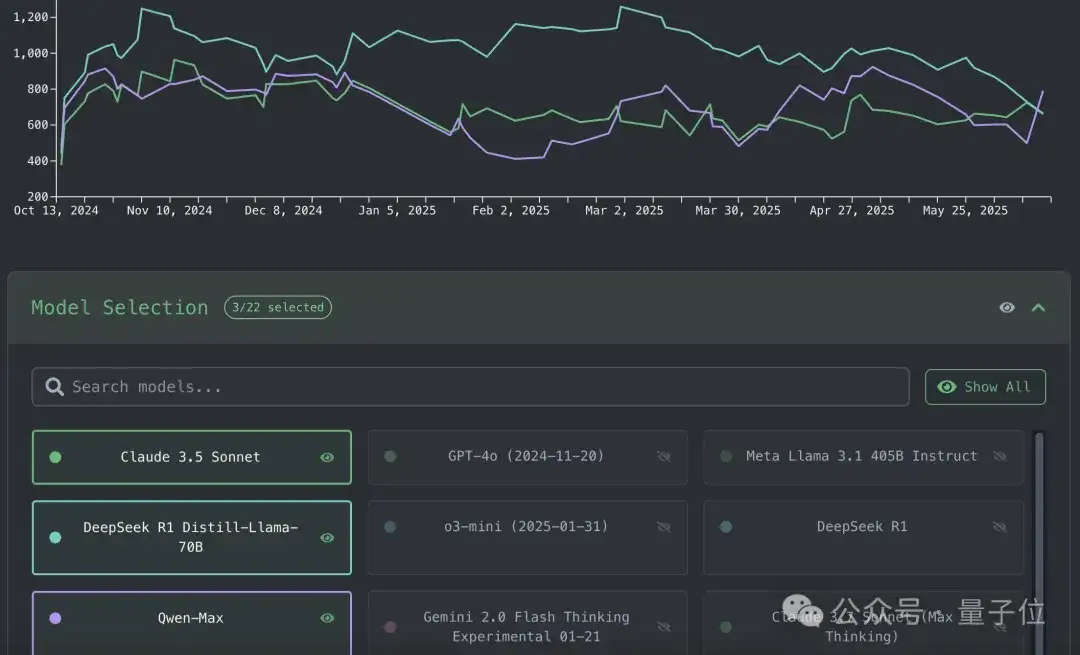
测试结果显示:
模型在知识密集型和逻辑密集型问题上表现更好,擅长 “死记硬背”(如数据结构模板),但在观察密集型问题或案例工作中表现较差,搞不定 “灵光一现” 的贪心、博弈题。
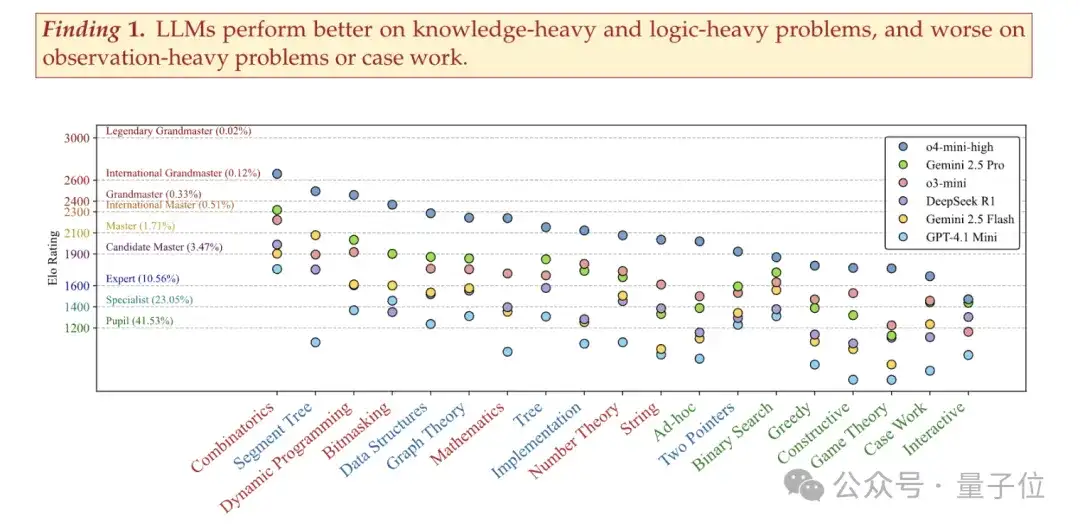
与人类相比,o3-mini 等模型在精确、无错误的实现方面展现出更高级的技能,但在算法设计方面逊色。
LLMs擅长实现类问题,但在需要精细算法推理和复杂案例分析的题目上表现欠佳,还常给出看似正确实则错误的解释。
LLMs经常无法正确通过题目提供的示例输入,显示其对给定信息的利用不充分。

