性能碾压谷歌!5000亿美元巨头开源最强端侧医疗AI,背后藏着一家中国企业!
性能碾压谷歌!5000亿美元巨头开源最强端侧医疗AI,背后藏着一家中国企业!一家估值超5000亿美元的币圈富豪公司,秀出了性能碾压谷歌的AI医疗大模型。
来自主题: AI资讯
7695 点击 2026-05-13 10:48
 搜索
搜索
一家估值超5000亿美元的币圈富豪公司,秀出了性能碾压谷歌的AI医疗大模型。

谷歌周一发布报告,首次确认犯罪黑客使用AI大模型发现了一个此前未知的零日漏洞,并差点发动大规模攻击。这件事之所以炸裂,是因为安全界担心了好几年的「AI自动挖洞」,终于从理论变成了现实。而在Anthropic的Mythos模型已经找到数千个零日漏洞的背景下,这可能只是冰山一角。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。

AI再也不是“回合制”了。Thinking Machines Lab(以下简称TML)发布首个模型,让实时交互能力成为模型原生能力。联合创始人翁荔出镜演示。
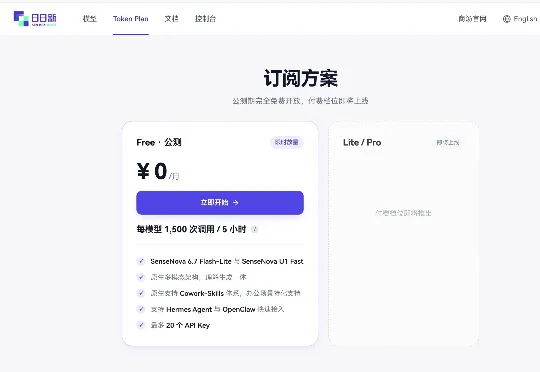
商汤最近做了一件大多数大模型公司都不舍得做的事。每 5 小时 1500 次免费调用,Token 消耗比同行低 60%,三款新产品同步上线,还把核心模型 U1 以 Apache 2.0 协议全面开源——在大模型公司普遍在想怎么收费的当下,商汤在反向操作。

2011年,Marc Andreessen写下“软件正在吞噬世界”。2026 年,Fortune用了一句话总结当前局面:“那个吃掉世界的东西,正在被吃掉。 ”

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
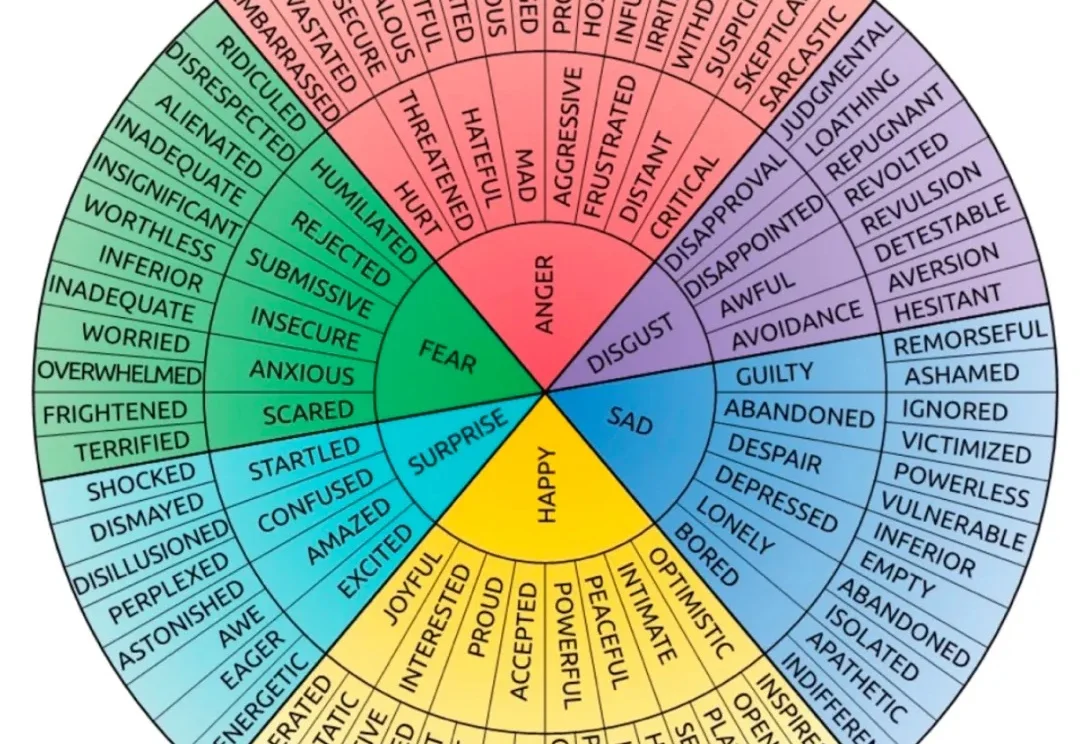
随着语音、视频、多模态能力不断融入大语言模型(LLM),人与 AI 的交互正在越来越接近自然对话。今天的 LLM 不再只是回答问题的工具,也越来越多地出现在教育、客服、陪伴、心理健康等高度依赖情绪理解的场景中。

当 AI 开始加速 AI,模型公司的迭代周期正在被进一步压缩,模型公司开始进入“月更时代”。

快手计划分拆旗下视频生成大模型业务可灵 AI,以 200 亿美元估值融资——截至今天港股收盘,整个快手公司目前的市值不到 290 亿美元。可灵当前的年化收入(ARR)已经达到 5 亿美元,已比春节前翻倍。