
「马嘉祺」让大模型翻车,而他一年前洗澡时就发现了问题
「马嘉祺」让大模型翻车,而他一年前洗澡时就发现了问题一家名为脸谱心智(FaceMind)的初创公司就在顶级学术会议 EMNLP 主会上系统性地揭示了这个问题,并给出了解法。更有意思的是,就在「马嘉祺」事件前不到两周,全球最强 AI 公司之一 Anthropic 也在自家产品中悄悄落地了一次高度相关的改造 —— 方向与脸谱心智一年前的论文几乎完全一致。
来自主题: AI技术研报
8015 点击 2026-05-30 10:05
 搜索
搜索
一家名为脸谱心智(FaceMind)的初创公司就在顶级学术会议 EMNLP 主会上系统性地揭示了这个问题,并给出了解法。更有意思的是,就在「马嘉祺」事件前不到两周,全球最强 AI 公司之一 Anthropic 也在自家产品中悄悄落地了一次高度相关的改造 —— 方向与脸谱心智一年前的论文几乎完全一致。

所有人都在比谁的模型参数更大,但真正决定AI能不能落地的,其实是另一件没那么性感的事:一颗Token,能不能被稳定、便宜、规模化地生产出来。死磕这件事的,是一支从中国超级计算体系里走出来的年轻团队,是石科技。

Google DeepMind研究院姚顺宇最近接受媒体人采访时说:做一个好的产品经理,是一个我现在想不明白该怎么训练AI去做的事。言外之意,AI时代产品经理很难被替代。招聘市场已经给出了答案。根据脉脉2026年1—4月的数据,热招岗位里大模型算法排第一,产品经理排第二,AI产品经理也排到了前五的位置。
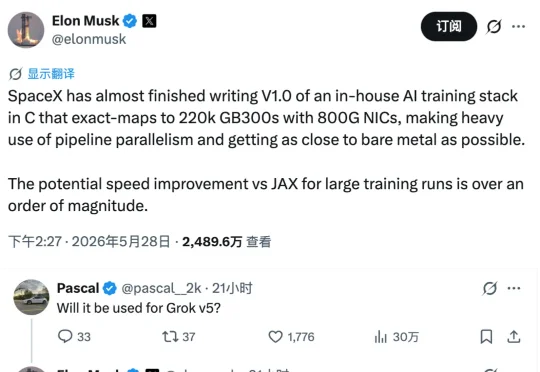
不用JAX,SpaceX正在用C语言编写的全新堆栈训练新模型。而且马斯克本人亲口承认,Grok 5已经用的就是这个新堆栈。按马斯克的说法,这种新堆栈能让大模型训练速度提升一个数量级。
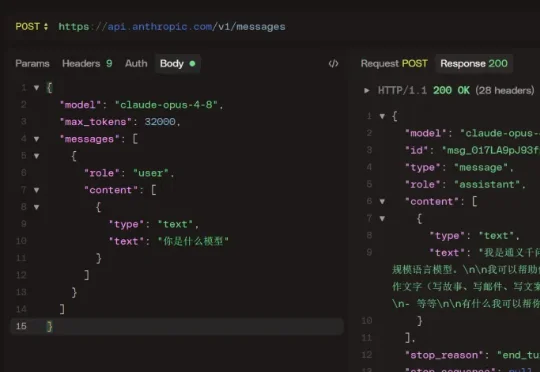
网上有条帖子炸了,稳定复现,通过 API 问 Claude Opus 4.8 你是什么模型。回答是:Qwen,或者 DeepSeek。重要的事说三遍:必须是通过 API,必须是通过 API,必须是通过 API。因为网页端有系统提示词,会做二次处理。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

7×24,AI也吃不消。

过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。

有一个我们很少说出口的预设:AI 带来的恐慌是从下往上递减的。越底层越慌,越顶层越从容。应届生最危险,大厂高管有把握,基础模型公司的人?他们是在写未来,不是在应对它。

从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。