

数十亿美元!传亚马逊又要投资Anthropic,但有一个条件
数十亿美元!传亚马逊又要投资Anthropic,但有一个条件智东西11月8日消息,据外媒The Information报道,亚马逊正讨论向美国AI大模型独角兽Anthropic进行第二笔数十亿美元的投资。
来自主题: AI资讯
4183 点击 2024-11-09 09:48
智东西11月8日消息,据外媒The Information报道,亚马逊正讨论向美国AI大模型独角兽Anthropic进行第二笔数十亿美元的投资。

继金融后,央国企成了AI大模型先锋官

能够深入大模型内部的新评测指标来了! 上交大MIFA实验室提出了全新的大模型评估指标Diff-eRank。 不同于传统评测方法,Diff-eRank不研究模型输出,而是选择了分析其背后的隐藏表征。

前些时日,AI 大模型开始掌握操作计算机的能力,但整体而言,它们与物理世界互动的能力仍处于早期阶段。
自从 Sora 横空出世,业界便掀起了一场「视频生成模型到底懂不懂物理规律」的争论。图灵奖得主 Yann LeCun 明确表示,基于文本提示生成的逼真视频并不代表模型真正理解了物理世界。之后更是直言,像 Sora 这样通过生成像素来建模世界的方式注定要失败。

近日,蓝鲸新闻记者独家获悉,大模型赛道初创公司边塞科技近日被收购,收购方可能为某大厂,边塞科技曾在天使轮获真格基金投资。边塞科技也成为了国内第二家被收购的AI公司。

消除激活值(outliers),大语言模型低比特量化有新招了—— 自动化所、清华、港城大团队最近有一篇论文入选了NeurIPS 2024(Oral Presentation),他们针对LLM权重激活量化提出了两种正交变换,有效降低了outliers现象,达到了4-bit的新SOTA。
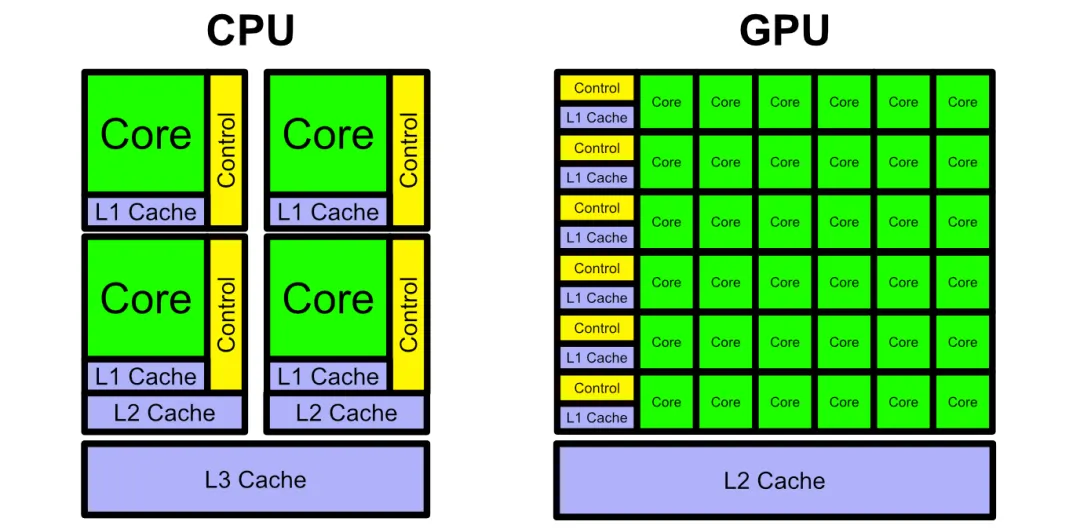
卖铲子相比蜂拥去淘金,永远是更好的选择。在大模型风靡全球、蕴含极大商业价值的今天,「先进铲子」之间的竞赛,正趋向白热化。

最近,以 OpenAI o1 为代表的 AI 大模型的推理能力得到了极大提升,在代码、数学的评估上取得了令人惊讶的效果。OpenAI 声称,推理可以让模型更好的遵守安全政策,是提升模型安全的新路径。

现在正是多模态大模型的时代,图像、视频、音频、3D、甚至气象运动都在纷纷与大型语言模型的原生文本模态组合。而浙江大学及其计算机创新技术研究院的一个数十人团队也将结构化数据(包括数据库、数仓、表格、json 等)视为了一种独立模态。