LLMs很大程度上依赖工具增强(如终端访问、网络搜索),而非自身推理能力。
团队还增加了尝试次数(pass@k),并发现这样可以显著提升LLMs在中简单题的表现,但对难题依旧无力。
比如,通过增加o3-high模型的尝试次数来测试其性能,但无论尝试多少次,它仍然无法解决任何一个困难分区的题目。
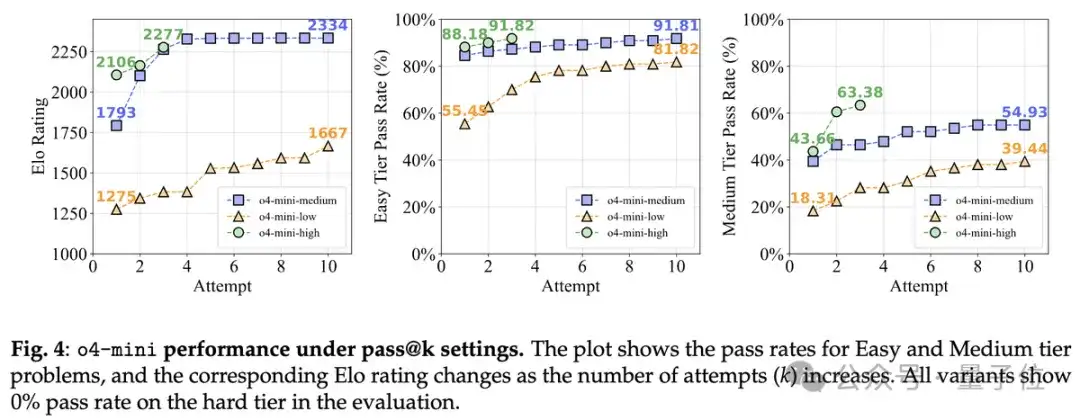
启用推理功能后,LLMs在组合数学等知识密集型题目中提升明显,但在观察密集型题目中提升有限。
研究员还透露,每个季度,团队都将发布一个完全全新的评估集,保证数据的时效性。

团队超半数成员为华人
LiveCodeBench Pro团队由一众奥林匹克竞赛得奖者组成,其中超半数成员为华人。
该项目的主要负责人郑子涵毕业于成都外国语学校,现于纽约大学本科在读,曾代表纽约大学参加ICPC世界总决赛,获得第二名。
他先后在腾讯、英伟达担任研发实习生,今年2月份以实习生的身份进入OpenAI。

另一位负责人柴文浩于2023年在浙江大学完成本科学业,硕士就读于华盛顿大学,今年9月将前往普林斯顿大学计算机科学专业就读博士。
他曾于Pika Labs和微软亚洲研究院实习,先前研究主要涉及视频理解和生成模型。
他领导开发了MovieChat,这是第一个用于长视频理解的超大多模态模型。
并且,他在ICLR、CVPR、ICCV等顶会期刊发表过相关研究论文。

该项目的其他参与者分别来自加州大学、普林斯顿大学等,这是一支非常年轻的队伍。
论文地址:https://arxiv.org/abs/2506.11928
项目地址:https://github.com/GavinZhengOI/LiveCodeBench-Pro
排行榜:https://livecodebenchpro.com/
参考链接:
[1]https://x.com/ZihanZheng71803/status/1934780656665677928
[2]https://x.com/rohanpaul_ai/status/1934751145400111572
[3]https://x.com/sainingxie/status/1934786355969851630
文章来自公众号“量子位”,作者“闻乐”



