
李飞飞、Jeff Dean押注!不卷大模型,专练越用越聪明的AI
李飞飞、Jeff Dean押注!不卷大模型,专练越用越聪明的AI卷更大的模型,不再是唯一答案。新问题是模型能不能在真实场景中越用越聪明。一家叫Trajectory的公司押注这一趋势,要把Cursor的成功秘密做成AI新基建。
来自主题: AI资讯
10591 点击 2026-06-01 14:59
 搜索
搜索
卷更大的模型,不再是唯一答案。新问题是模型能不能在真实场景中越用越聪明。一家叫Trajectory的公司押注这一趋势,要把Cursor的成功秘密做成AI新基建。

紧跟DeepSeek价格战,小米掏出技术底牌!

连续创业的 York 开启了又一段新征程。过去十几年里,他几乎一直在做软硬一体系统:从计算机视觉、嵌入式,到后来的机器人。他的上一个创业项目——智能购物车 Caper AI,在 2021 年被 Instacart 以 3.5 亿美元收购。
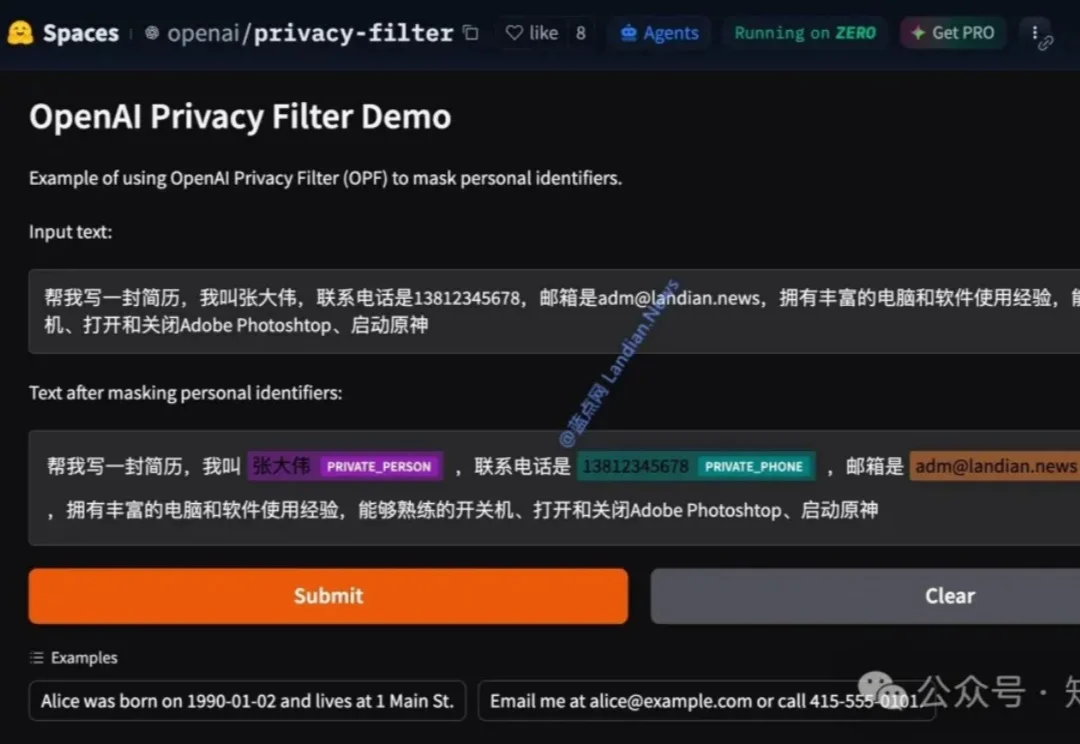
你有没有过这样的经历:把聊天记录、用户反馈或内部文档丢给大模型时,总担心里面夹杂着真实姓名、手机号、邮箱甚至 API key,最后只能手动一条条删?或者团队在处理海量数据时,规则写的正则永远漏掉那些“藏在句子里的隐私”。

从大模型的提示词到智能体的 Skills,看着进化了,但又没有完全进化。
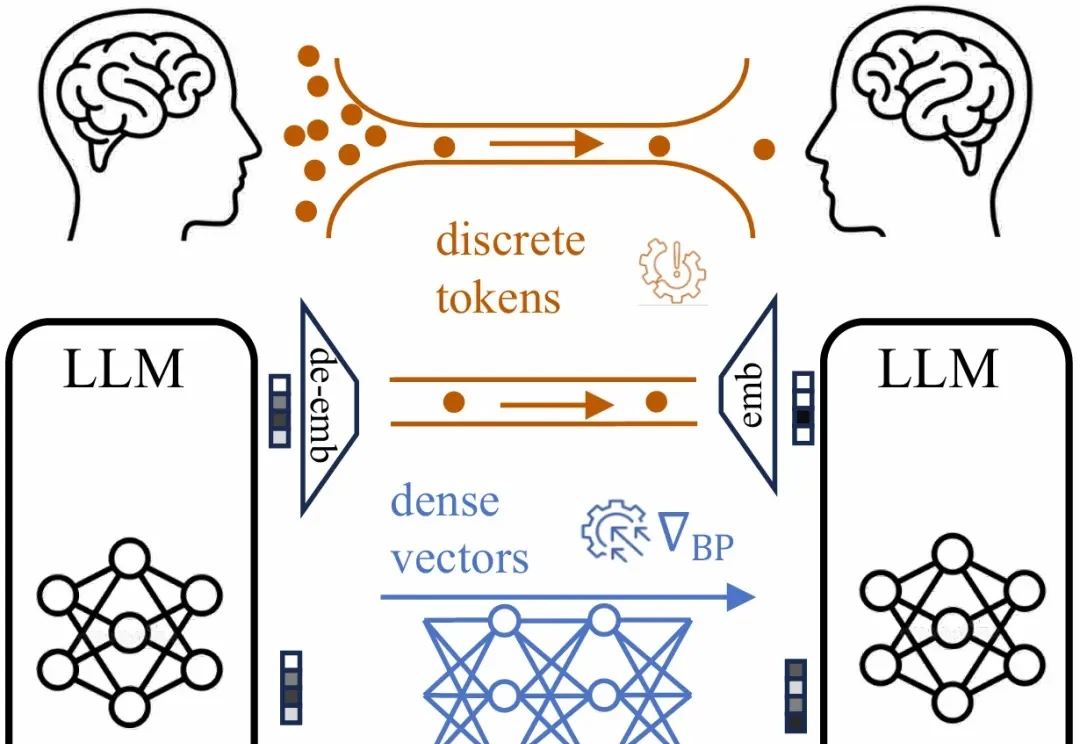
大语言模型正在成为人工智能系统的核心组件。从文本生成、数学推理到代码编写,单个大模型已经展现出强大的能力。
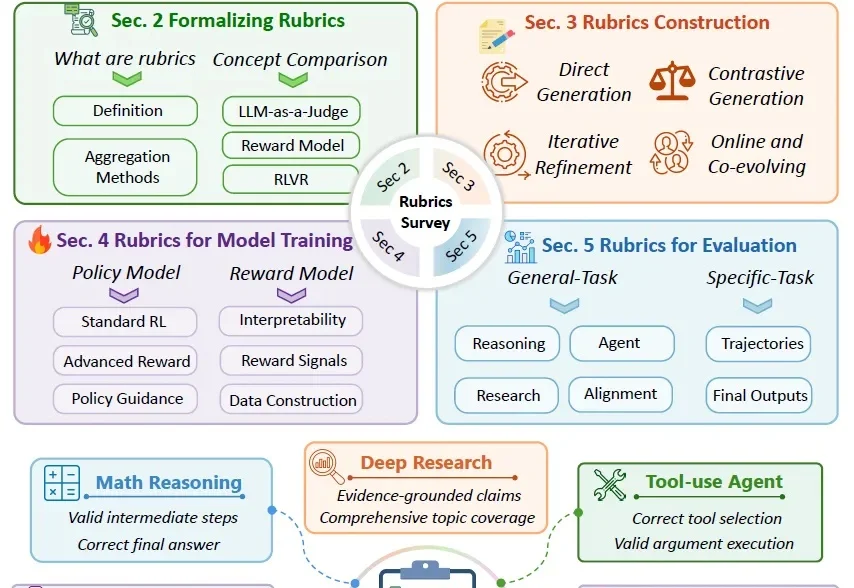
近年来,随着大模型从简单问答,走向深度研究、医疗咨询、多模态生成和长程 Agent 任务,一个基础问题变得越来越难回答:我们到底应该怎样判断模型输出的质量?

大模型从“回答问题”走向“完成任务”,正在面临以下瓶颈:面向Claw Agents的数据、训练和评测都比传统environment training更难。为了解决该问题,中国人民大学、至知研究院等最新提出ClawGym——

证监会官网显示,上海AI大模型龙头企业MiniMax已于5月29日向上海证监局提交了上市辅导备案报告,开启A股上市进程,中信证券担任辅导机构。这也意味着,MiniMax将与已经提交A股上市辅导备案的智谱,一同冲刺A股大模型第一股。

昨天,大名鼎鼎的 Claude 4.8 发布了。 科技圈照例是一片欢呼。 看官方放出来的一堆评测数据,依然是碾压级别的,尤其是说代码(Coding)能力有了史诗级的提升,简直像交了一份满分答卷。